Baixado 13 vezes











![Princípios Linked Data
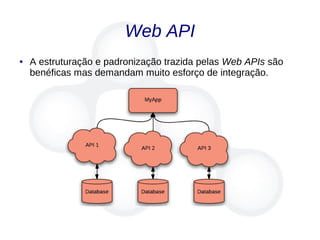
● Proposto por Tim Berners-Lee [6]:
(1) Use URIs para dar nomes as coisas;
(2) Use HTTP URIs para que esses nomes possam ser
acessados;
(3) Quando uma URI é acessada, responda com dados
úteis, utilizando padrões da web;
(4) Inclua links para outras URIs para facilitar a
descoberta de novos dados;](https://image.slidesharecdn.com/linkeddata-palestra-130805182236-phpapp02/85/Palestra-Introducao-a-Linked-Data-12-320.jpg)


![RDF
● Dados publicados na Web devem seguir uma estrutura
padrão para permitir interoperabilidade entre as aplicações;
● Linked Data utiliza o modelo RDF [9] (Resource Description
Framework);
● RDF é um modelo de dados simples feito sob medida para a
arquitetura Web;
● RDF é uma recomendação W3C;](https://image.slidesharecdn.com/linkeddata-palestra-130805182236-phpapp02/85/Palestra-Introducao-a-Linked-Data-15-320.jpg)
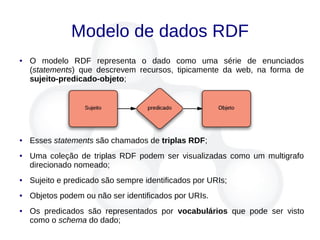



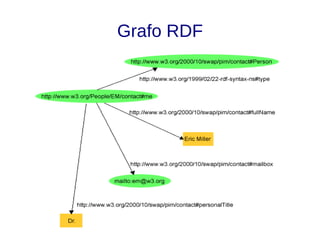

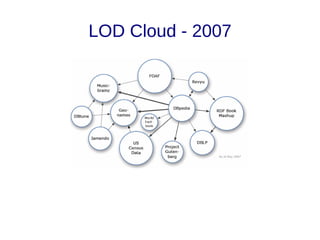
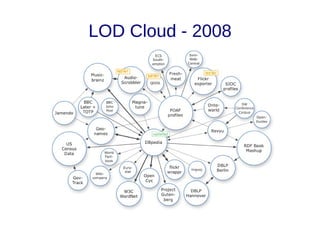
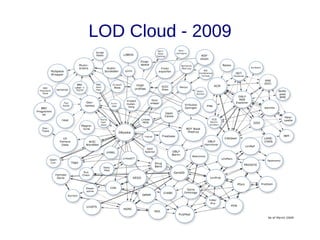
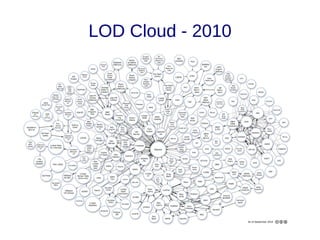
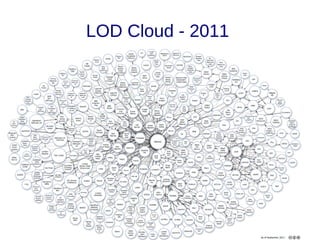



![Links
● Links de vocabulários [10]: Descrevem os tipos de relacionamentos. Auxiliam na
integração de diferentes fontes de dados. Em Linked Data o esquema é a fusão
da definição dos termos de diferentes vocabulários;
– A publicação de novos dados deve, sempre que possível, reusar
vocabulários consolidados (Foaf, Basic Geo, Gene Ontology, MeSH);
– O autor da publicação é livre para criar seu próprio vocabulário, para tal,
a URI do termo definido deve ser dereferenciável, e sempre que
possível mapeando para vocabulários externos equivalentes
(owl:sameAs, owl:equivalentProperty, owl:equivalentClass).](https://image.slidesharecdn.com/linkeddata-palestra-130805182236-phpapp02/85/Palestra-Introducao-a-Linked-Data-30-320.jpg)
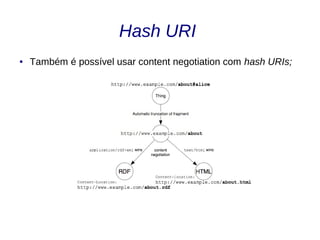
![“Dereferenciando” URIs
● Qualquer HTTP URI deve ser “dereferenciável”;
● O usuário deve obter uma representação do dado ao acessar a URI através
do protocolo HTTP.
● Não importa se a URI identifica um documento HTML ou um conceito,
pessoa ou lugar do mundo;
● Content Negotiation [7]. Humanos obtêm documentos HTML e máquinas
documentos RDF;
– Accept: text/html
– Accept: application/rdf+xml
● Estratégias:
– 303 URI
– Hash URI](https://image.slidesharecdn.com/linkeddata-palestra-130805182236-phpapp02/85/Palestra-Introducao-a-Linked-Data-31-320.jpg)
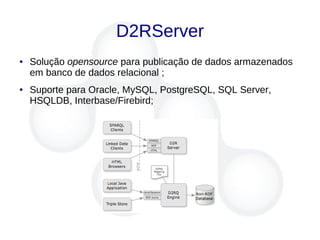
![303 URIs
● Infelizmente objetos reais não podem ser enviados através do
protocolo HTTP :(
● Ao invés de responder com o objeto real representado pela URI
o servidor HTTP responde o código 303 (see other [8]) que
indica a URI do documento que melhor descreve o objeto;
● O cliente faz uma segunda requisição HTTP para obter a
descrição do objeto;](https://image.slidesharecdn.com/linkeddata-palestra-130805182236-phpapp02/85/Palestra-Introducao-a-Linked-Data-32-320.jpg)












![Referências
● [1] http://en.wikipedia.org/wiki/Linked_data
● [2] http://microformats.org/
● [3] http://www.mashape.com
● [4] http://programmableweb.com
● [5] http://en.wikipedia.org/wiki/World_Wide_Web
● [6] http://www.w3.org/DesignIssues/LinkedData.html
● [7] https://en.wikipedia.org/wiki/Content_negotiation
● [8] http://en.wikipedia.org/wiki/HTTP_303
● [9] http://en.wikipedia.org/wiki/Resource_Description_Framework
● [10] http://www.w3.org/standards/semanticweb/ontology
● [11] http://www.w3.org/TR/cooluris/
● [12] http://en.wikipedia.org/wiki/SPARQL](https://image.slidesharecdn.com/linkeddata-palestra-130805182236-phpapp02/85/Palestra-Introducao-a-Linked-Data-48-320.jpg)

O documento discute os princípios do Linked Data para publicação e compartilhamento de dados na Web. Ele explica como os Linked Data utilizam URIs para identificar recursos e o modelo RDF para estruturar as informações, permitindo a integração de dados de diferentes fontes através de links entre os recursos.

















































