Transferir como PDF, PPTX











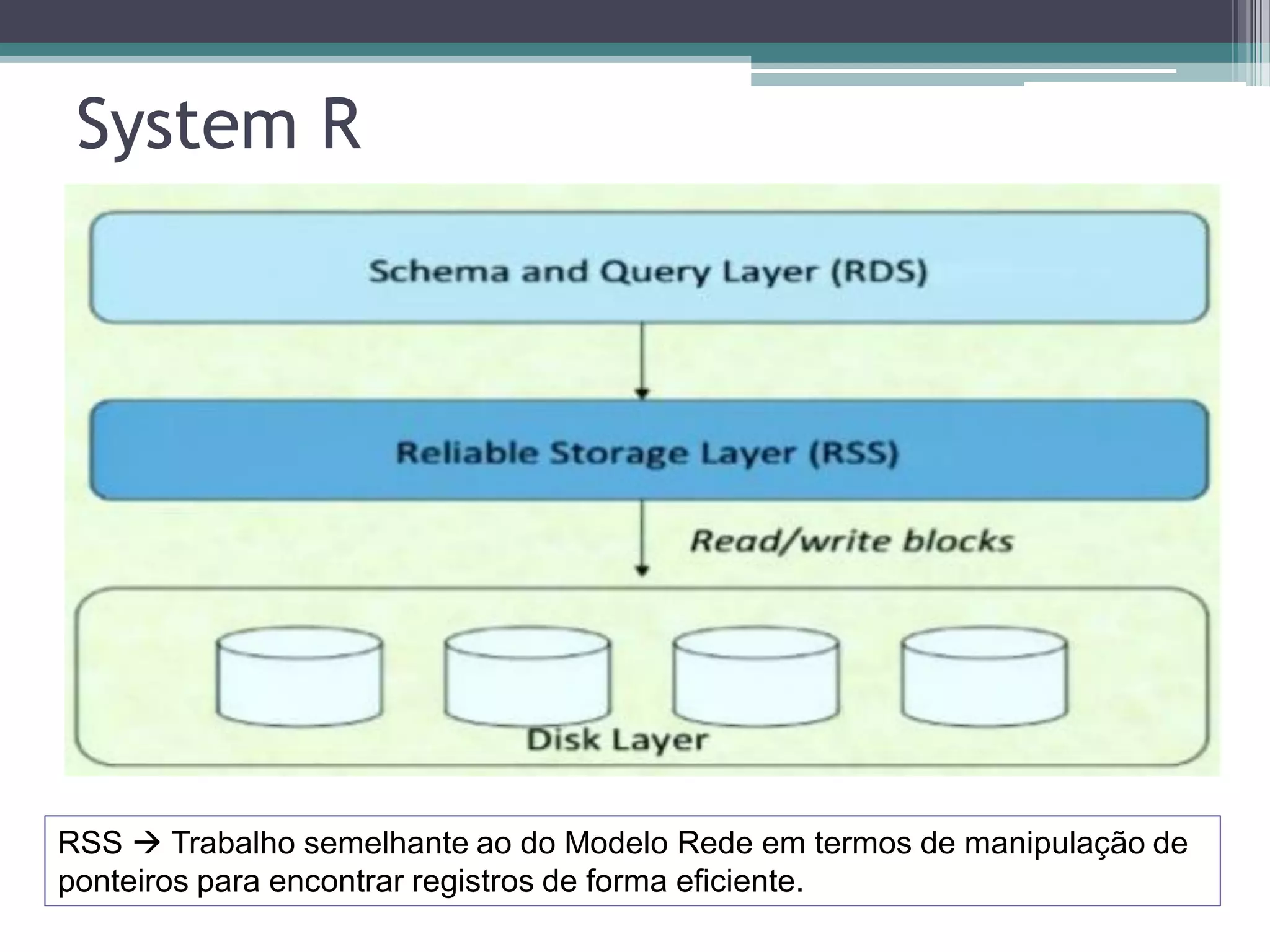
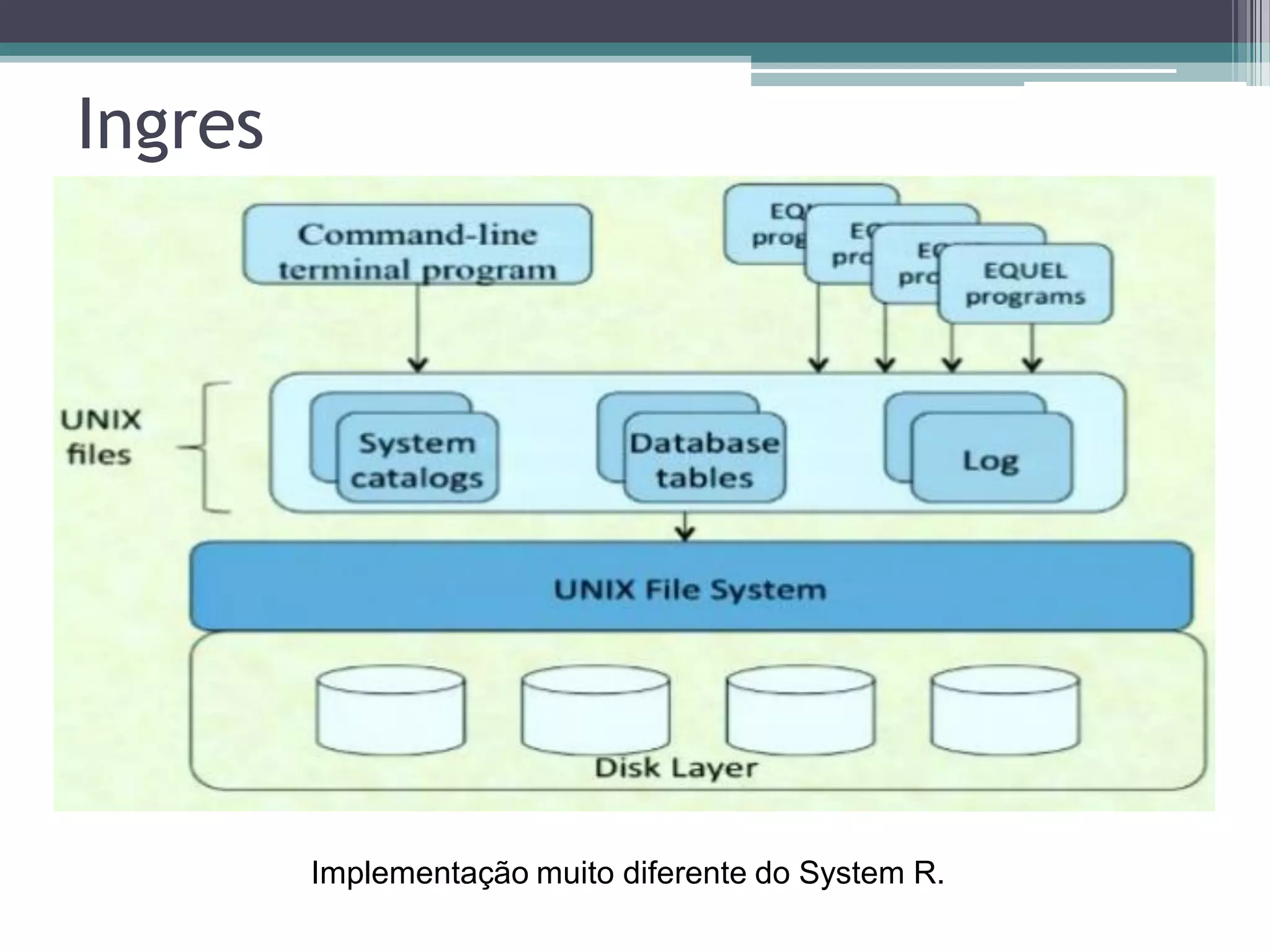






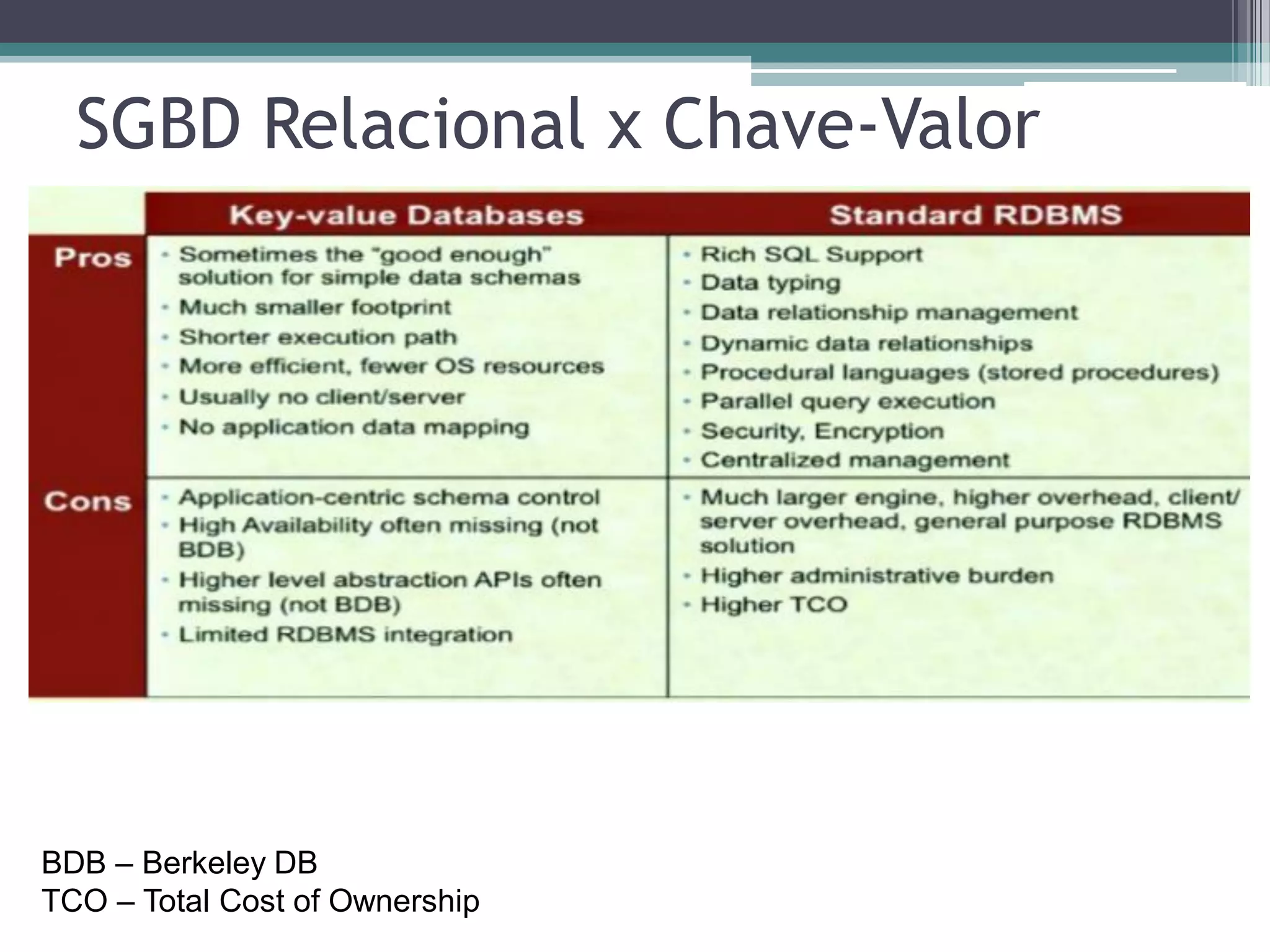




