Transferir como PDF, PPTX






















![Padrões usados em Linked Data
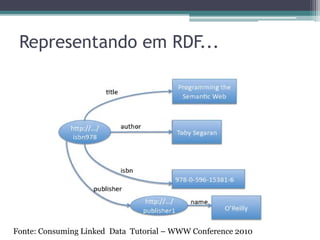
▫ Modelo RDF
A utilização um modelo de dados comum torna
possível a implementação de aplicações genéricas
capazes de operar sobre o espaço de dados global
[Heath and Bizer 2011] .
Descentralizado, baseado em grafo e extensível,
com alto nível de expressividade e permitindo a
interligação entre conjuntos de dados através de
Links RDF.
Armazenamento através de grafo em memória,
arquivo texto ou RDF Triple Store.](https://image.slidesharecdn.com/linkeddata-minicurso-sbbd-2011-v2-111003210820-phpapp02/85/Linked-Data-Minicurso-SBBD-2011-28-320.jpg)


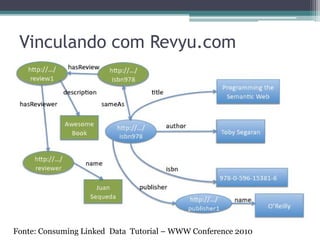
![RDF: Formatos de Serialização
• RDF/XML
▫ Mais antigo e mais amplamente usado.
▫ Prolixo e pouco legível para o ser humano.
• N3 (Notation 3) [Berners-Lee 1998]
▫ Mais expressivo que RDF/XML.
• Turtle [Beckett 2007]
▫ Subconjunto de N3.
• N-Triples
▫ Subconjunto de N3 e Turtle
▫ Não possui alguns atalhos dos outros formatos como
recursos aninhados e URIs compactas
Termina ficando prolixo, mas simples para fazer parse.
• RDFa
▫ RDF embutido em HTML
• JSON](https://image.slidesharecdn.com/linkeddata-minicurso-sbbd-2011-v2-111003210820-phpapp02/85/Linked-Data-Minicurso-SBBD-2011-33-320.jpg)




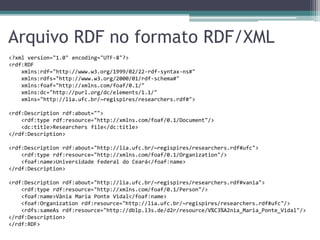
![Padrões usados em Linked Data
• Protocolo e Linguagem SPARQL
▫ Linguagem de consulta de alto nível
[Prud’hommeaux and Seaborne 2008] para
recuperação de informações contidas em grafos
RDF.
▫ Protocolo [Clark et al. 2008] usado para enviar
consultas e recuperar resultados através do
protocolo HTTP.
▫ Fontes Linked Data tipicamente fornecem um
SPARQL Endpoint que é um serviço Web com
suporte ao protocolo SPARQL.](https://image.slidesharecdn.com/linkeddata-minicurso-sbbd-2011-v2-111003210820-phpapp02/85/Linked-Data-Minicurso-SBBD-2011-41-320.jpg)











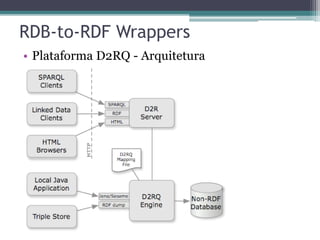




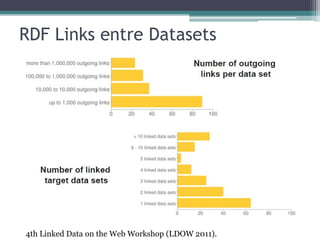



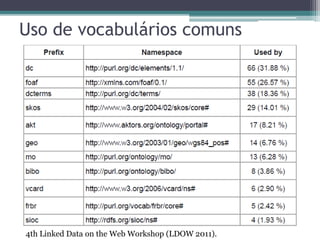











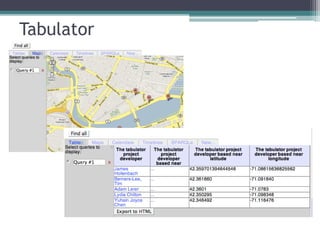




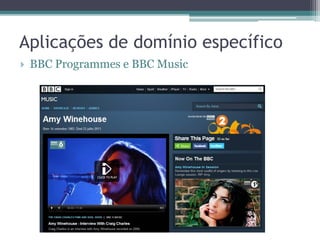

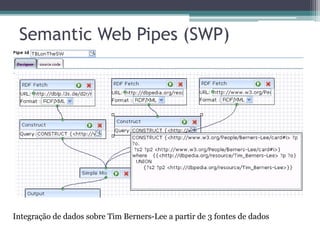











O documento apresenta os fundamentos e princípios do Linked Data, incluindo (1) a utilização de URIs para identificar recursos, (2) o uso do HTTP para acessar essas URIs, (3) a disponibilização de informações úteis usando RDF ao acessar URIs, e (4) a inclusão de links para outros recursos. Também discute (2) os formatos e padrões usados como RDF, SPARQL e HTTP, e (3) estratégias para armazenamento de dados RDF.












































































