![NoSQL: onde, como e por quê? Rodrigo Hjort [email_address]](https://image.slidesharecdn.com/nosql-ondecomoeporqu-hjort-111110074847-phpapp01/85/NoSQL-onde-como-e-por-que-Cassandra-e-MongoDB-1-320.jpg)
















![“ It took two weeks to perform ALTER TABLE on the statuses [tweets] table.” – Twitter](https://image.slidesharecdn.com/nosql-ondecomoeporqu-hjort-111110074847-phpapp01/85/NoSQL-onde-como-e-por-que-Cassandra-e-MongoDB-26-320.jpg)
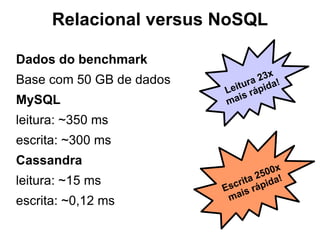

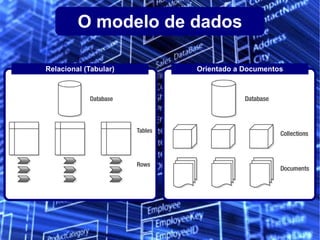
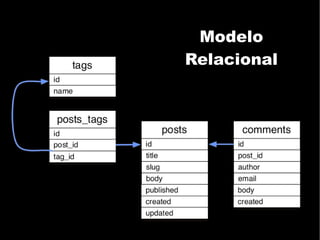

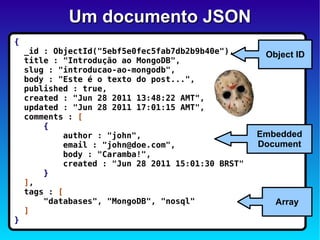



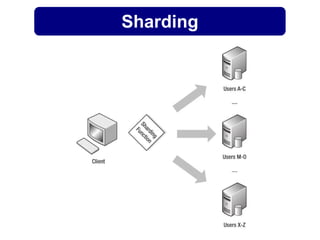
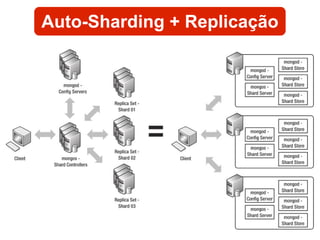




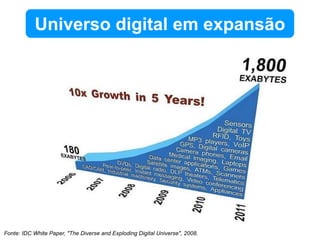
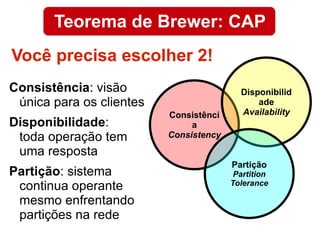
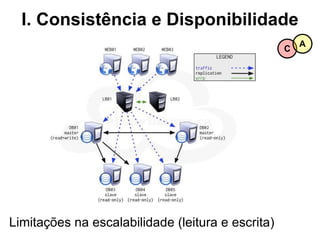
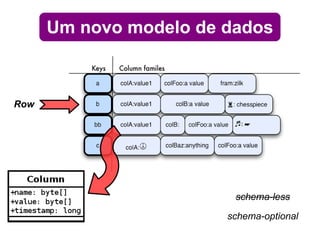
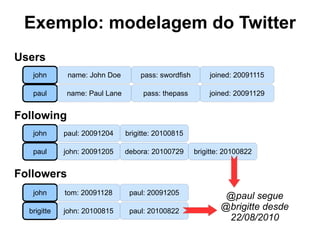
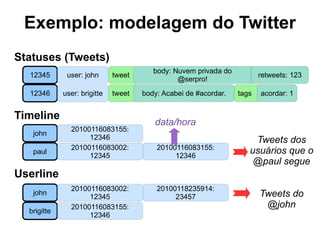
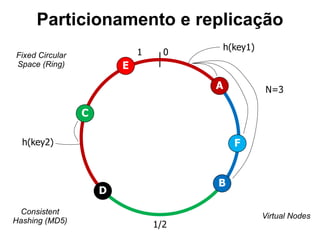
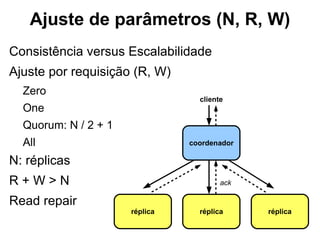
O documento discute o conceito de bancos de dados NoSQL e suas diferenças em relação ao SQL, enfatizando a escalabilidade horizontal e a flexibilidade dos esquemas. Também aborda o Teorema de Brewer em relação à consistência, disponibilidade e tolerância a partições, além de apresentar exemplos práticos de modelagem de dados e benchmarks entre sistemas relacionais e NoSQL, como Cassandra e MongoDB. A adoção do NoSQL é apresentada como uma inevitabilidade devido à diversidade de necessidades em ambientes de dados modernos.























![[TDC2016] Apache Cassandra Estratégias de Modelagem de Dados](https://cdn.slidesharecdn.com/ss_thumbnails/tdc2016-apachecassandraestrategiasdemodelagemdedados-160711163941-thumbnail.jpg?width=640&height=640&fit=bounds)











































