Baixado 19 vezes



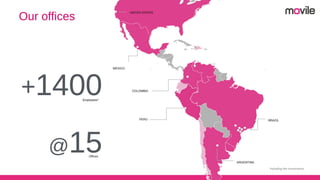



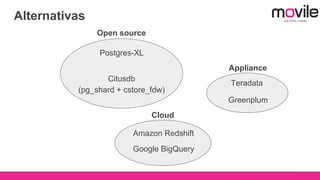

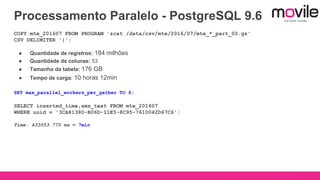








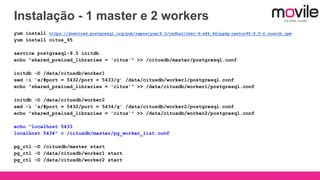



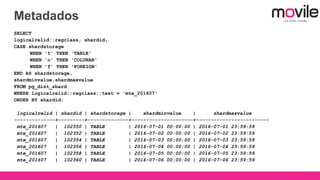


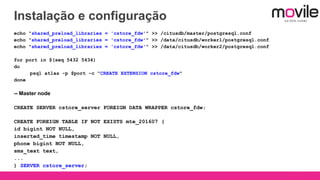


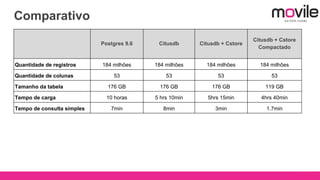

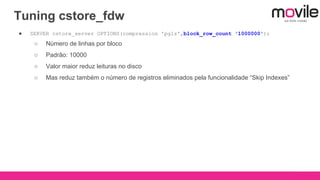




1) O documento discute bancos de dados analíticos open source como Citusdb e PostgreSQL para lidar com grandes volumes de dados na Movile. 2) A Movile enfrenta desafios com crescimento rápido de dados e necessidade de processamento paralelo. 3) Citusdb é uma boa opção porque é uma extensão do PostgreSQL que permite processamento massivamente paralelo através de sharding e replicação.



































