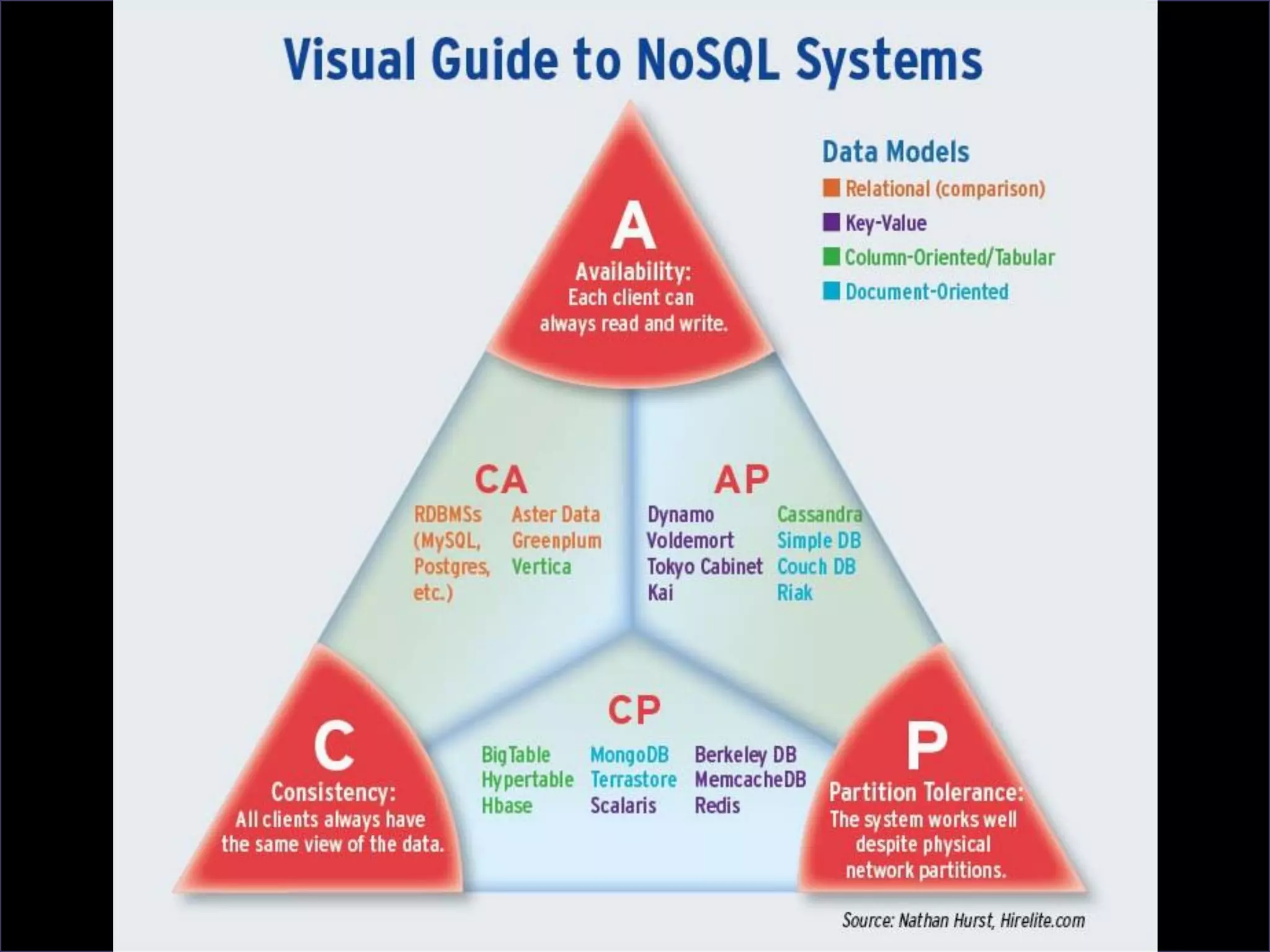

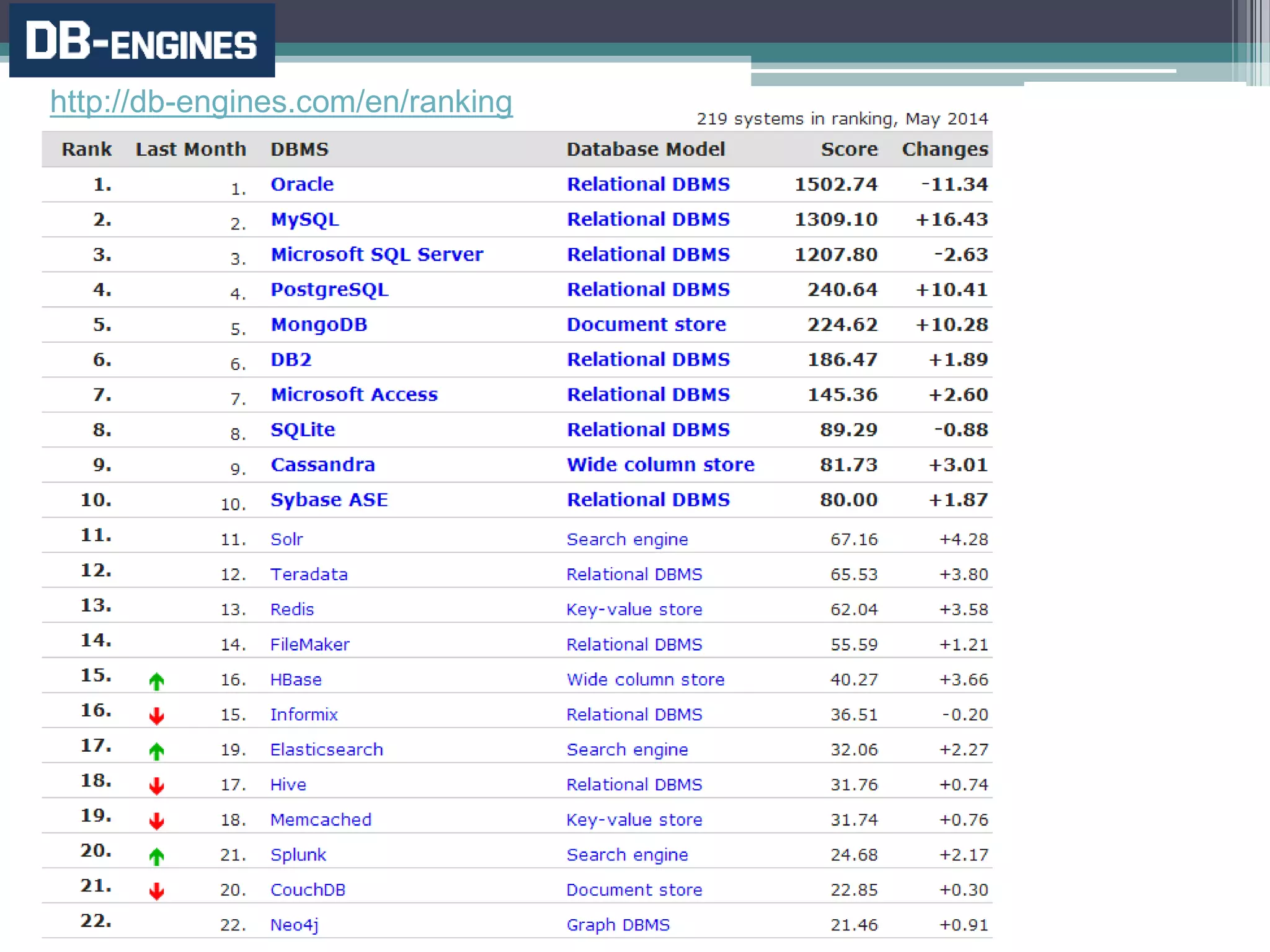
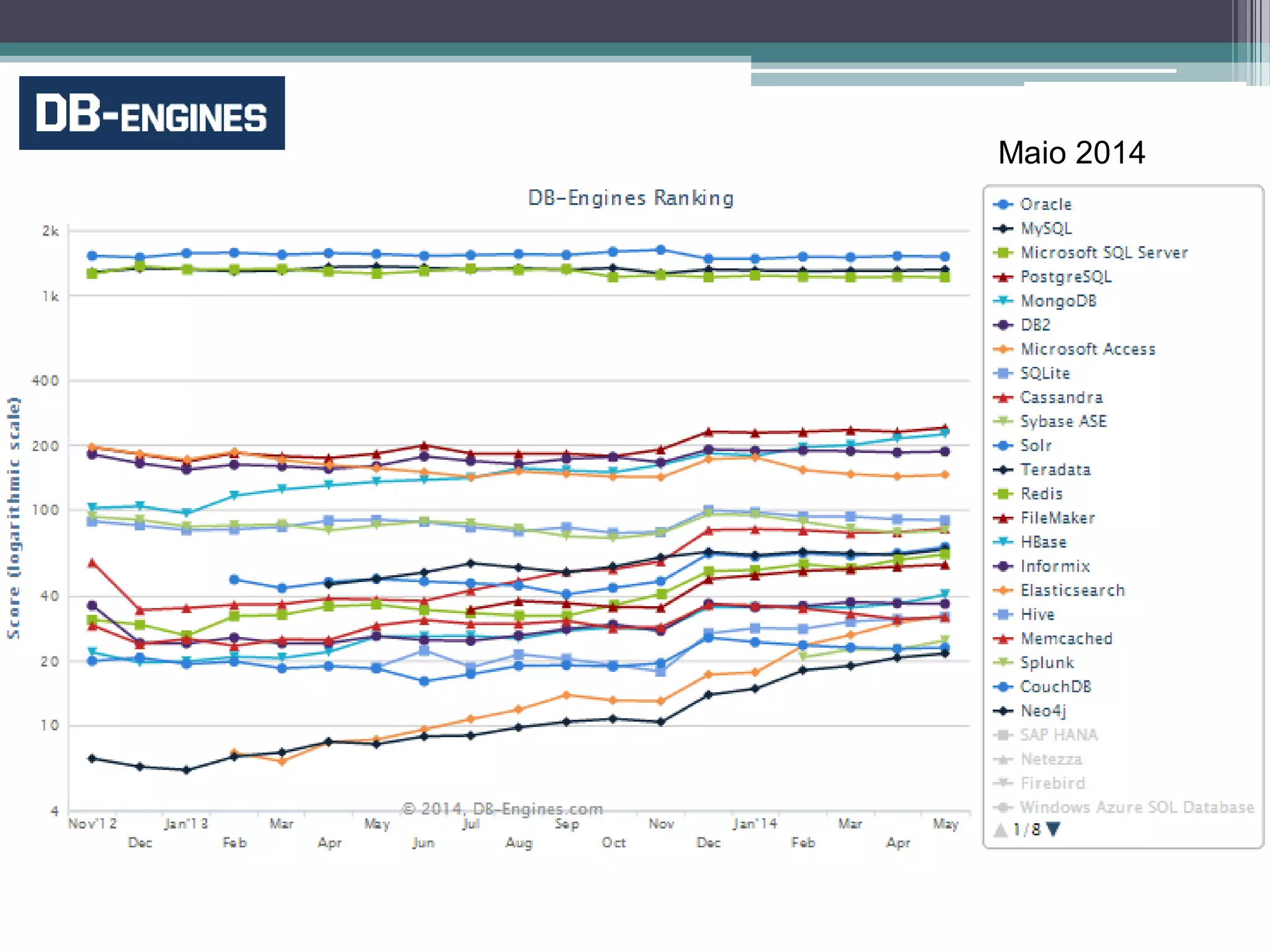
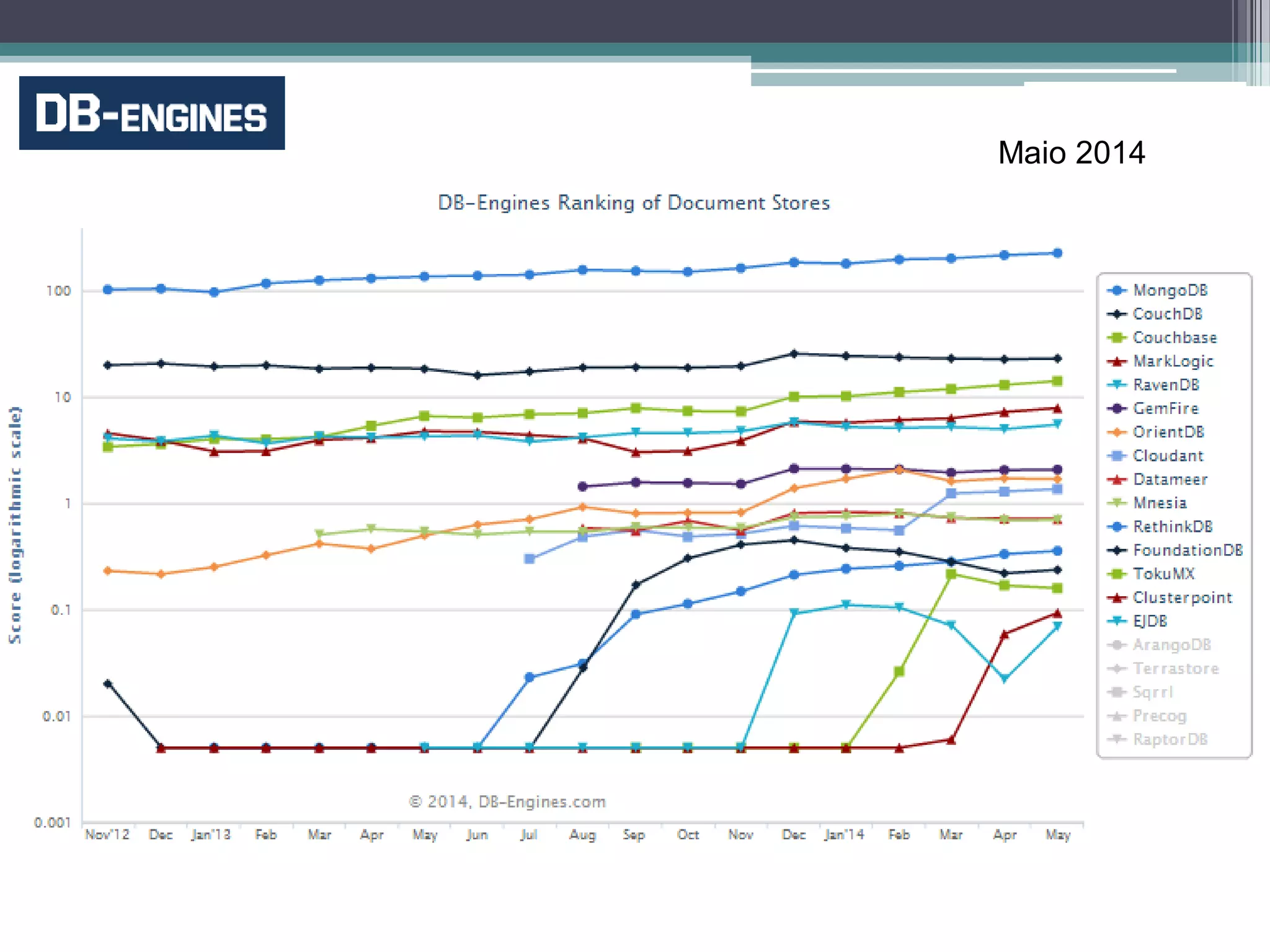
