Baixar para ler offline





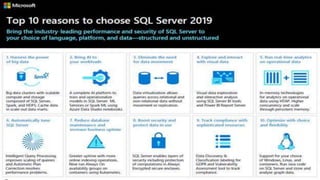


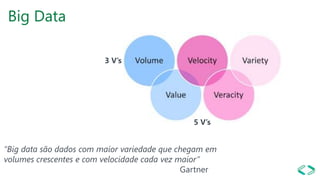

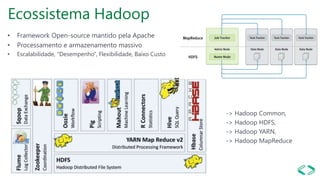
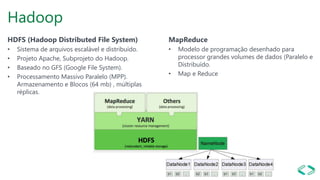







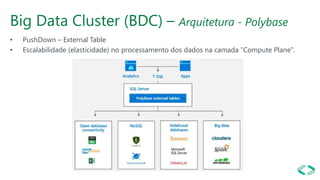
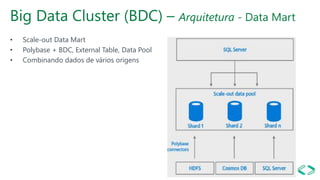
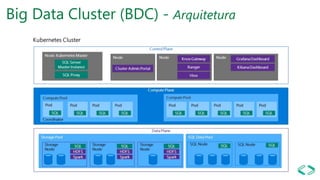
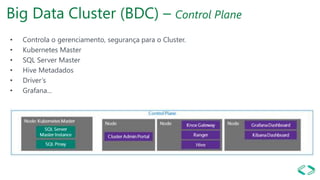

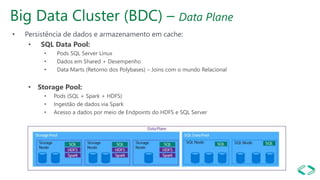
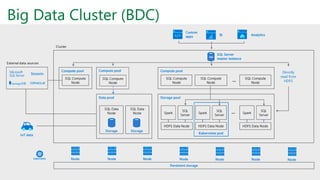





SQL Server 2019 introduz o Big Data Cluster, permitindo implantar clusters escalonáveis de contêineres SQL Server, Spark e HDFS em execução no Kubernetes. O Big Data Cluster integra dados estruturados e não estruturados através do PolyBase e permite processamento distribuído de grandes volumes de dados. A arquitetura do Big Data Cluster separa os planos de controle, computação e armazenamento de dados para gerenciar e processar dados de forma escalável.




















































