Baixado 85 vezes







![8
O que é?
“Apache Cassandra é um banco de dados não
relacional (nosql) orientado a colunas,
distribuído, escalável, de alta disponibilidade,
tolerante a falhas”
[The Definitive Guide, Eben Hewitt, 2010]](https://image.slidesharecdn.com/conhecendoapachecassandramovile-150515230549-lva1-app6891/85/Conhecendo-Apache-Cassandra-Movile-8-320.jpg)

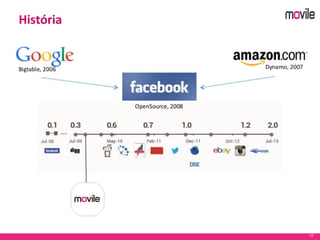
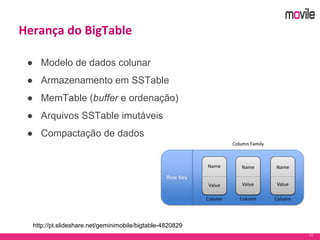
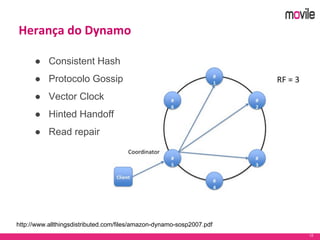



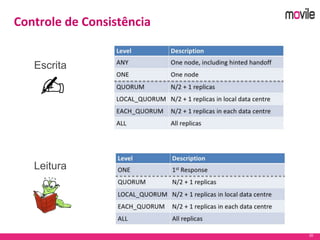



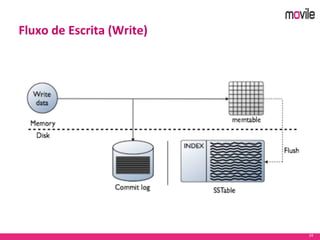

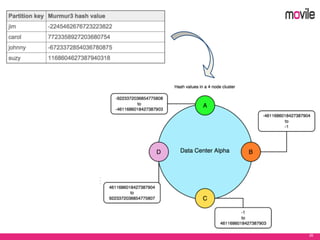
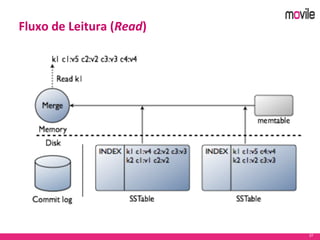
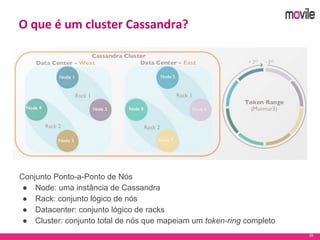
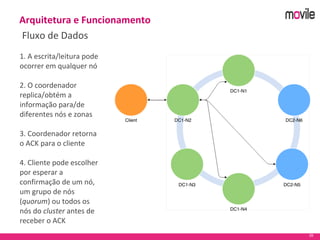
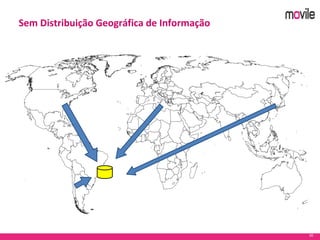
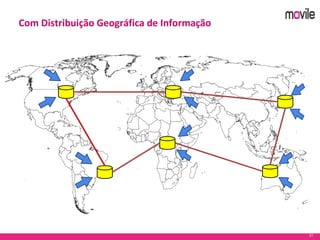


