Baixar para ler offline


















![Amostra de Dados CSV (Gzipped)
838,2,5500000000,100015,"{""authCode"":""3215"",""transactionIdAuth"":""101170622042837
4938""}",SUBSCRIPTION_050,0.5,11,0,1,14,Subscription renew.,2017-07-18
13:22:59.518,,,19,PRE,false,Charge Fail. CTN[31984771092][PRE][GSM]: Without
Credit.,,,,0,458,,engine2dc2,23,3,5,2017-07-18
13:22:59.544,,FE1952B0-571D-11E7-8A17-CA2EE9B22EAB,NT0359
838,2,5500000000,100008,"{""authCode"":""9496"",""transactionIdAuth"":""117170703192540
9718""}",SUBSCRIPTION_099,0.99,11,0,1,14,Subscription renew.,2017-07-18
13:22:58.893,,,19,PRE,false,Charge Fail. CTN[21976504467][PRE][GSM]: Without
Credit.,,,,0,1074,,engine2dc2,24,3,5,2017-07-18
13:22:58.928,,3ADF36D0-6040-11E7-9619-A2D6E78E4511,NT0360
703,2,5500000000,100004,"{""authCode"":""6838"",""transactionIdAuth"":""118170706120694
8526""}",SUBSCRIPTION_299,2.99,11,0,1,14,Subscription renew.,2017-07-18
13:22:59.246,,,19,PRE,false,Charge Fail. CTN[84994640470][PRE][GSM]: Without
Credit.,,,,0,748,,engine2dc2,24,3,5,2017-07-18 13:22:59.254, NT0299](https://image.slidesharecdn.com/datafest2018-apachesparkstructuredstreammoedordedadosemtempoquasereal-181101180406/75/Datafest-2018-Apache-Spark-Structured-Stream-Moedor-de-dados-em-tempo-quase-real-34-2048.jpg)







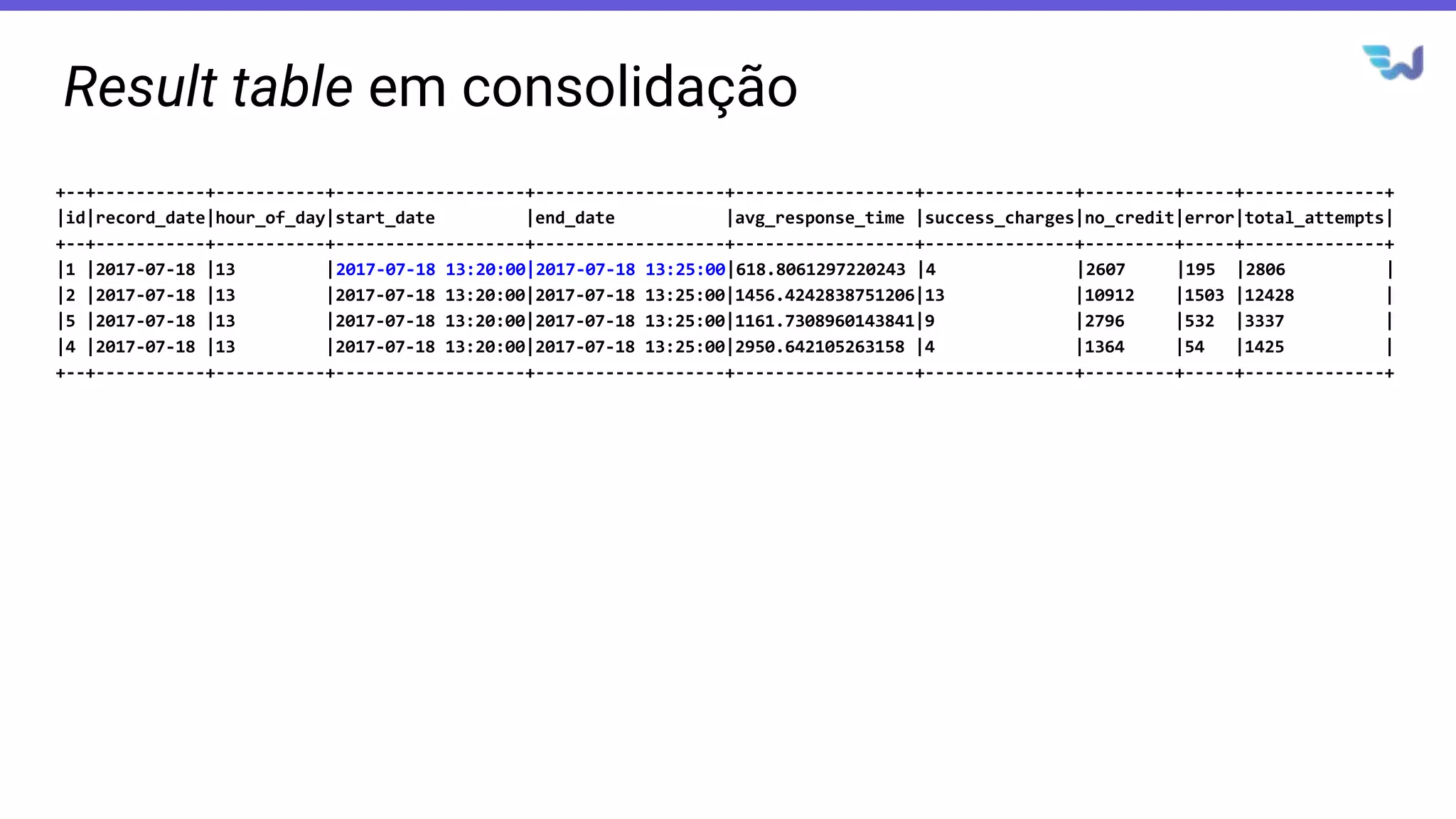
