Baixado 38 vezes




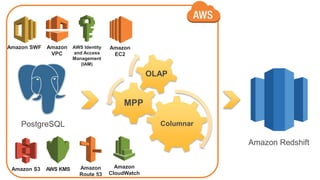


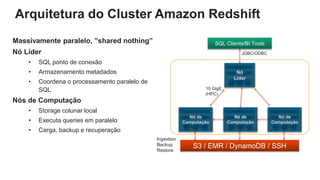

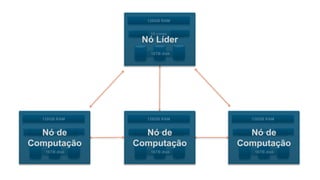
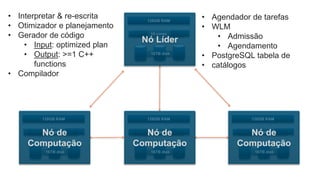
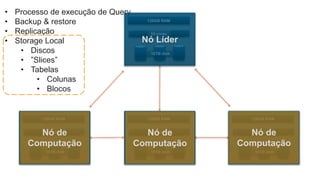

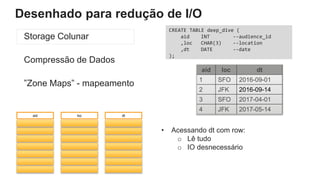
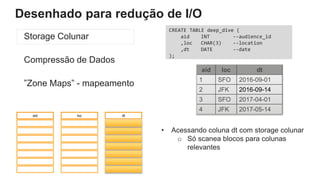
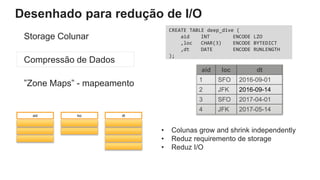
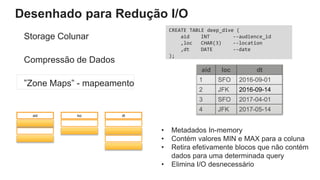



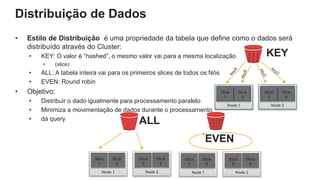
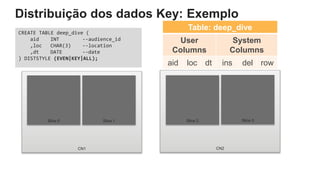
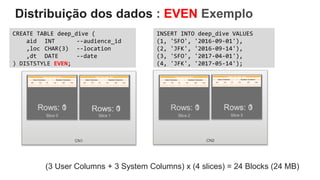
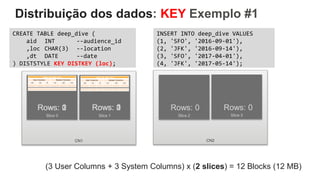
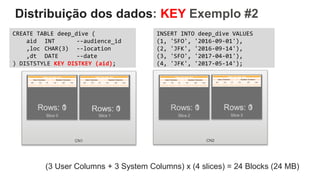










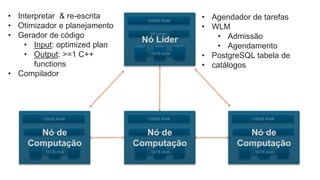

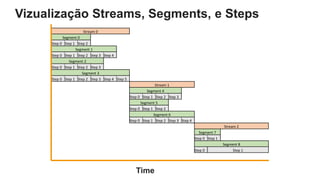
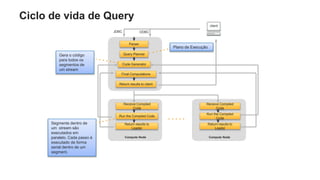


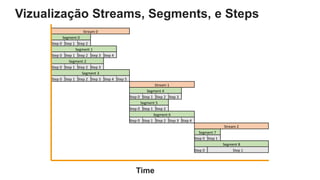
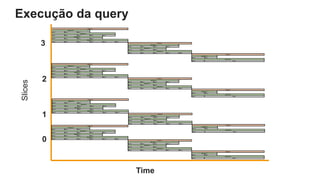
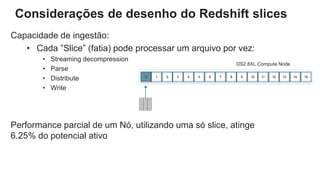
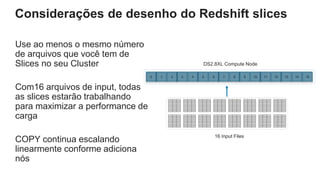





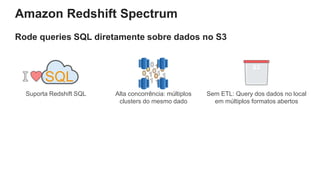


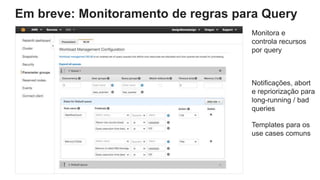
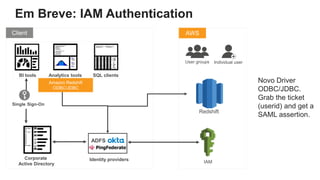




O documento é uma apresentação técnica sobre o Amazon Redshift, abordando sua arquitetura e o ciclo de vida das consultas. Ele detalha a armazenamento colunar, a compressão de dados, a distribuição de dados em 'slices' e o funcionamento dos nós de computação. Além disso, discute conceitos como zone maps, sort keys e o processo de execução de queries, ilustrando como esses elementos colaboram para otimizar desempenho e eficiência.






![[TDC2016] Apache Cassandra Estratégias de Modelagem de Dados](https://cdn.slidesharecdn.com/ss_thumbnails/tdc2016-apachecassandraestrategiasdemodelagemdedados-160711163941-thumbnail.jpg?width=640&height=640&fit=bounds)












![[TDC2016] Apache SparkMLlib: Machine Learning na Prática](https://cdn.slidesharecdn.com/ss_thumbnails/tdc2016-apachesparkmllibmachinelearningnapratica-160711163948-thumbnail.jpg?width=640&height=640&fit=bounds)















































