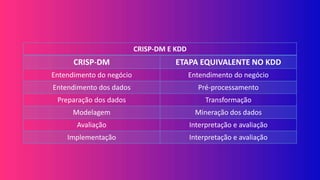
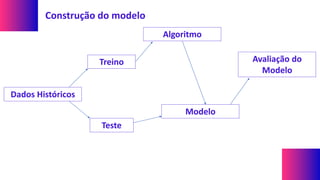
O documento explora conceitos e técnicas de mineração de dados e aprendizado de máquina em relação ao big data, destacando a importância de transformar grandes volumes de dados em informação e conhecimento. Ele discute diferentes tipos de dados, processos de mineração e métodos de análise, incluindo a comparação entre os padrões CRISP-DM e KDD. A aplicação prática de aprendizado de máquina é exemplificada no contexto da classificação de clientes em situações de crédito, demonstrando a utilização de modelos para prever comportamentos futuros com base em dados históricos.