Transferir como PDF, PPTX













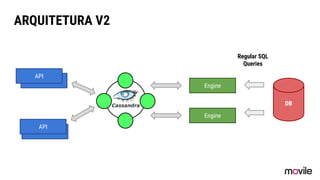
![Apache Cassandra é um banco de dados
não relacional (NoSQL) orientado a colunas, distribuído,
escalável, de alta disponibilidade, tolerante a falhas.
[The Definitive Guide, Eben Hewitt, 2010]](https://image.slidesharecdn.com/qconsp16apachecassandraevoluindosistemasdistribuidos-160405131918/85/QConSP16-Apache-Cassandra-Evoluindo-Sistemas-Distribuidos-13-320.jpg)





























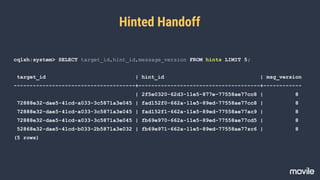
![Hinted Handoff
ERROR [HintedHandoff:1] 2015-08-31 18:31:55,600 CassandraDaemon.java:182 - Exception in thread Thread
[HintedHandoff:1,1,main]
java.lang.IndexOutOfBoundsException: null
at java.nio.Buffer.checkIndex(Buffer.java:538) ~[na:1.7.0_79]
at java.nio.HeapByteBuffer.getLong(HeapByteBuffer.java:410) ~[na:1.7.0_79]
at org.apache.cassandra.utils.UUIDGen.getUUID(UUIDGen.java:106) ~[apache-cassandra-2.2.0.jar:2.2.0]
at org.apache.cassandra.db.HintedHandOffManager.scheduleAllDeliveries(HintedHandOffManager.java:515)
~[apache-cassandra-2.2.0.jar:2.2.0]
at org.apache.cassandra.db.HintedHandOffManager.access$000(HintedHandOffManager.java:88) ~[apache-
cassandra-2.2.0.jar:2.2.0]
at org.apache.cassandra.db.HintedHandOffManager$1.run(HintedHandOffManager.java:168) ~[apache-
cassandra-2.2.0.jar:2.2.0]
at org.apache.cassandra.concurrent.DebuggableScheduledThreadPoolExecutor$UncomplainingRunnable.run
(DebuggableScheduledThreadPoolExecutor.java:118) ~[apache-cassandra-2.2.0.jar:2.2.0]
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:471) [na:1.7.0_79]
at java.util.concurrent.FutureTask.runAndReset(FutureTask.java:304) [na:1.7.0_79]
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.access$301(ScheduledThread)
CASSANDRA-10233 - IndexOutOfBoundsException in HintedHandOffManager
CASSANDRA-10485 - Missing host ID on hinted handoff write](https://image.slidesharecdn.com/qconsp16apachecassandraevoluindosistemasdistribuidos-160405131918/85/QConSP16-Apache-Cassandra-Evoluindo-Sistemas-Distribuidos-56-320.jpg)





![Cassandra 1.2
ERROR [CompactionExecutor:6523] 2015-10-09 12:33:23,551
CassandraDaemon.java (line 191) Exception in thread
Thread[CompactionExecutor:6523,1,main]
java.lang.AssertionError: incorrect row data size3758096384 written to
/movile/cassandra-data/SBSPlatform/idx_config/SBSPlatform-idx_config-tmp-ic-715-Data.
db;
at org.apache.cassandra.io.sstable.SSTableWriter.append(SSTableWriter.java:162)
at org.apache.cassandra.db.compaction.CompactionTask.runWith(CompactionTask.java:
162)
at org.apache.cassandra.io.util.DiskAwareRunnable.runMayThrow(DiskAwareRunnable.
java:48)
at org.apache.cassandra.utils.WrappedRunnable.run(WrappedRunnable.java:28)
+3GB em 1 linha](https://image.slidesharecdn.com/qconsp16apachecassandraevoluindosistemasdistribuidos-160405131918/85/QConSP16-Apache-Cassandra-Evoluindo-Sistemas-Distribuidos-63-320.jpg)
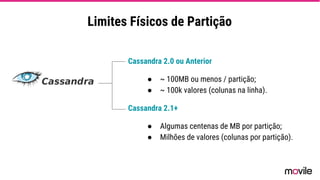




