Baixado 67 vezes







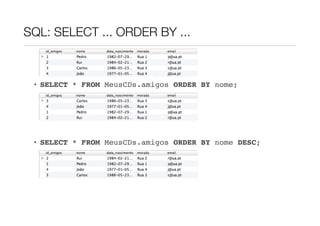
![SQL: SELECT ... ORDER BY ...
Os resultados finais podem ser ordenados pelos valores de uma ou mais
colunas
• SELECT nome_colunas
FROM nome_tabela
...
ORDER BY nome_coluna(s) [ASC|DESC]
A ter em atenção:
• a coluna que tem mais prioridade é a que aparece primeiro na lista de
colunas
• por defeito, a ordenação é ascendente](https://image.slidesharecdn.com/06tlm41213-130305043324-phpapp01/85/LabMM4-T06-12-13-Auto-associacoes-e-Introducao-ao-SQL-12-320.jpg)

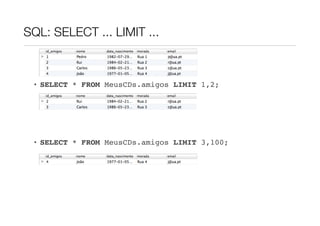

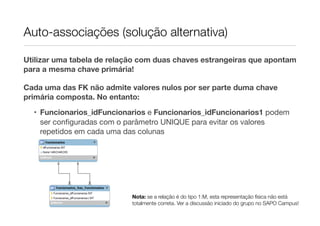
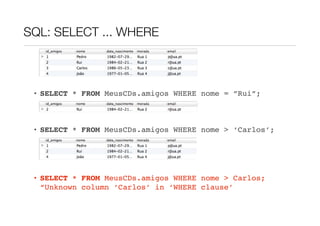
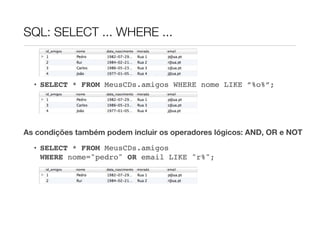
O documento descreve como modelar relações hierárquicas em bases de dados usando auto-associações, onde funcionários podem ter um superior hierárquico. Explica como usar uma chave estrangeira nula para permitir que funcionários não tenham superior, e como usar uma tabela de relação com duas chaves estrangeiras para representar relações de 1:M, 1:1 ou M:M. Também fornece um resumo das principais cláusulas SQL como SELECT, WHERE, ORDER BY e LIMIT.



























































