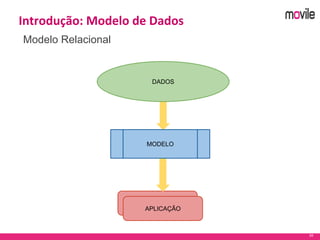
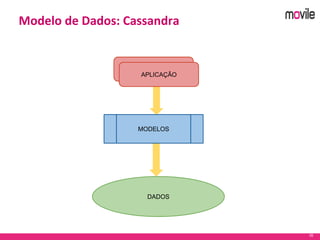
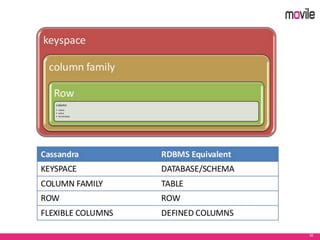
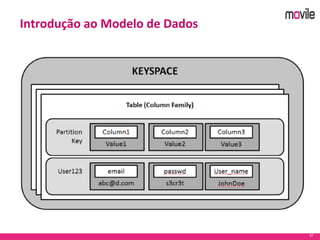
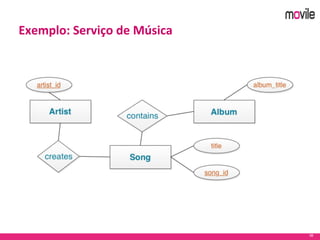
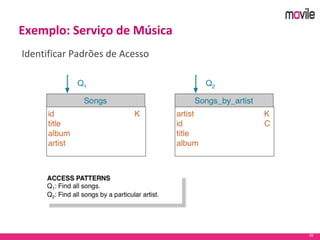




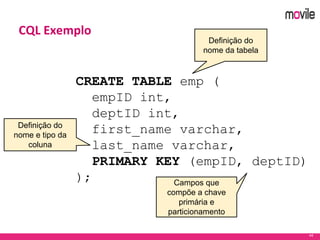









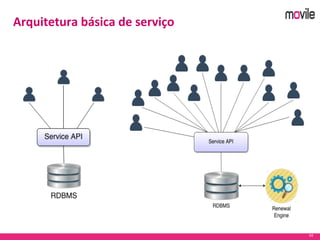
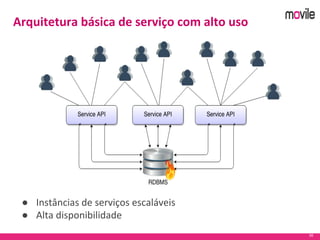
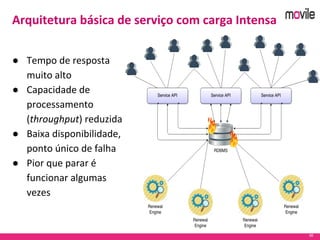
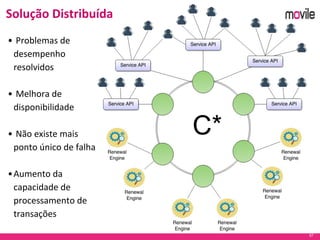
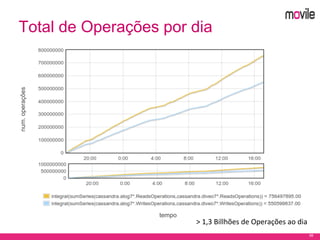
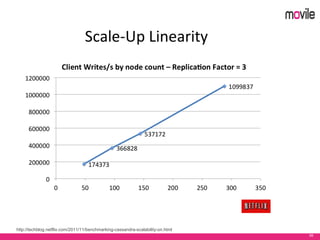




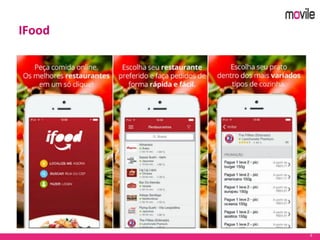
O documento apresenta uma introdução ao banco de dados Apache Cassandra. Explica o que é Cassandra, sua arquitetura, modelo de dados e como funciona. Também fornece exemplos de uso no serviço de assinaturas da Movile e dicas para aplicação do Cassandra.



![[TDC2016] Apache Cassandra Estratégias de Modelagem de Dados](https://cdn.slidesharecdn.com/ss_thumbnails/tdc2016-apachecassandraestrategiasdemodelagemdedados-160711163941-thumbnail.jpg?width=640&height=640&fit=bounds)




















































![[DataFest-2017] Apache Cassandra Para Sistemas de Alto Desempenho](https://cdn.slidesharecdn.com/ss_thumbnails/datafest-apachecassandraparasistemasdealtodesempenho-170927104534-thumbnail.jpg?width=640&height=640&fit=bounds)










