Baixado 38 vezes





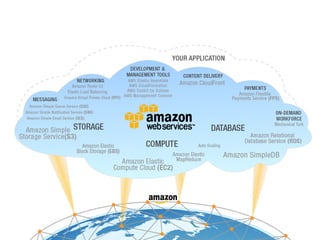


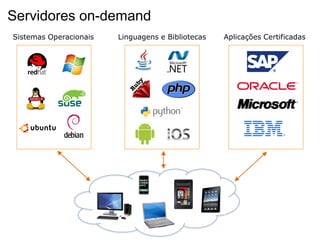





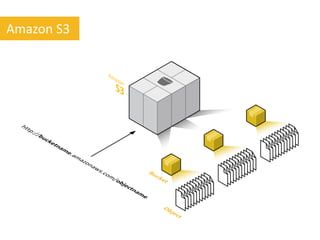

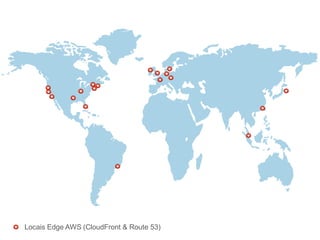
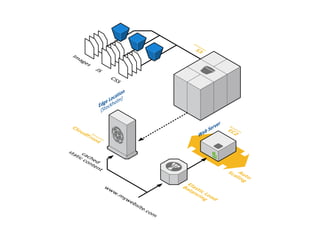

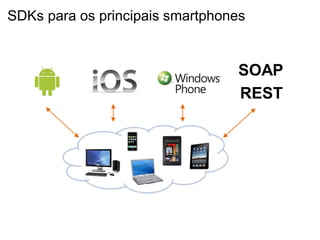


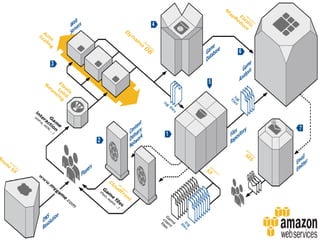






O documento discute o desenvolvimento de aplicações Android na nuvem usando serviços da AWS como EC2, S3, DynamoDB e CloudFront. Ele fornece exemplos de código para armazenar dados em bancos de dados NoSQL na nuvem e carregar arquivos em buckets S3. O documento defende que a nuvem traz liberdade e democratização ao permitir o desenvolvimento de aplicações móveis escaláveis de forma elástica e on-demand.































