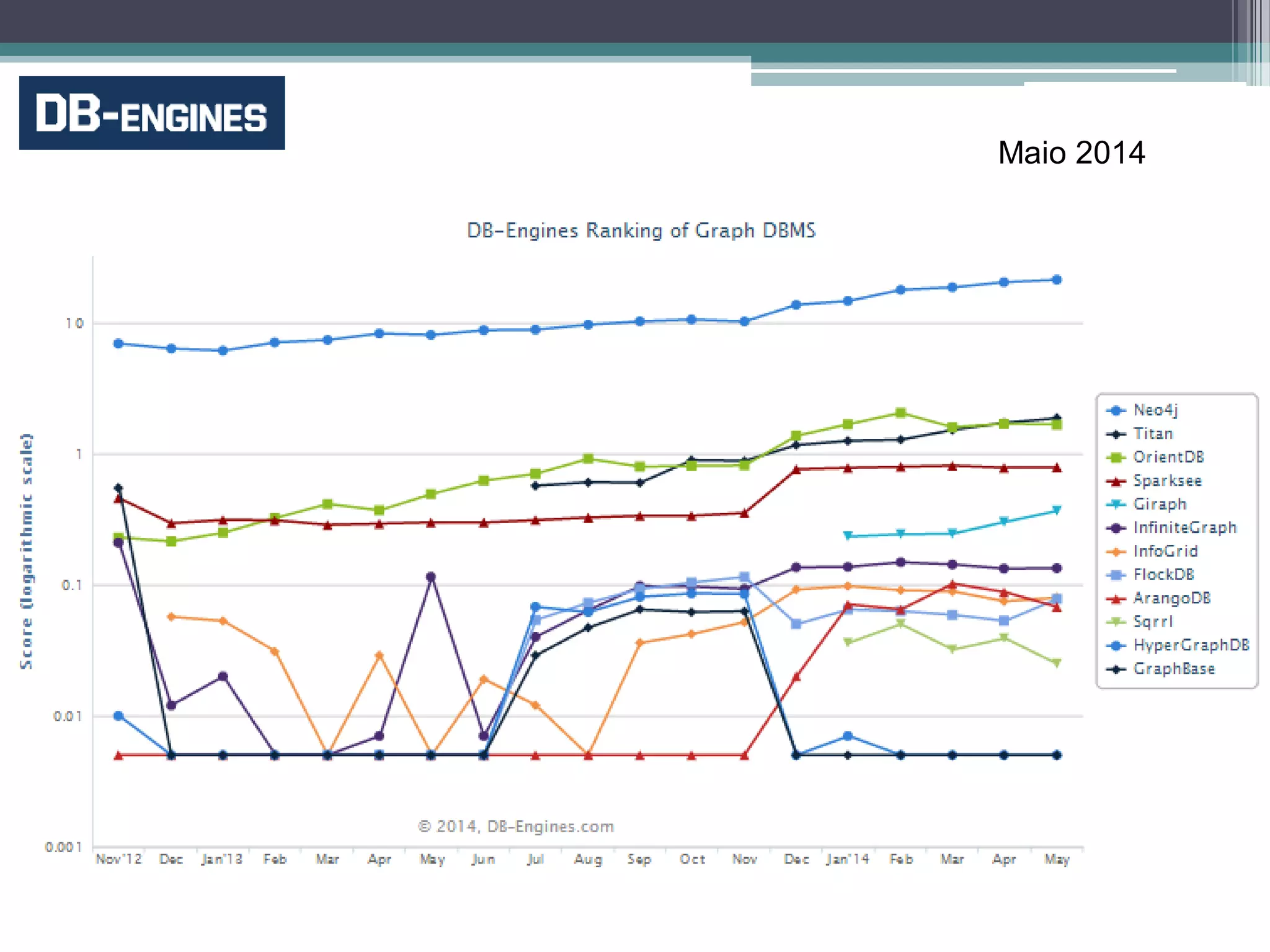
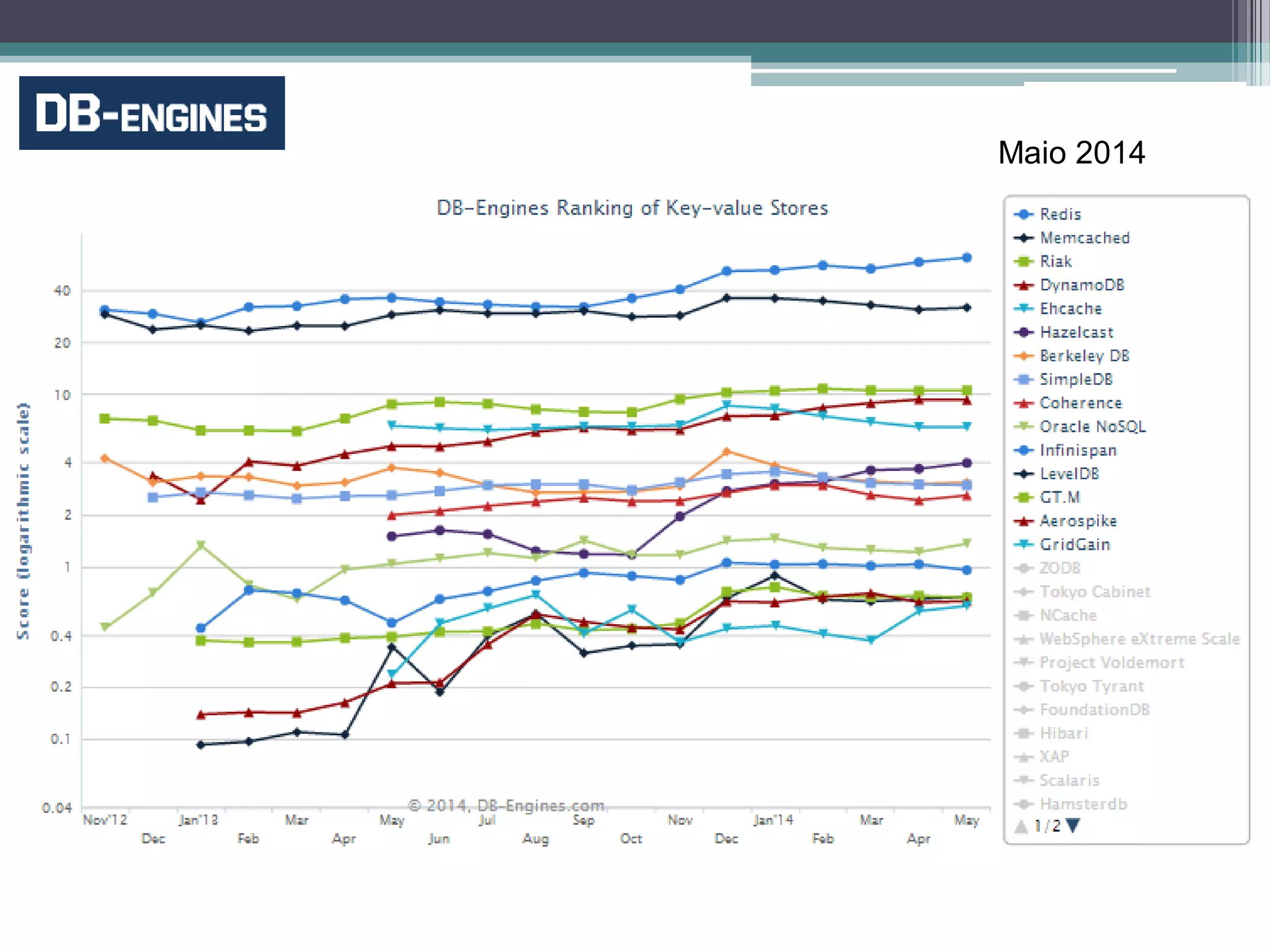
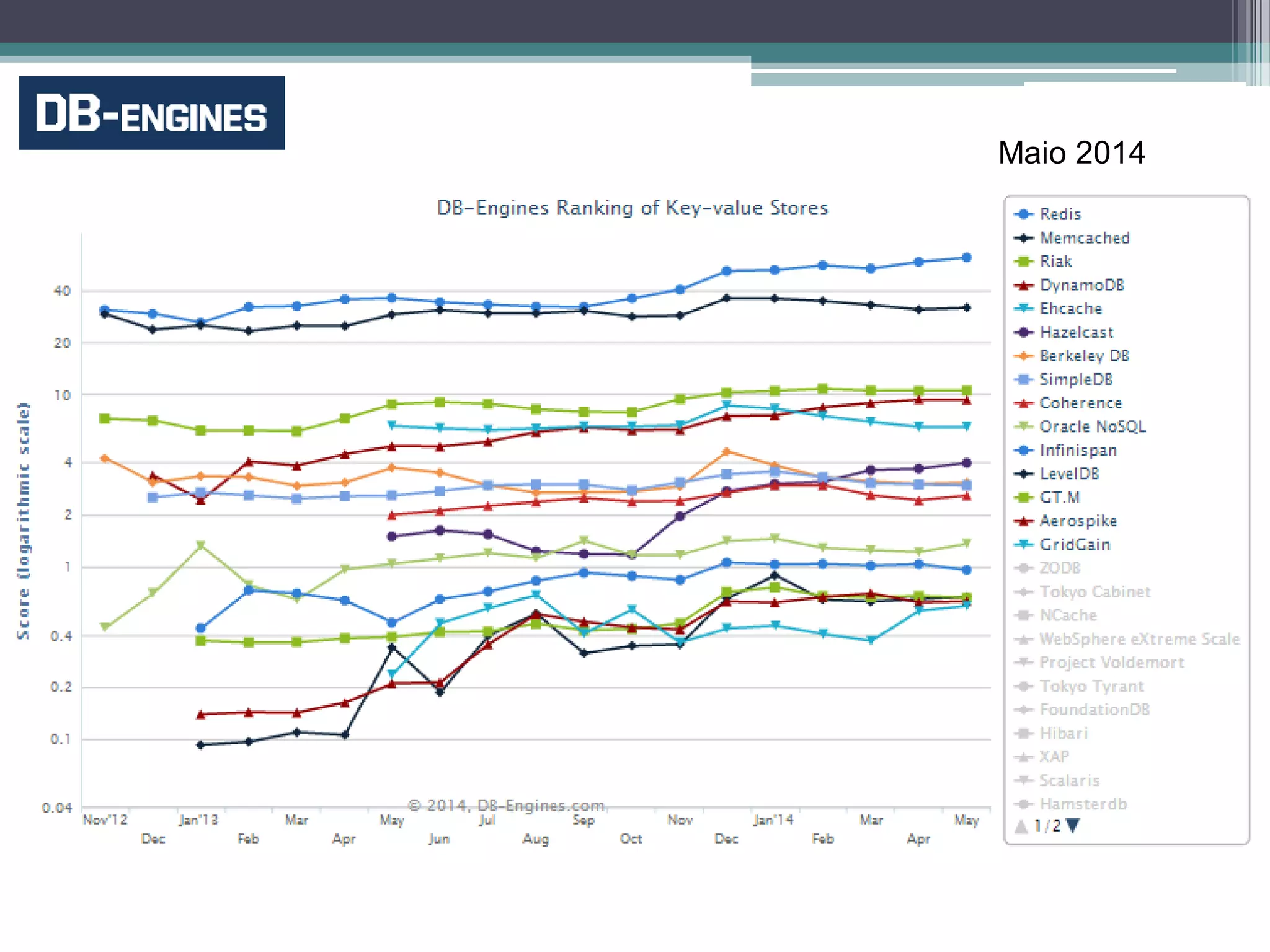










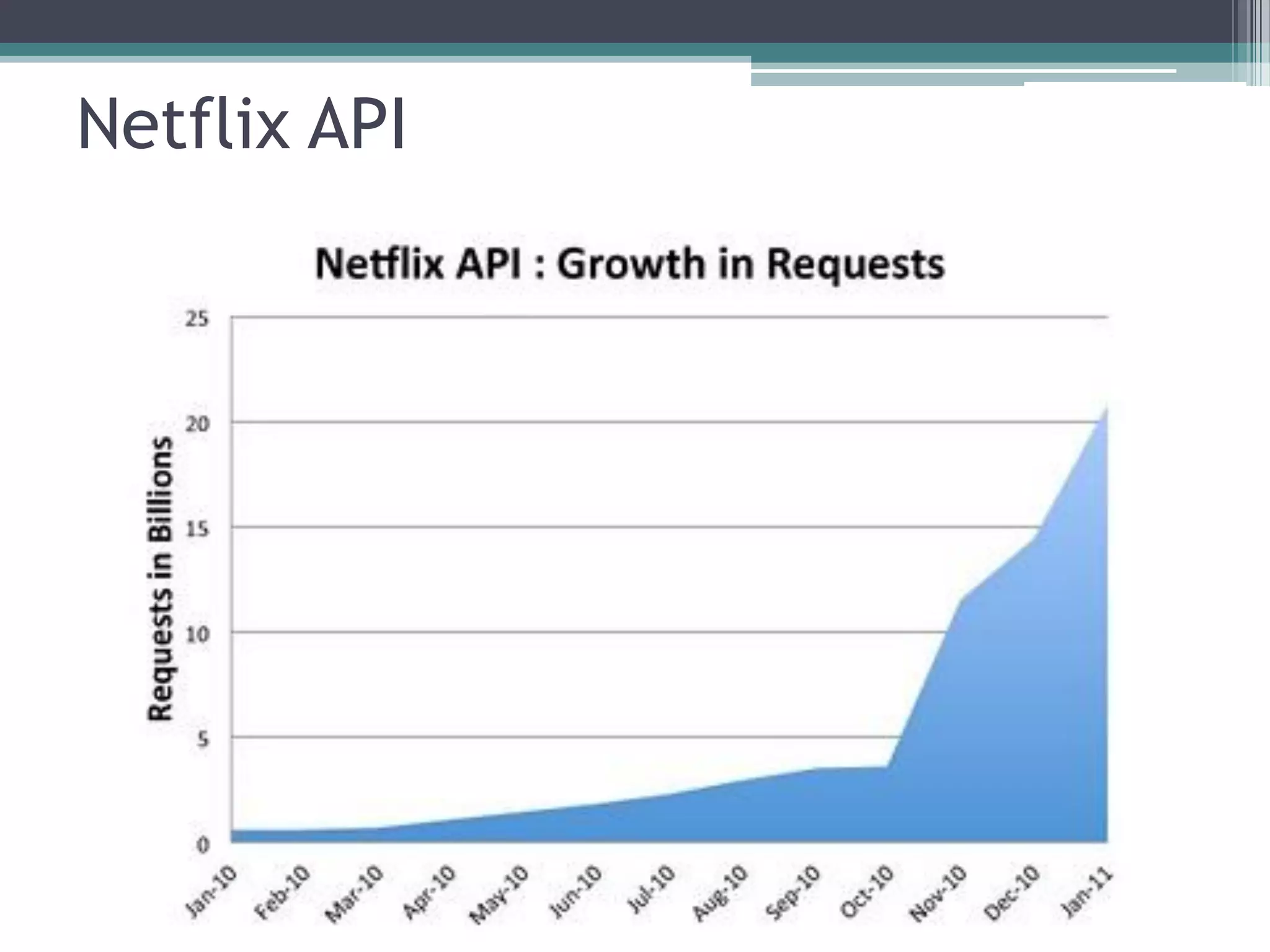
