Baixar para ler offline




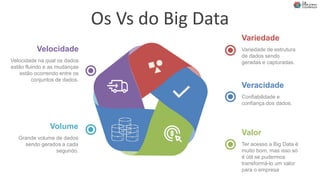
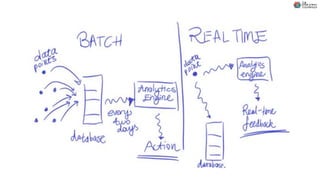


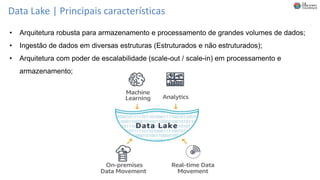
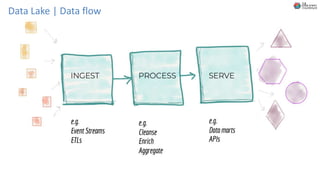
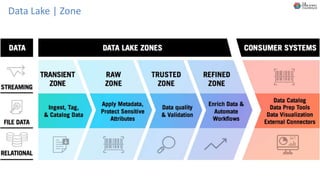
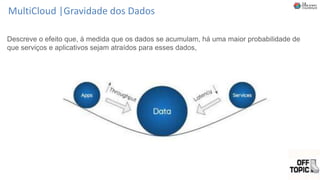
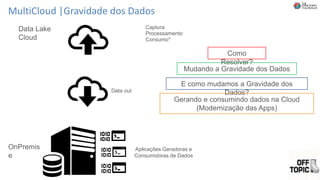


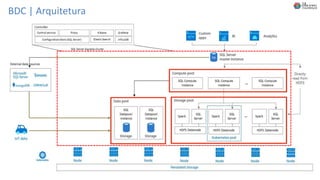
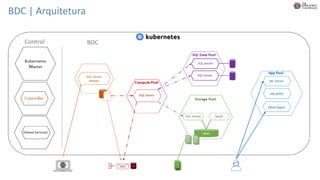
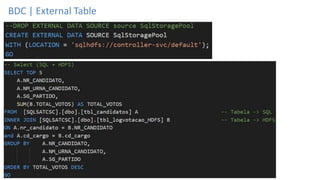

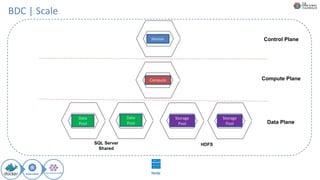
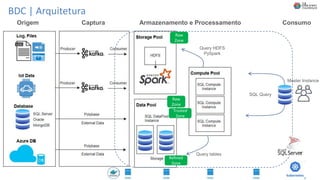
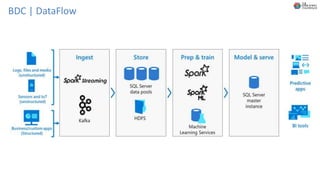



O documento discute Planejando Data Lake com Big Data Clusters. Explica o que é Big Data e os Vs do Big Data. Também define o que é um Data Lake e suas principais características. Por fim, descreve o que são Big Data Clusters, sua arquitetura e como podem ser usados para criar pipelines de dados e ambientes para IA/ML, processando dados de forma escalável.






































![[DTC21] André Marques - Jornada do Engenheiro de Dados](https://cdn.slidesharecdn.com/ss_thumbnails/jornadadoengenheirodedados-210317153718-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DTC21] Lucas Gomes - Do 0 ao 100 no Big Data](https://cdn.slidesharecdn.com/ss_thumbnails/dtc21lucasgomes-do0ao100embigdata-210316214734-thumbnail.jpg?width=640&height=640&fit=bounds)