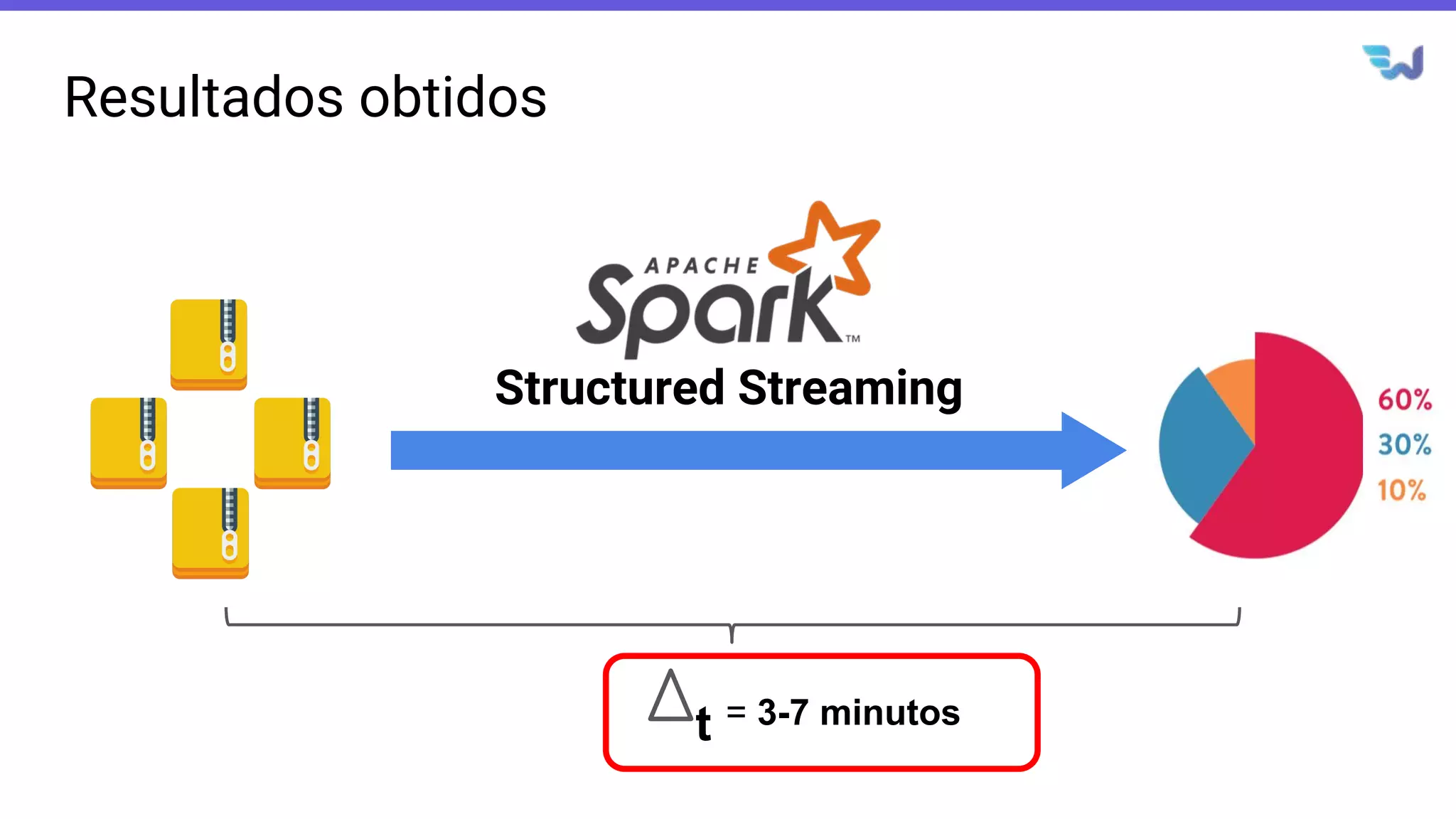



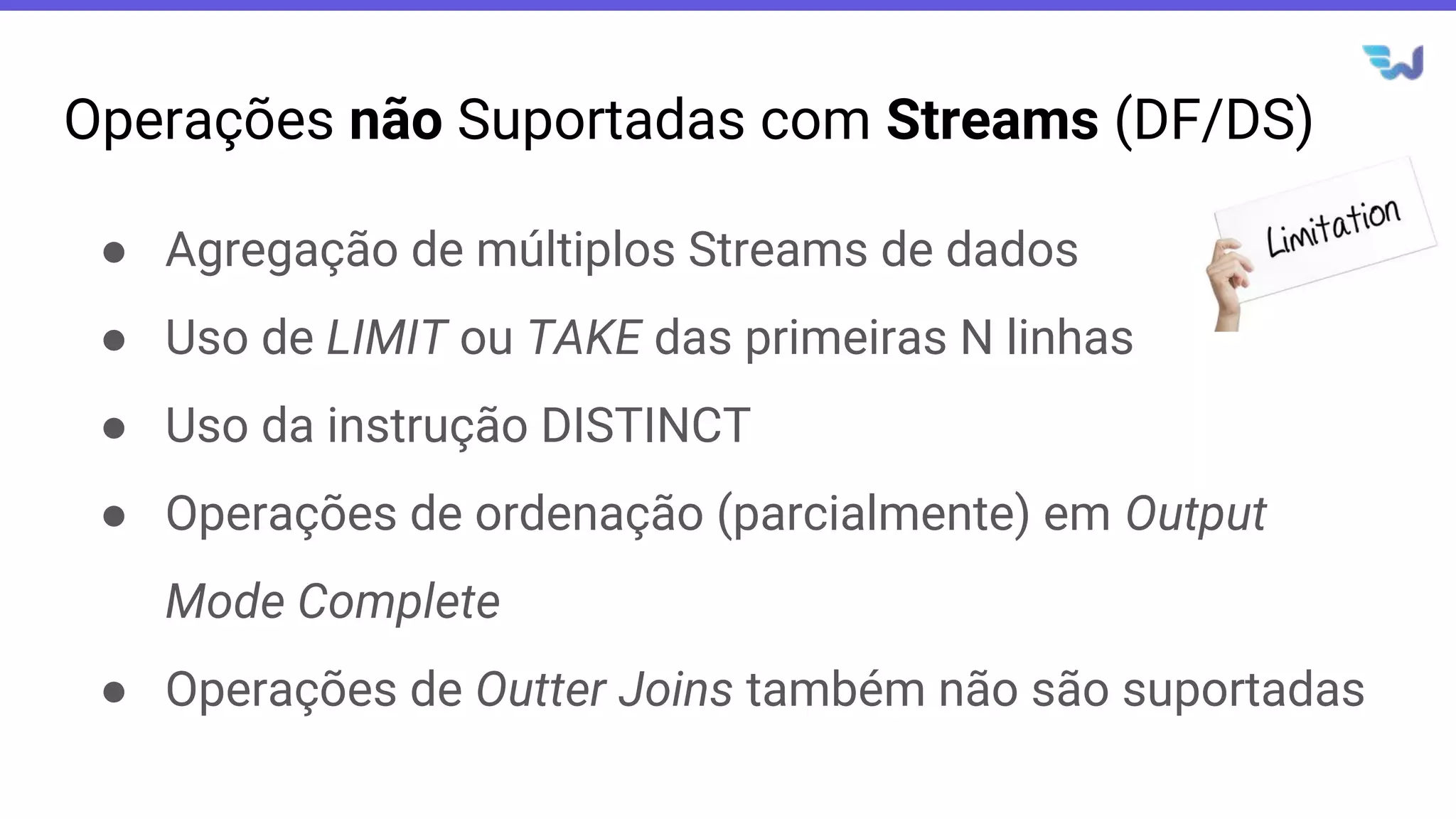


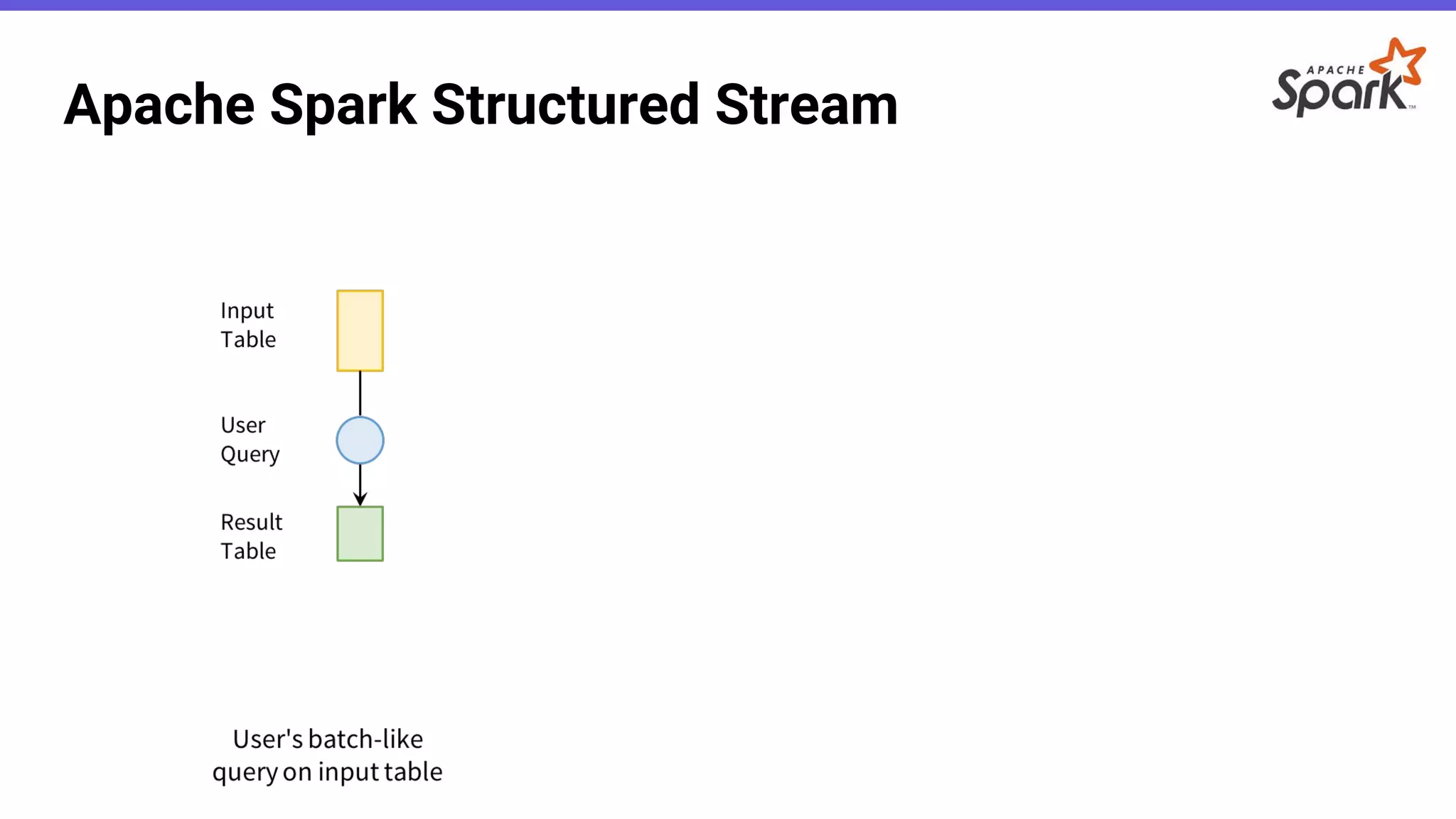
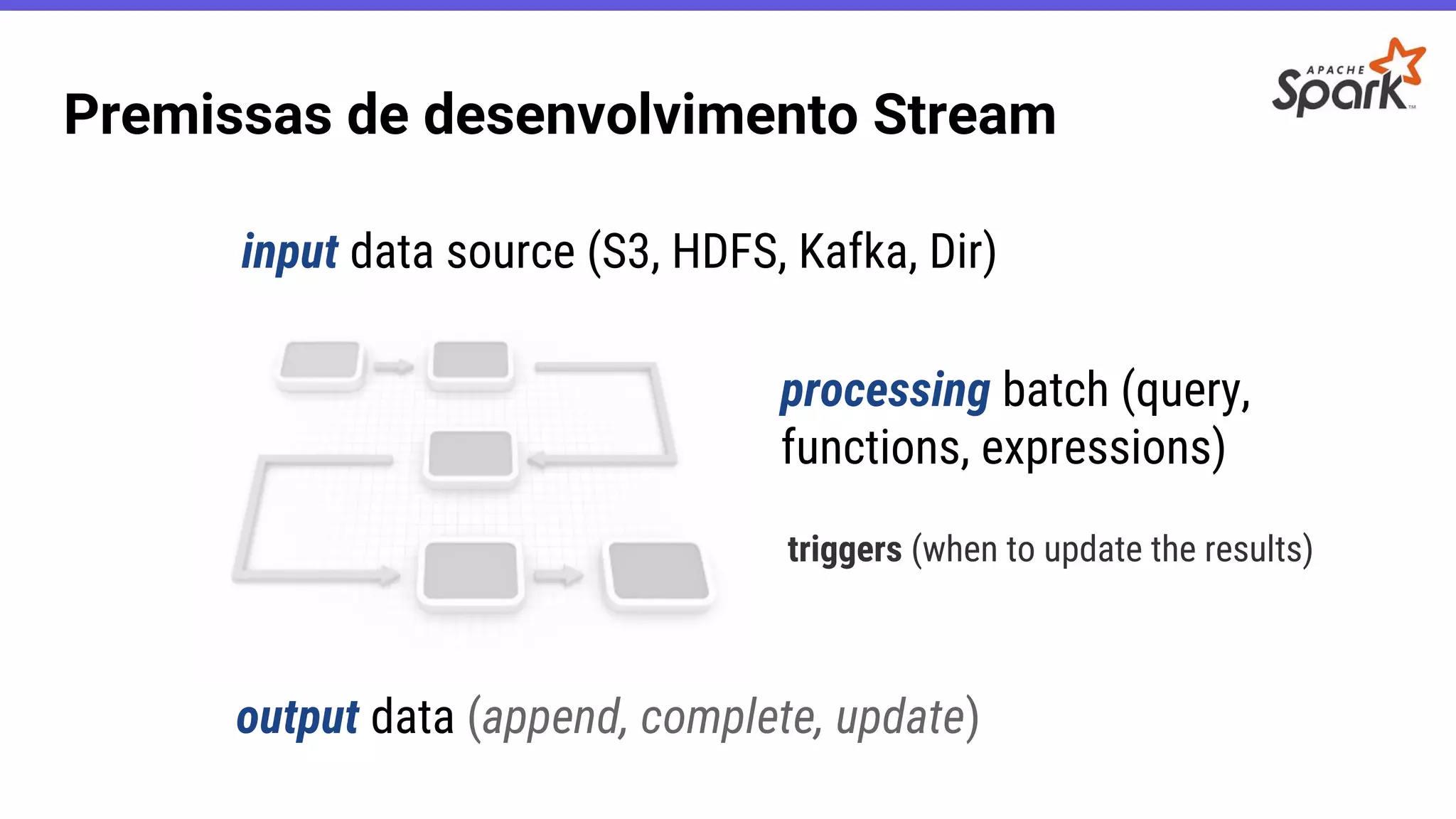
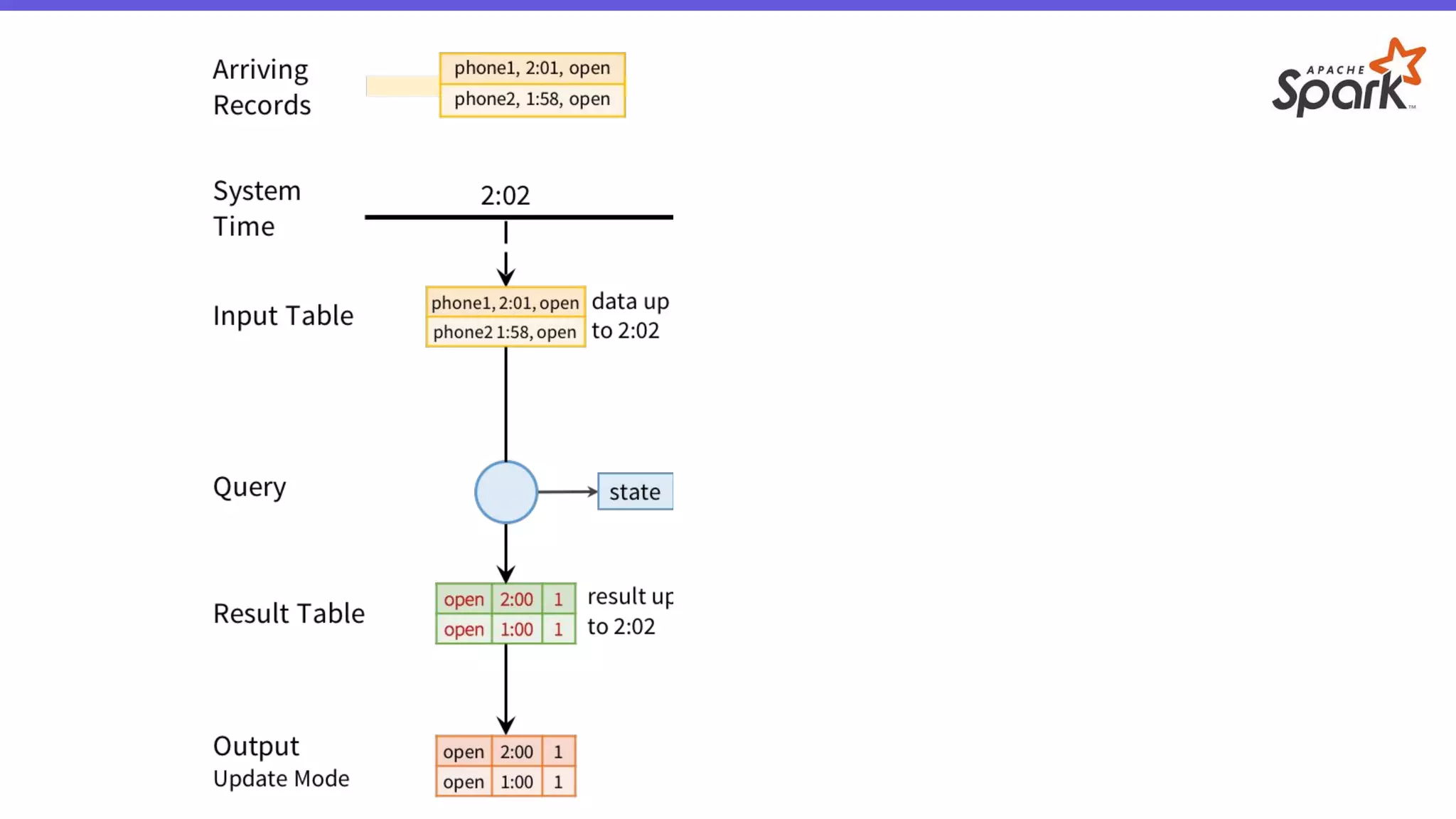
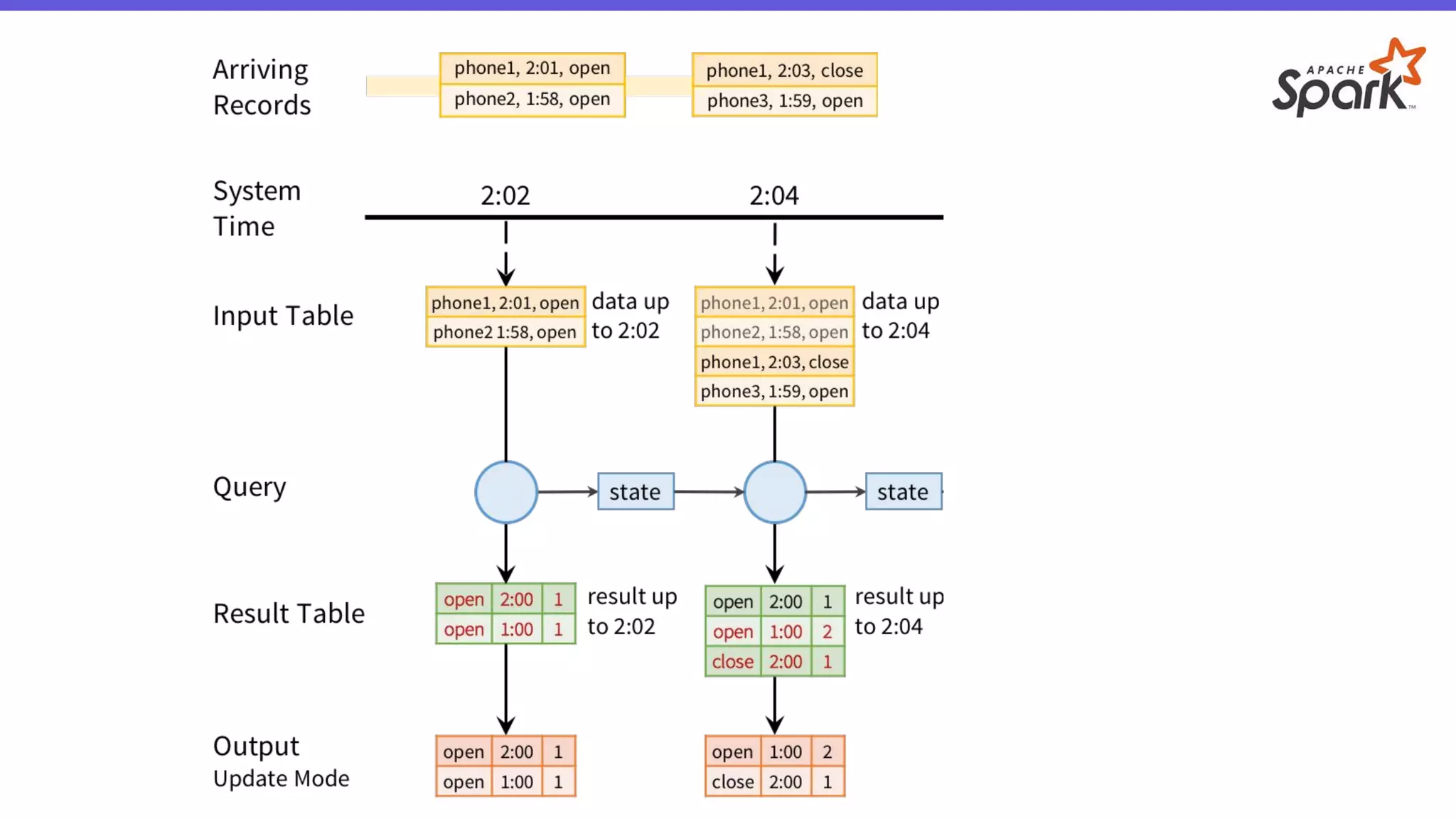
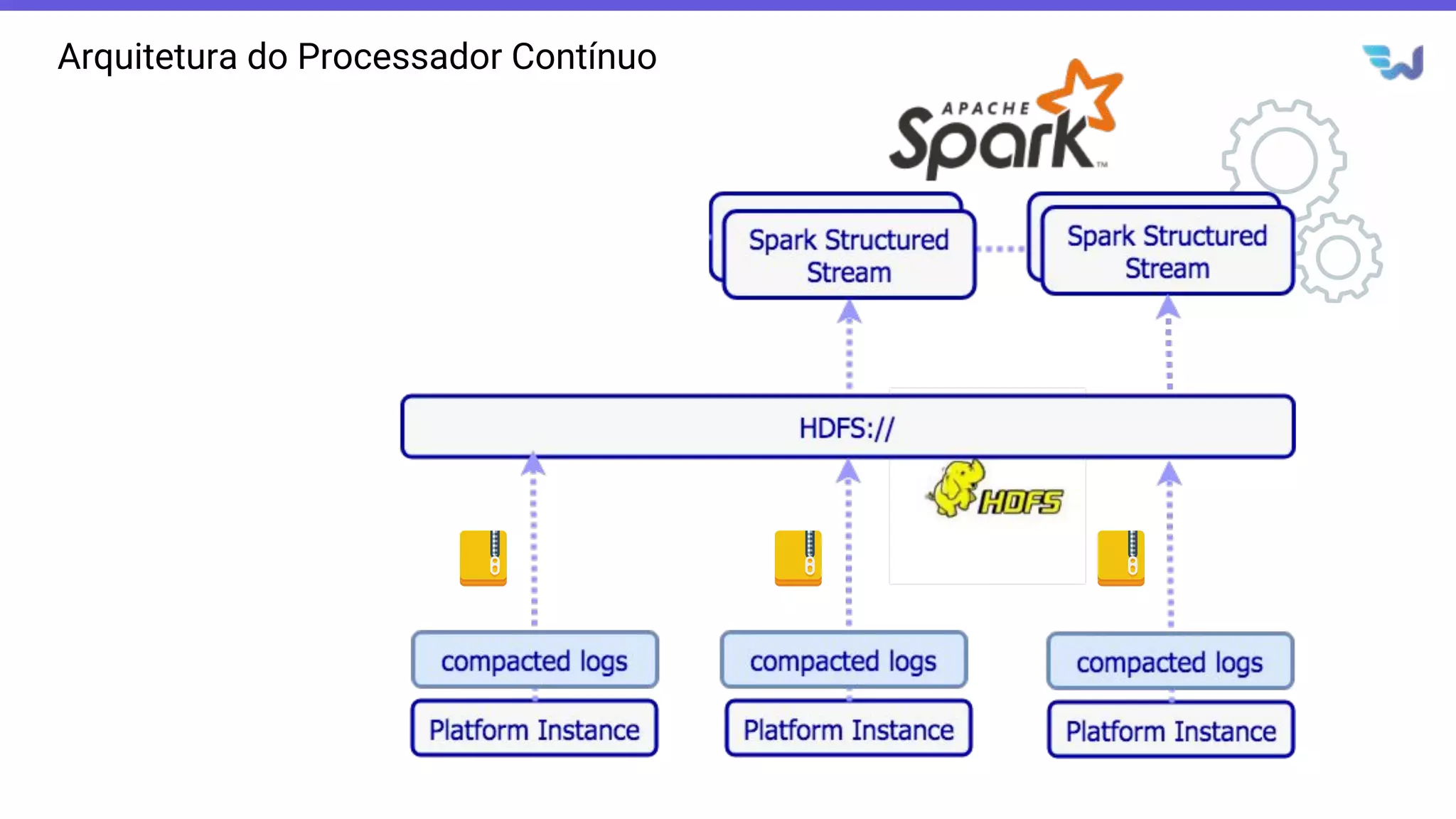
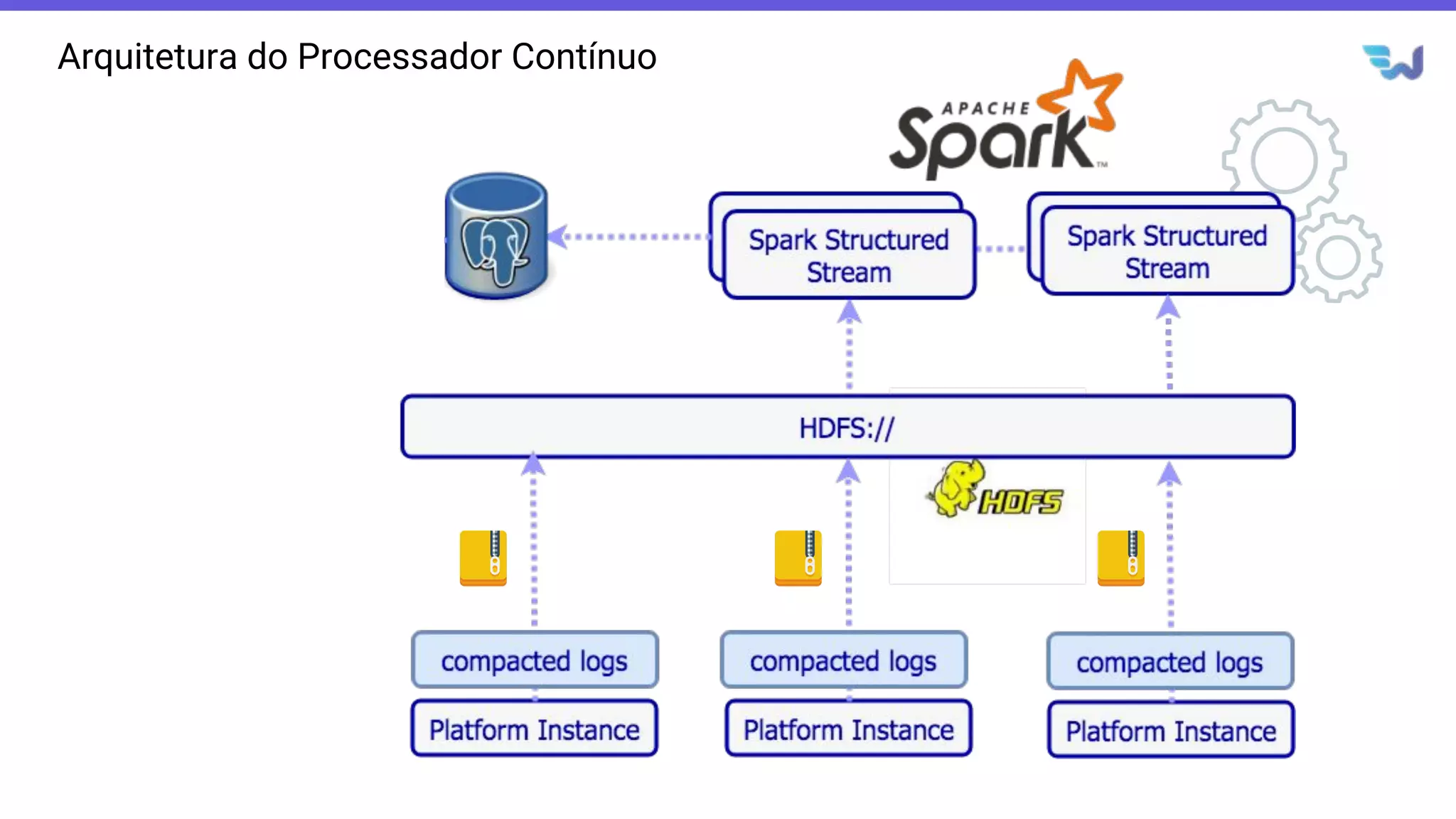
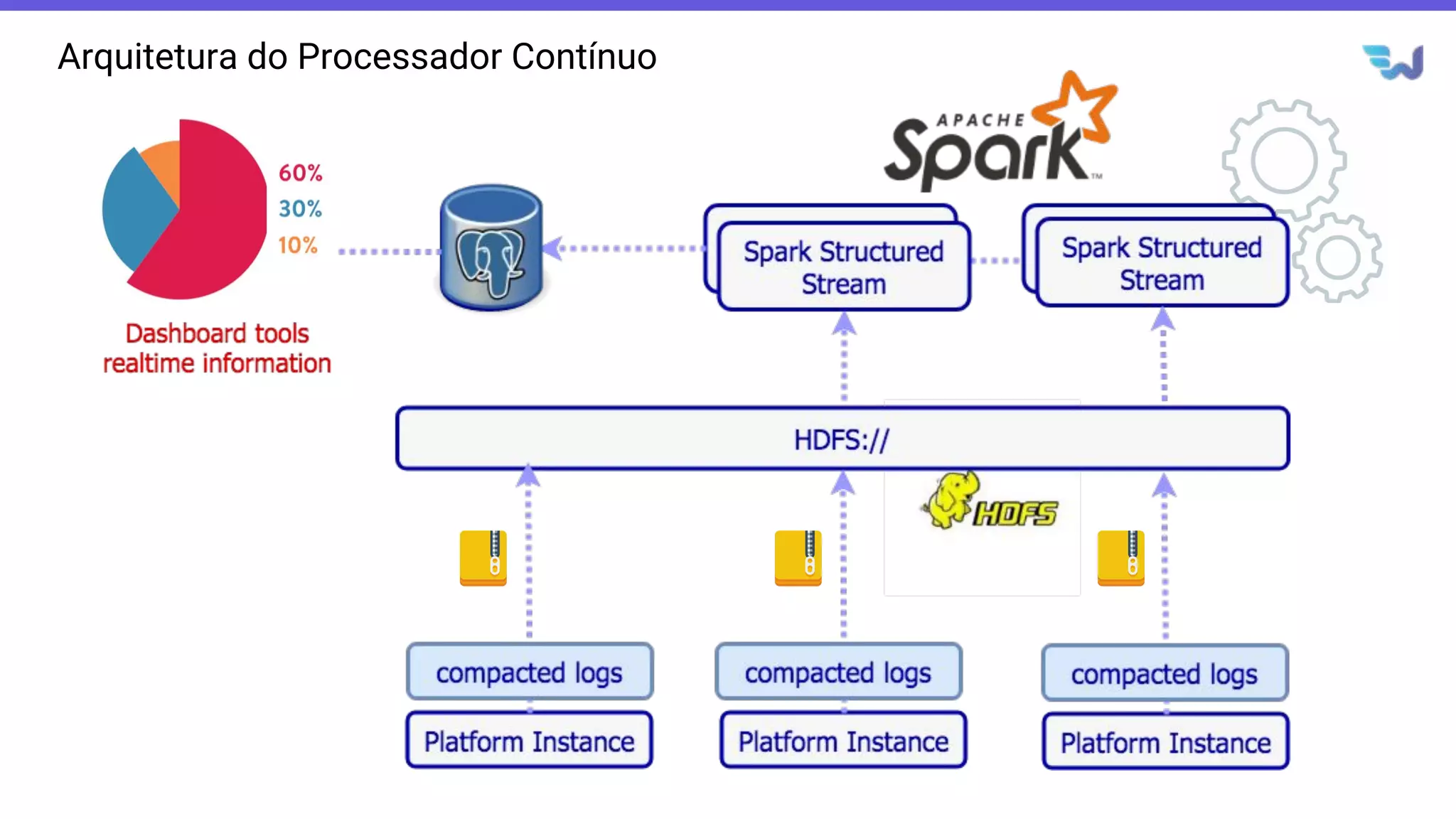