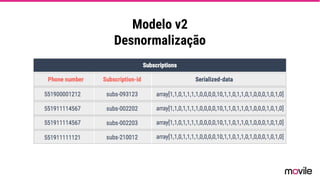







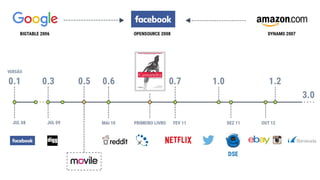
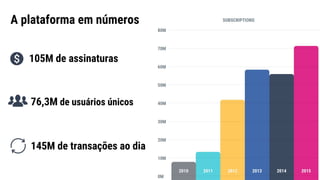
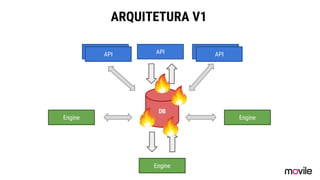
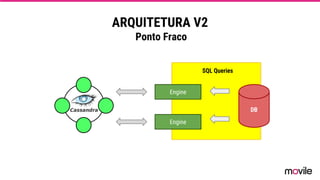
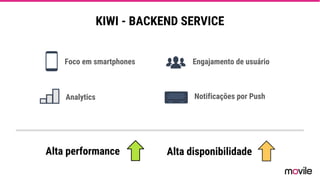
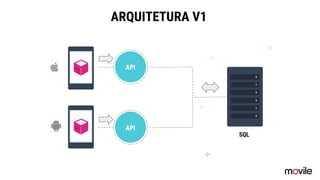
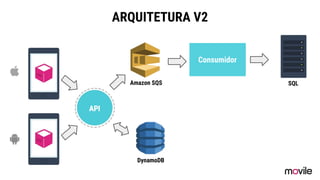
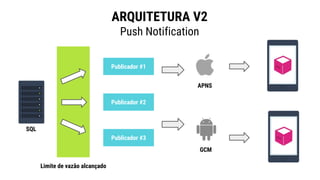
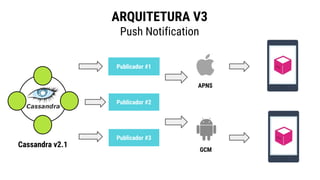
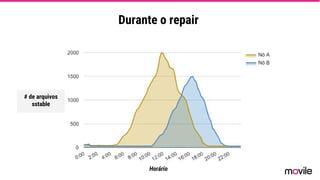
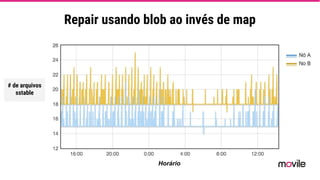
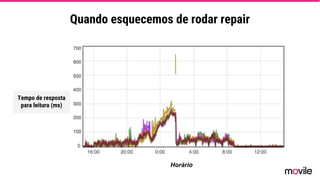
● O documento discute a evolução de sistemas distribuídos na Movile ao longo de 6 anos, começando com o uso do Apache Cassandra para controlar assinaturas e tarifações e, posteriormente, armazenar dados de aplicativos e notificações push. ● Problemas como desempenho, disponibilidade e escalabilidade levaram a mudanças na arquitetura, como a migração de bancos de dados relacionais para o Cassandra. ● Lições aprendidas incluem evitar coleções do Cassandra, reparos ap

![[TDC2016] Apache Cassandra Estratégias de Modelagem de Dados](https://cdn.slidesharecdn.com/ss_thumbnails/tdc2016-apachecassandraestrategiasdemodelagemdedados-160711163941-thumbnail.jpg?width=640&height=640&fit=bounds)

![[TDC2016] Apache SparkMLlib: Machine Learning na Prática](https://cdn.slidesharecdn.com/ss_thumbnails/tdc2016-apachesparkmllibmachinelearningnapratica-160711163948-thumbnail.jpg?width=640&height=640&fit=bounds)








![[DataFest-2017] Apache Cassandra Para Sistemas de Alto Desempenho](https://cdn.slidesharecdn.com/ss_thumbnails/datafest-apachecassandraparasistemasdealtodesempenho-170927104534-thumbnail.jpg?width=640&height=640&fit=bounds)




















































![[Datafest 2018] Apache Spark Structured Stream - Moedor de dados em tempo qua...](https://cdn.slidesharecdn.com/ss_thumbnails/datafest2018-apachesparkstructuredstreammoedordedadosemtempoquasereal-181101180406-thumbnail.jpg?width=640&height=640&fit=bounds)

