Baixado 50 vezes




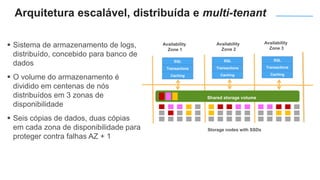
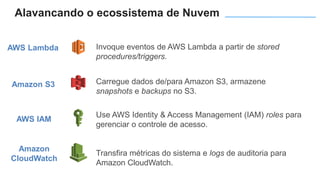
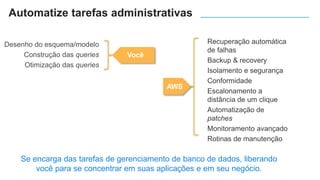





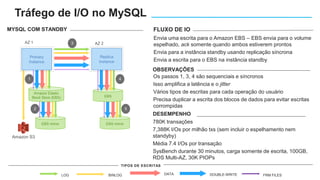
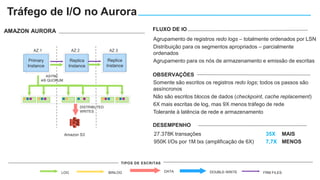
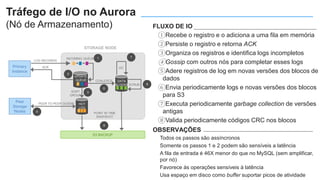
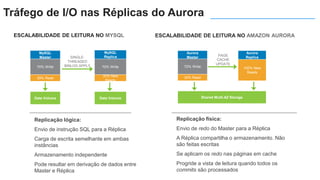
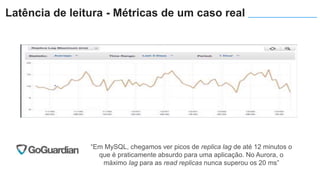
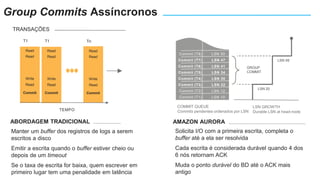
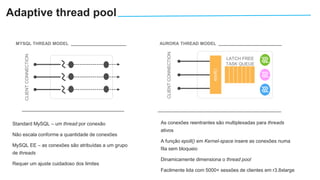
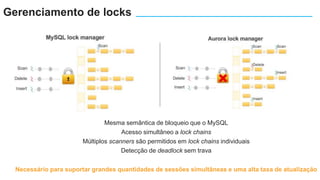
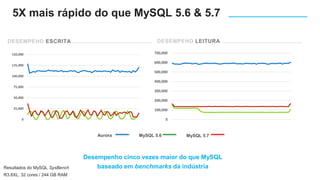
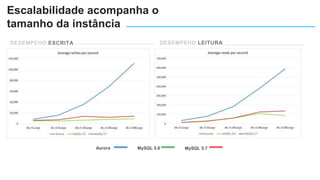
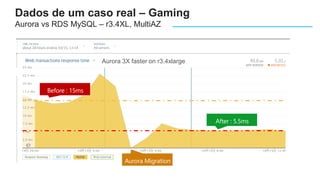

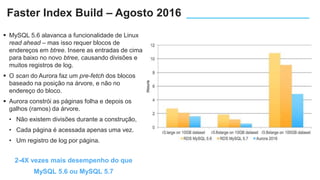

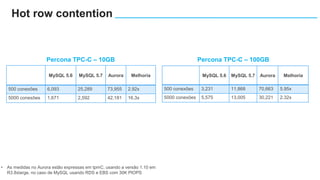
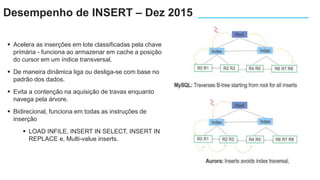


