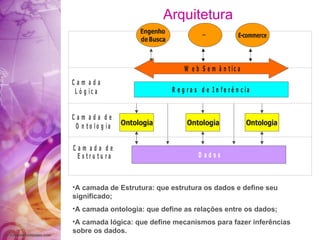
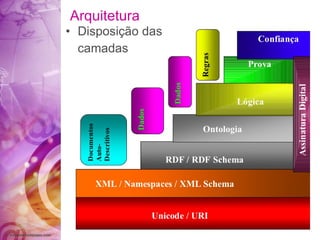
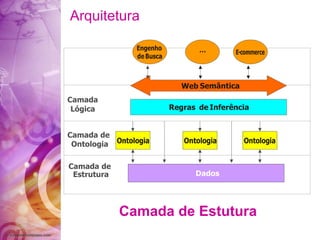
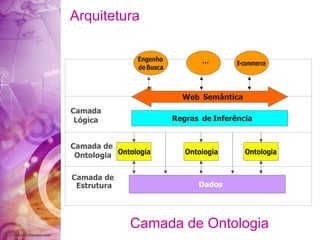
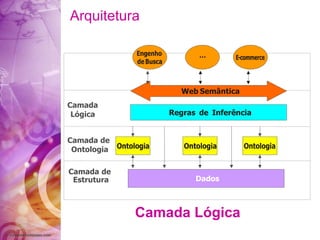
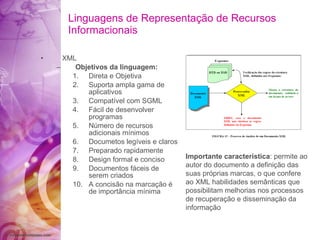
O documento discute a história da internet e da web semântica, incluindo: 1) A evolução da internet desde a década de 1960 com a criação da ARPANET; 2) Os desafios da web atual em organizar a grande quantidade de informações; 3) A proposta da web semântica para estruturar os dados e atribuir significado para melhor recuperação de informações.