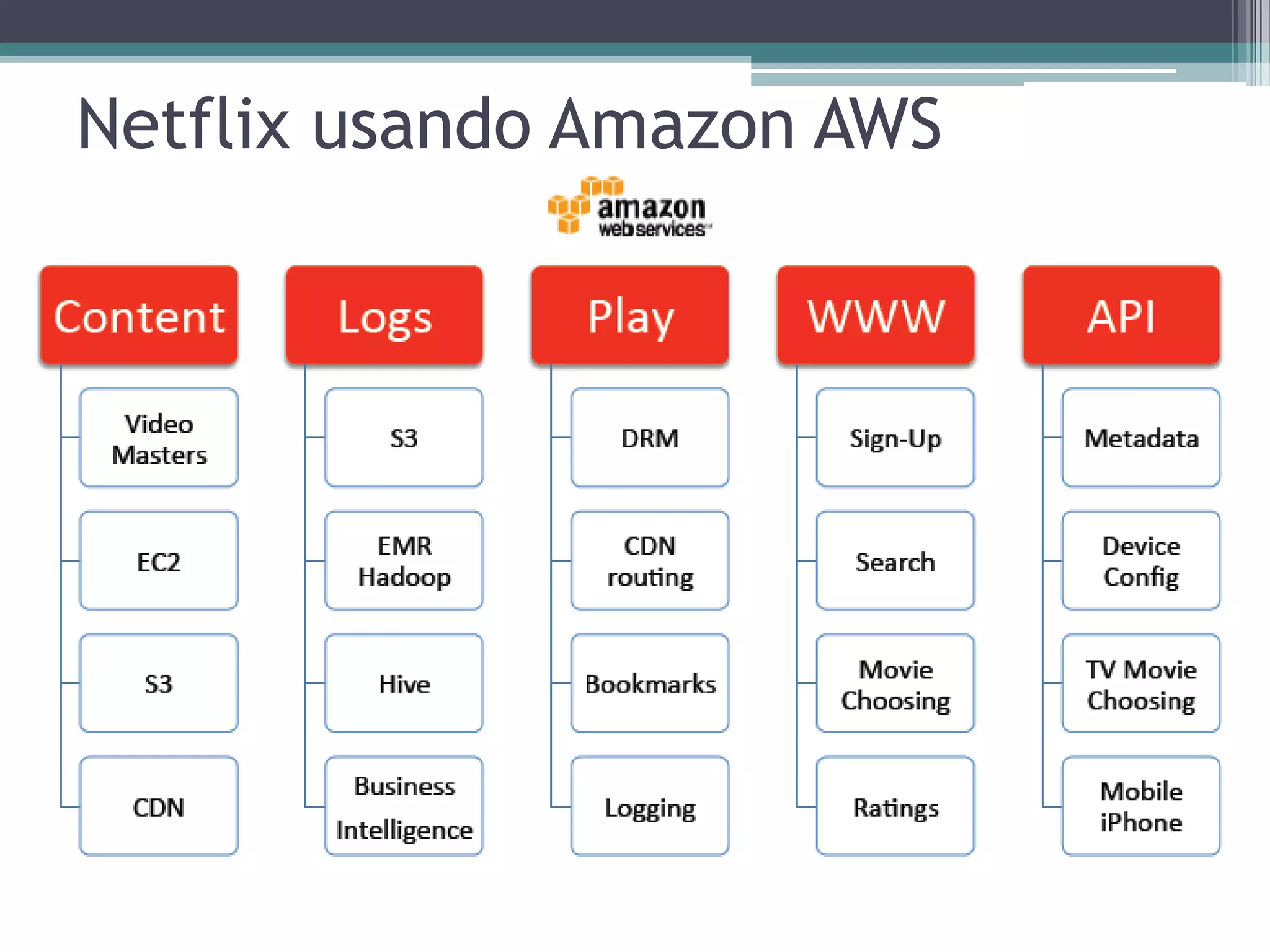

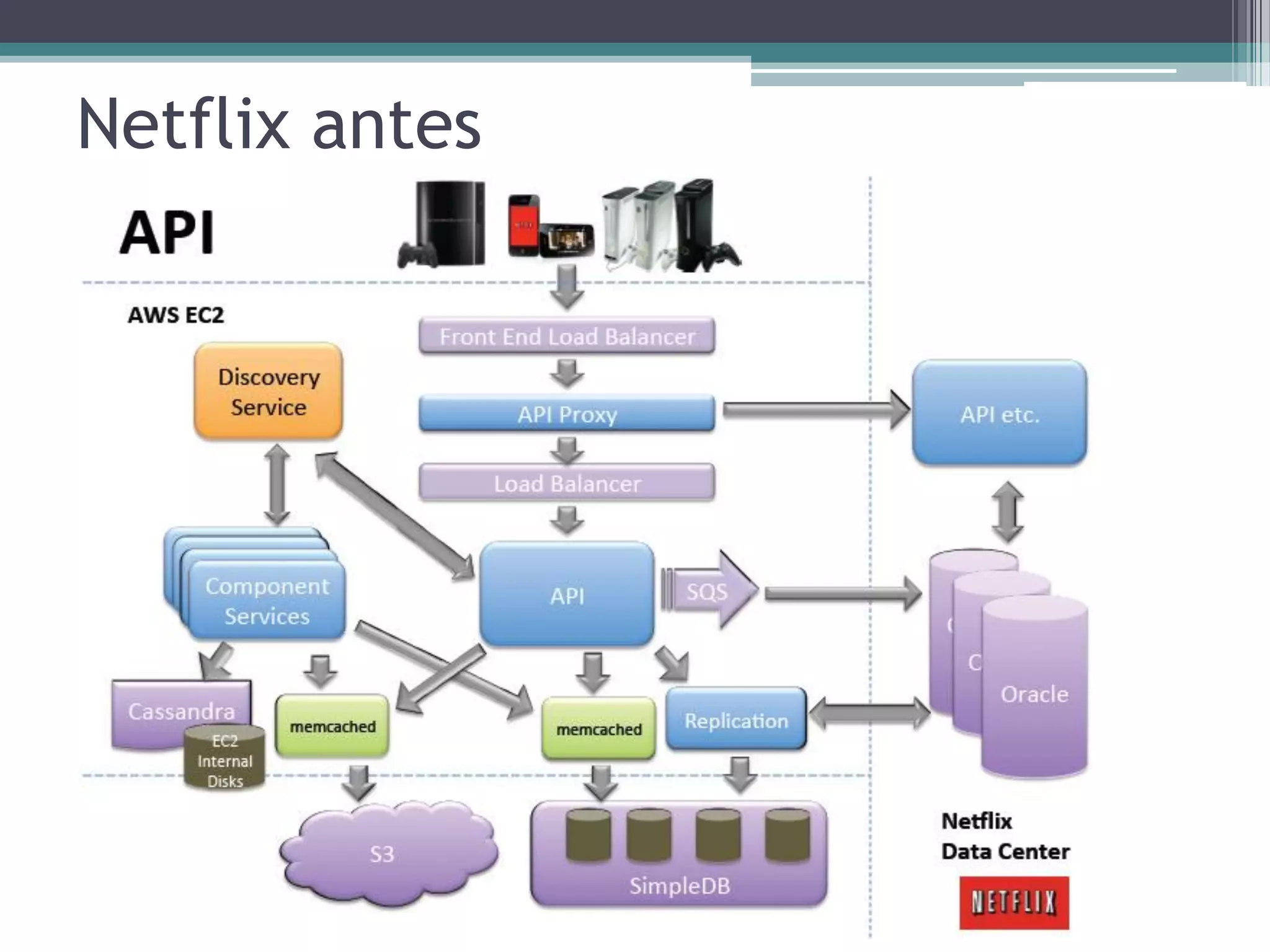
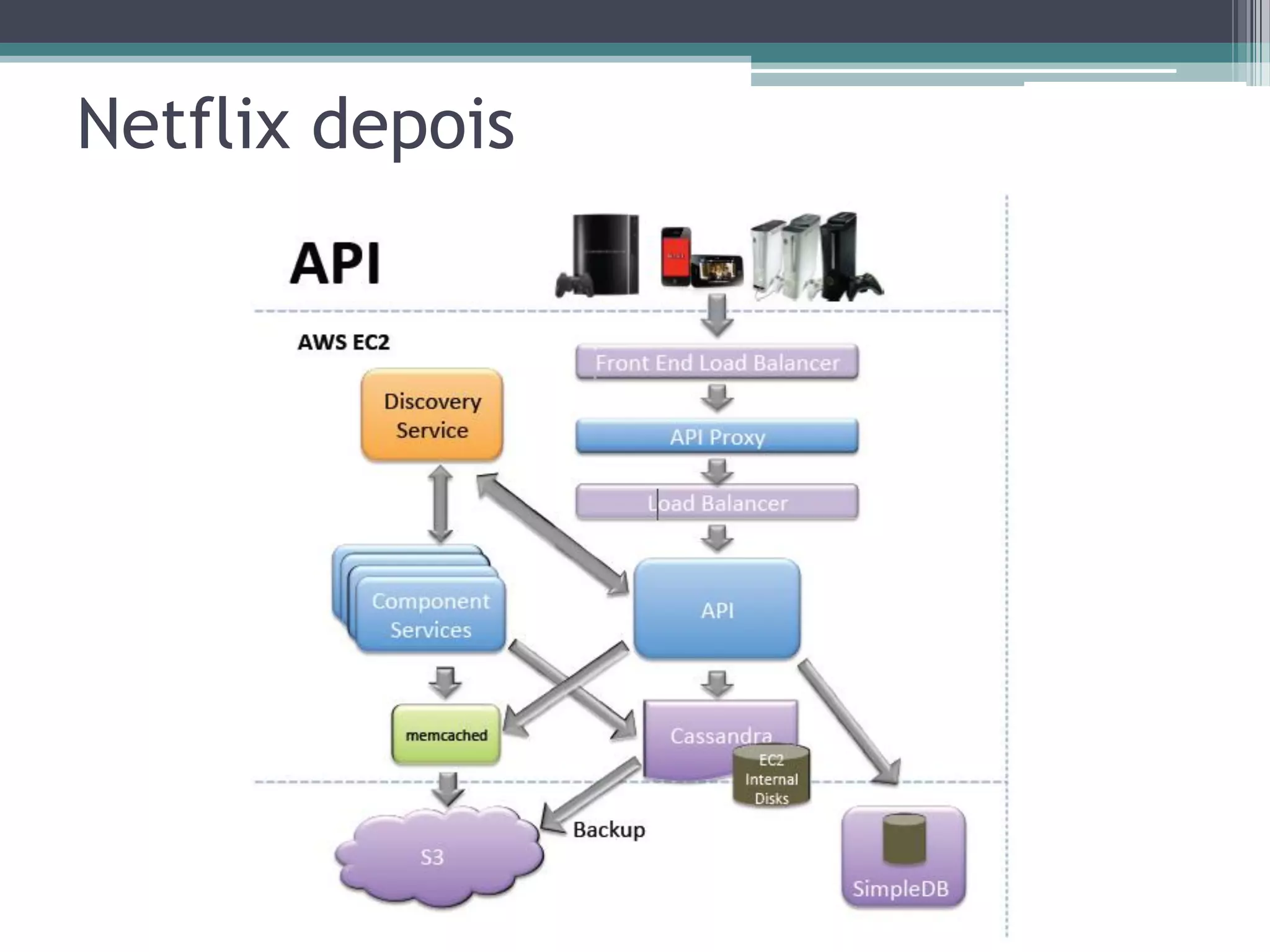
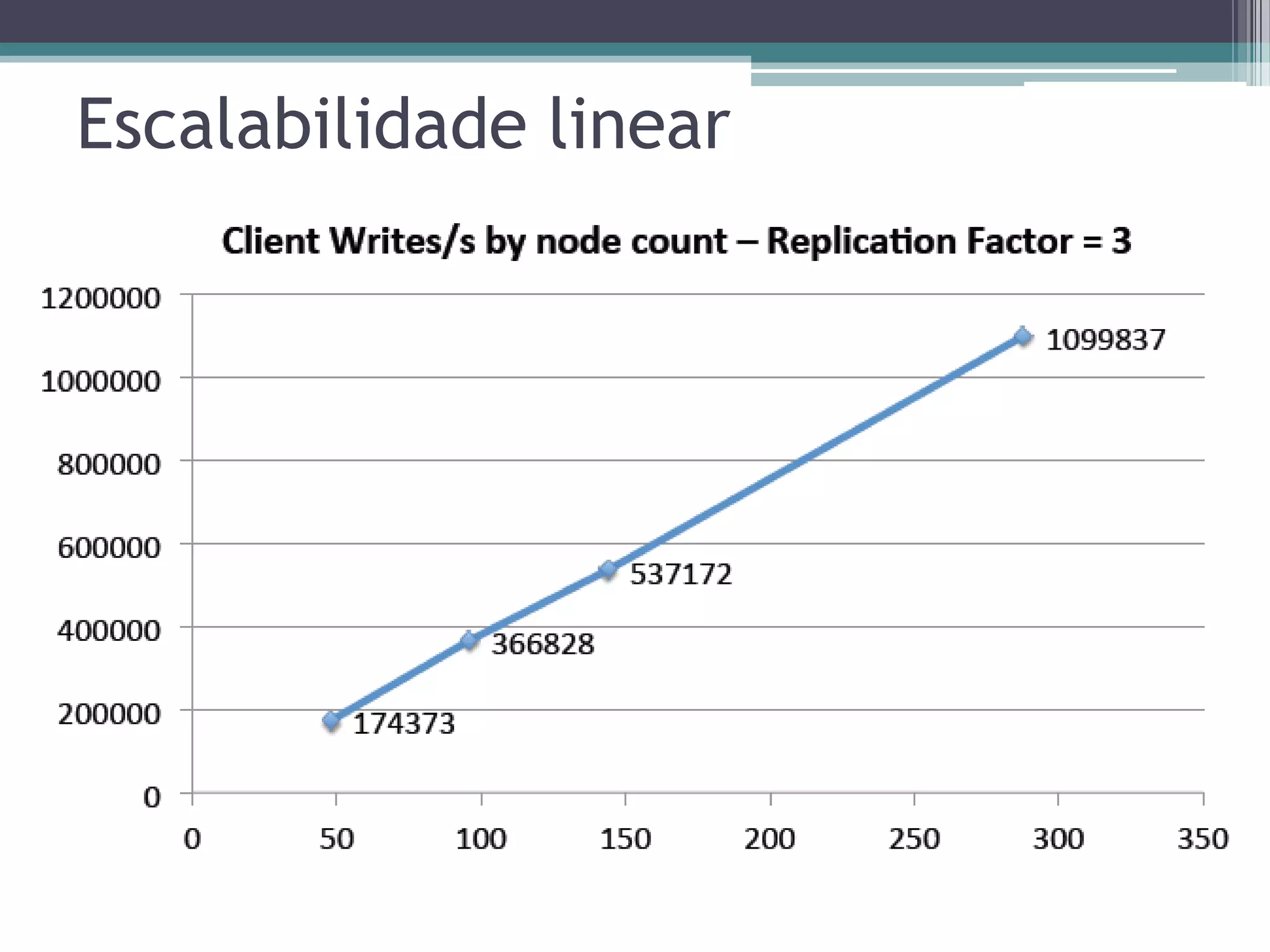