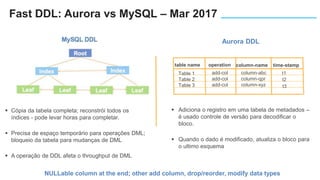



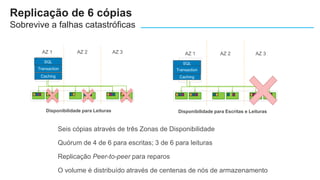
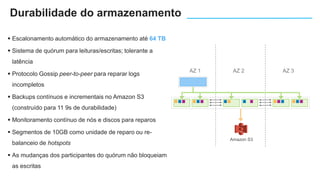
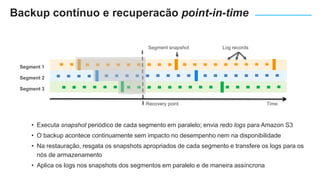

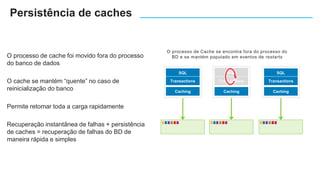
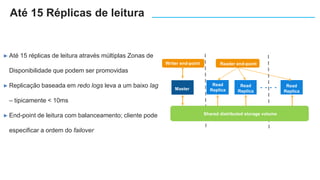
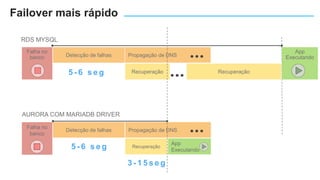
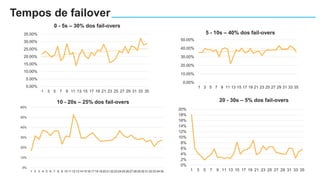


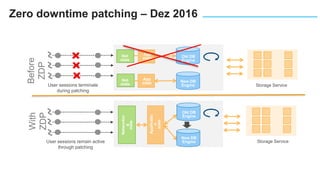

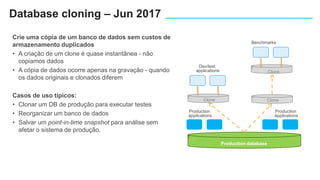
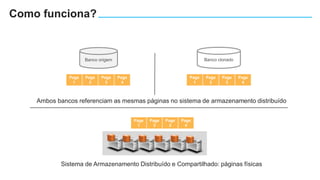
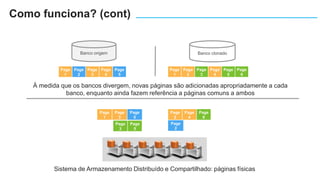
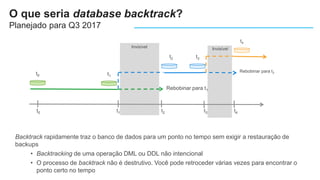
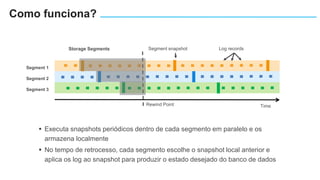
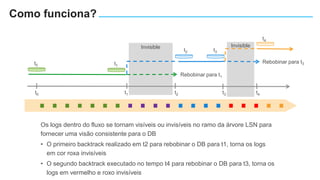


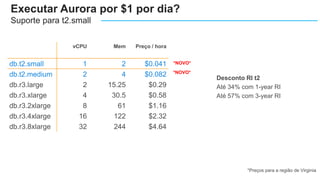
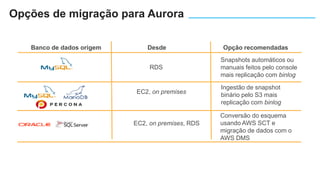





O documento apresenta o Amazon Aurora, um banco de dados relacional gerenciado pela AWS. O Aurora oferece desempenho 5x maior que o MySQL com disponibilidade e segurança equivalentes aos bancos de dados comerciais. O documento discute as melhorias de desempenho e disponibilidade do Aurora, incluindo índices mais rápidos e gerenciamento de bloqueios aprimorado.



































































