Transferir como PDF, PPTX























![Colletions - List
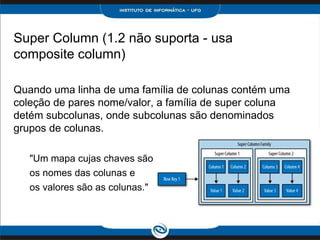
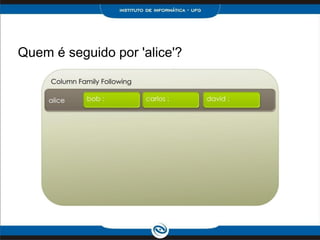
Quando a ordem dos elementos é considerada, o que
pode não ser a ordem natural ditada pelo tipo de
elementos, usar uma lista. Além disso, use uma lista
quando você precisa armazenar mesmo valor várias
vezes. Os valores da lista são retornados de acordo com o
índice, já no Set é retornado em ordem alfabética.
Insertion
ALTER TABLE users ADD top_cidades list<text>;
UPDATE users SET top_cidades = [ 'goiania', 'recife' ]
WHERE user_id = 'user';](https://image.slidesharecdn.com/apresentaocassandra-130218155355-phpapp02/85/Apresentacao-cassandra-30-320.jpg)
![Colletions - List
Addition
UPDATE users
SET top_cidades = [ 'sao paulo' ] + top_cidades WHERE
user_id = 'user';
Delete
UPDATE users
SET top_cidades = top_cidades - ['recife'] WHERE
user_id = 'user';](https://image.slidesharecdn.com/apresentaocassandra-130218155355-phpapp02/85/Apresentacao-cassandra-31-320.jpg)

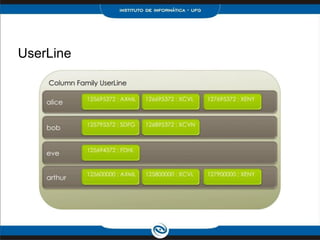
![Colletions - Map
Modification and replacement
UPDATE users
SET todo =
{ '2012-9-24' : 'entrou em goiania',
'2012-10-2 12:00' : 'saiu de goiania' }
WHERE user_id = 'user';
UPDATE users SET todo['2012-10-2 12:00'] = 'ficou em
goiania' WHERE user_id = 'user';](https://image.slidesharecdn.com/apresentaocassandra-130218155355-phpapp02/85/Apresentacao-cassandra-33-320.jpg)
![Colletions - Map
Usando TTL
UPDATE users USING TTL <computed_ttl>
SET todo['2012-10-1'] = 'precisa sair' WHERE user_id =
'user';
Delete
DELETE todo['2012-9-24'] FROM users WHERE user_id =
'user';](https://image.slidesharecdn.com/apresentaocassandra-130218155355-phpapp02/85/Apresentacao-cassandra-34-320.jpg)





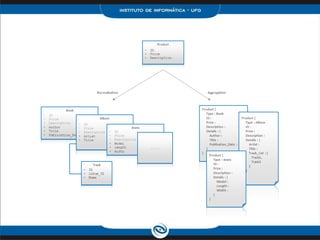

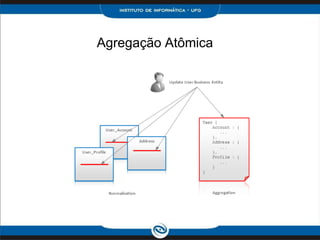


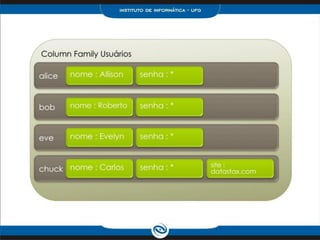
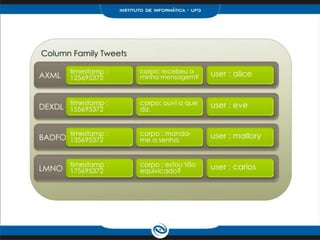

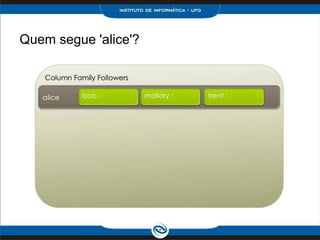





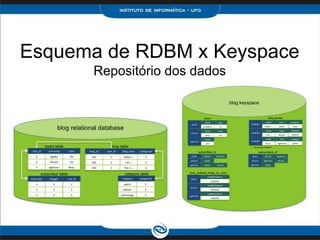
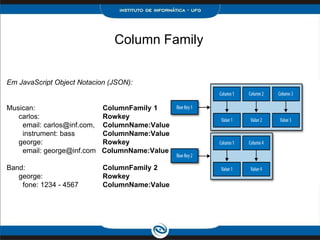
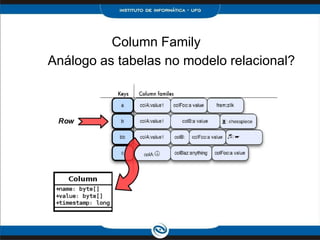
O documento discute o modelo de dados do Cassandra, incluindo: 1) Keyspaces, column families e indexes para organizar os dados; 2) Técnicas como denormalização e agregação para melhor desempenho; 3) Coleções como list, set e map para armazenar dados complexos.
![[TDC2016] Apache Cassandra Estratégias de Modelagem de Dados](https://cdn.slidesharecdn.com/ss_thumbnails/tdc2016-apachecassandraestrategiasdemodelagemdedados-160711163941-thumbnail.jpg?width=640&height=640&fit=bounds)










![[TDC2016] Apache SparkMLlib: Machine Learning na Prática](https://cdn.slidesharecdn.com/ss_thumbnails/tdc2016-apachesparkmllibmachinelearningnapratica-160711163948-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DataFest-2017] Apache Cassandra Para Sistemas de Alto Desempenho](https://cdn.slidesharecdn.com/ss_thumbnails/datafest-apachecassandraparasistemasdealtodesempenho-170927104534-thumbnail.jpg?width=640&height=640&fit=bounds)




























