Baixado 26 vezes





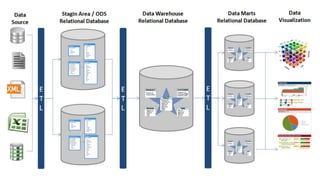


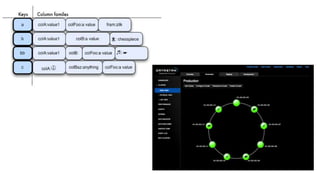


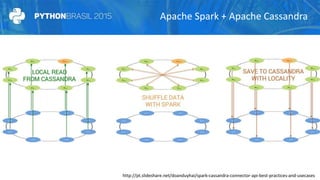

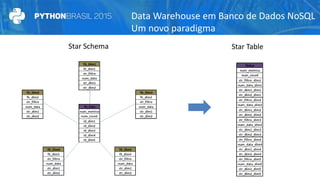
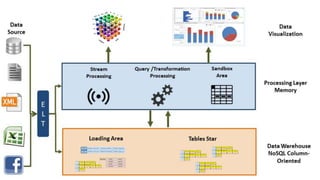



O documento discute a criação de data warehouses em bancos de dados NoSQL com Cassandra, Spark e Python. Primeiro apresenta um breve histórico dos data warehouses e seus desafios em bancos relacionais. Em seguida, descreve as funcionalidades do Cassandra e Spark para armazenamento e processamento de dados. Por fim, propõe um novo paradigma de data warehouses utilizando essas ferramentas de forma distribuída e em memória.
























































![[DTC21] André Marques - Jornada do Engenheiro de Dados](https://cdn.slidesharecdn.com/ss_thumbnails/jornadadoengenheirodedados-210317153718-thumbnail.jpg?width=640&height=640&fit=bounds)