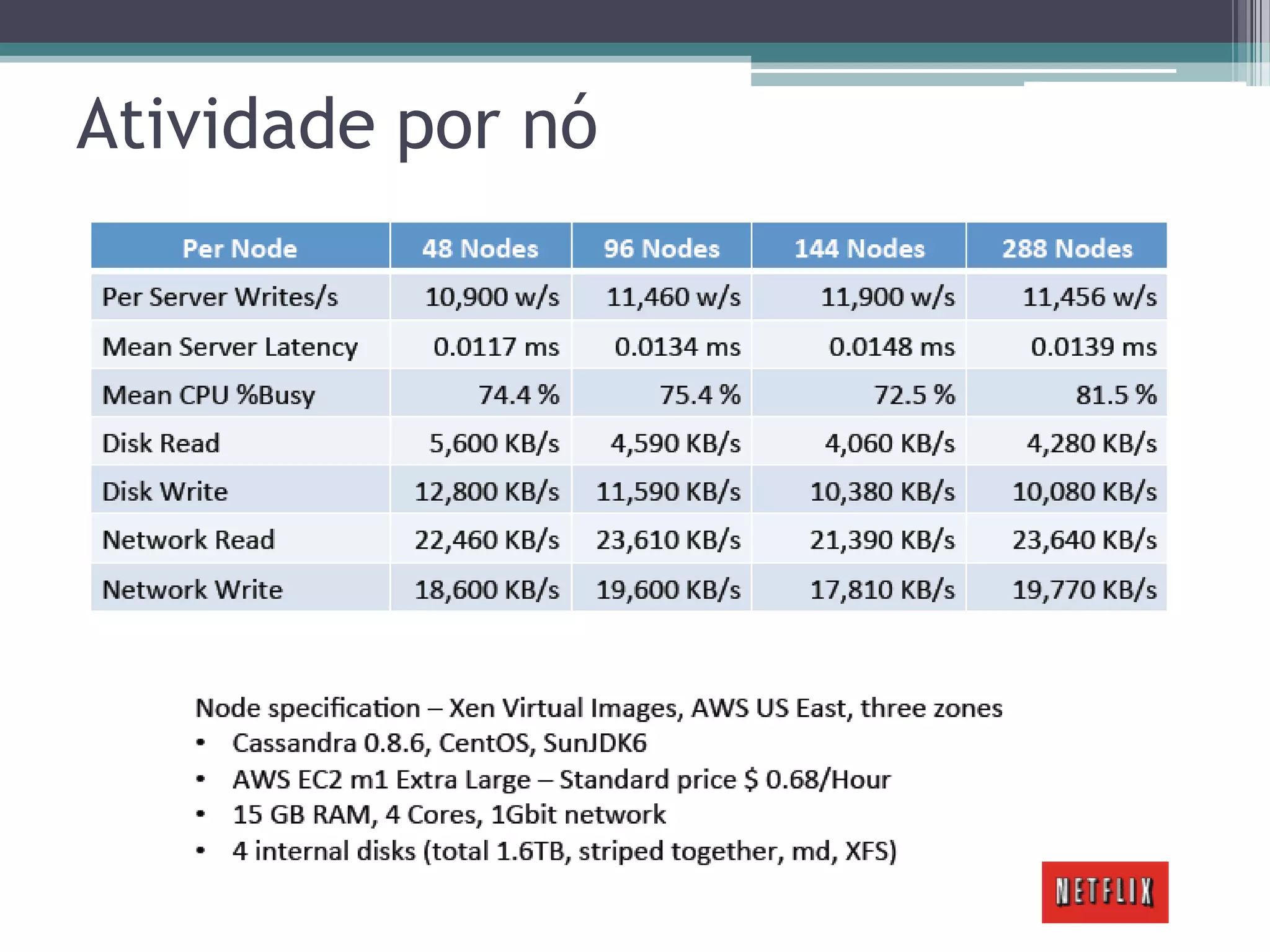







O documento resume a evolução dos sistemas de gerenciamento de dados, desde os primórdios dos bancos de dados até os sistemas atuais de grande escala. Começa com os modelos de rede e ISAM nos anos 1960, passa pelo modelo relacional e sistemas como System R e Ingres, a popularização dos SGBDs relacionais, e as limitações impostas pelas novas aplicações da Web. Apresenta então o renascimento dos sistemas de armazenamento chave-valor, projetos como Bigtable e Dynamo, e a categoria de sistemas







































































