- O documento introduz o Apache Spark Structured Streaming, uma API para desenvolvimento de aplicações de processamento de dados em tempo real. - Apresenta casos de uso com leitura de dados de arquivos CSV em streaming, processamento com Spark SQL e escrita dos resultados em uma tabela no banco de dados PostgreSQL. - Detalha a arquitetura de uma aplicação que consolida métricas de transações financeiras em tempo real a partir de logs CSV, realizando filtros, agregações e janelas de 5 minutos.


![[DEVFEST] Apache Spark Casos de Uso e Escalabilidade](https://cdn.slidesharecdn.com/ss_thumbnails/apachespark-casosdeusoeescalabilidade-171106111137-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DTC21] Lucas Gomes - Do 0 ao 100 no Big Data](https://cdn.slidesharecdn.com/ss_thumbnails/dtc21lucasgomes-do0ao100embigdata-210316214734-thumbnail.jpg?width=640&height=640&fit=bounds)





















![[Redis conf18] The Versatility of Redis](https://cdn.slidesharecdn.com/ss_thumbnails/redisconf18theversatilityofredispoweringourcriticalbusinessusingredis-180430114117-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DataFest-2017] Apache Cassandra Para Sistemas de Alto Desempenho](https://cdn.slidesharecdn.com/ss_thumbnails/datafest-apachecassandraparasistemasdealtodesempenho-170927104534-thumbnail.jpg?width=640&height=640&fit=bounds)
![[TDC2016] Apache SparkMLlib: Machine Learning na Prática](https://cdn.slidesharecdn.com/ss_thumbnails/tdc2016-apachesparkmllibmachinelearningnapratica-160711163948-thumbnail.jpg?width=640&height=640&fit=bounds)
![[TDC2016] Apache Cassandra Estratégias de Modelagem de Dados](https://cdn.slidesharecdn.com/ss_thumbnails/tdc2016-apachecassandraestrategiasdemodelagemdedados-160711163941-thumbnail.jpg?width=640&height=640&fit=bounds)















