Baixado 30 vezes







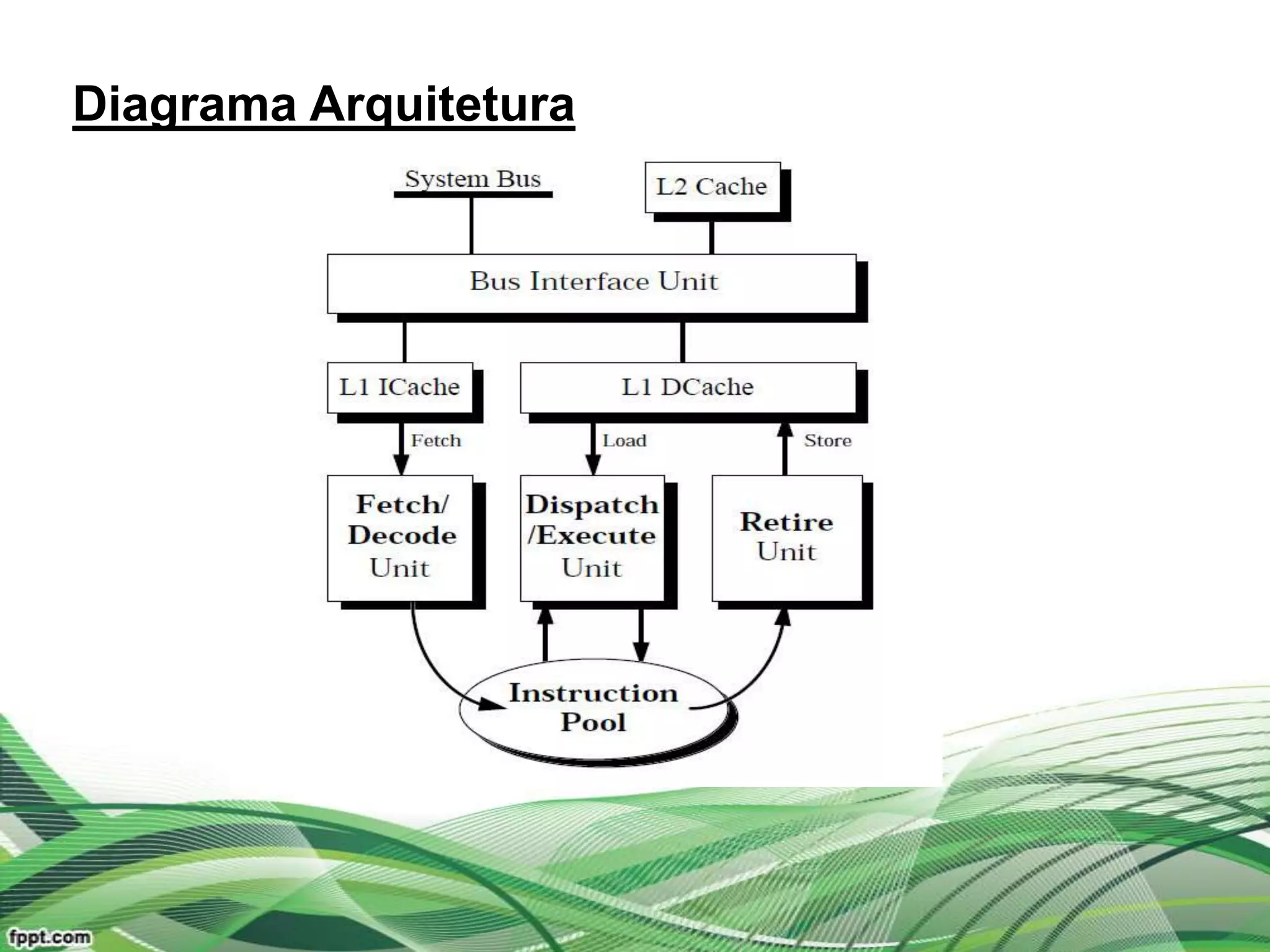




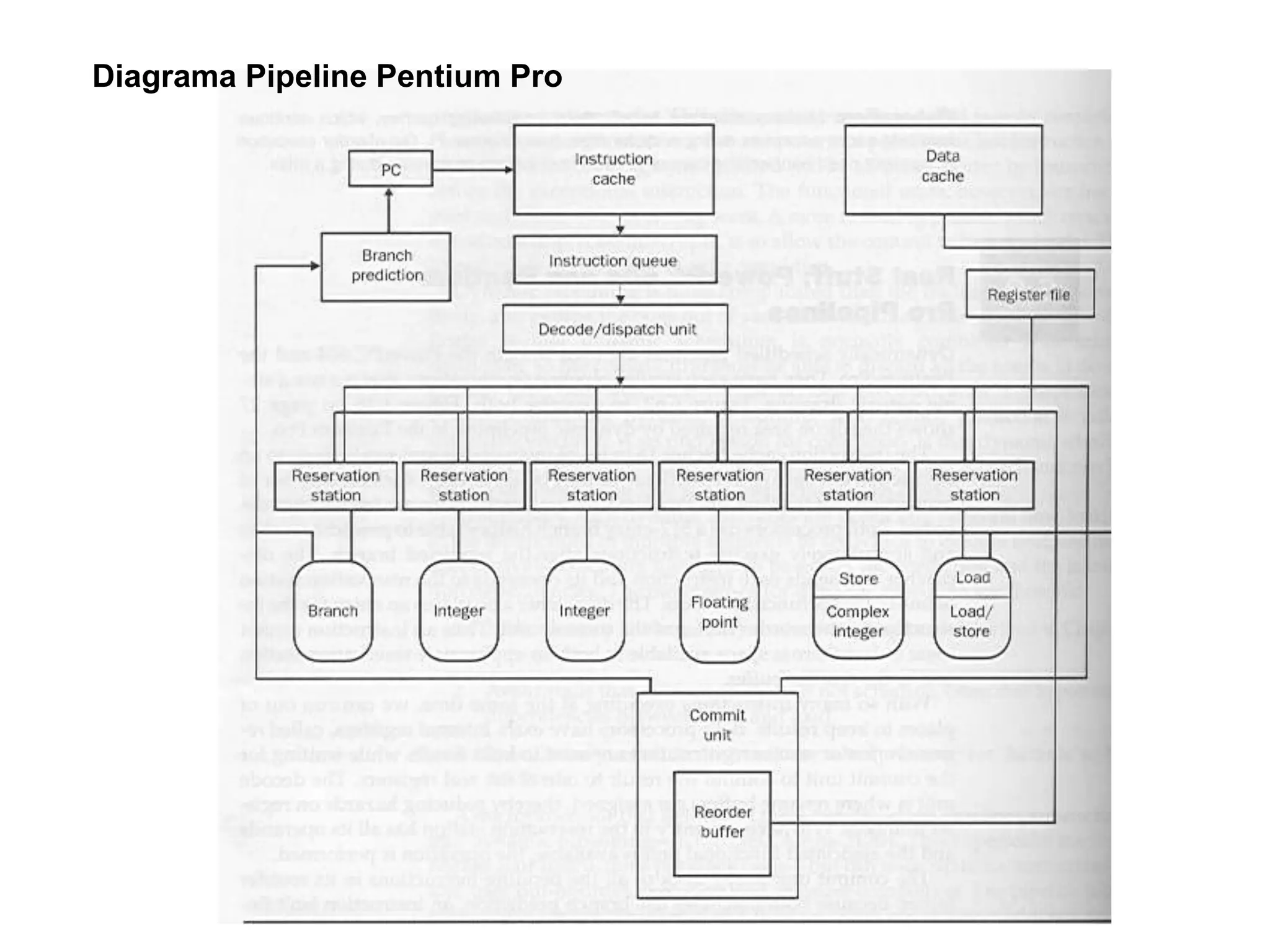





O Pentium Pro foi o primeiro processador da Intel a usar uma arquitetura híbrida RISC/CISC. Possuía uma organização interna com módulos para decodificação, despacho e execução de instruções RISC de tamanho fixo geradas a partir de instruções CISC variáveis. Sua arquitetura superescalar permitia executar múltiplas instruções por ciclo de clock.















































