Baixado 46 vezes










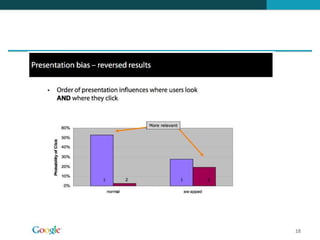







![Ordenação independente do docID
Ordenar os documentos nas listas de postings de acordo com o
PageRank: g(d1) > g(d2) > g(d3) > . . .
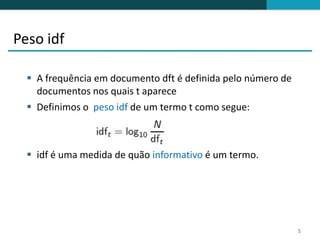
Definir o score composto de um documento:
net-score(q, d) = g(d) + cos(q, d)
Suponha: (i) g → [0, 1]; (ii) g(d) < 0.1 para o documento d que
estamos processando; (iii) o menor ranking dos top k
documentos encontrados até agora é 1.2
Portanto, todos os próximos scores serão < 1.1.
Já encontramos os top k resultados e podemos parar o
processamento e ignorar o restante da lista de posting.
28](https://image.slidesharecdn.com/ordados-aula08-130204050032-phpapp02/85/Calculo-de-Score-28-320.jpg)
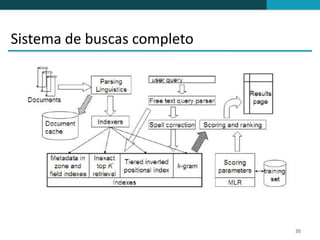

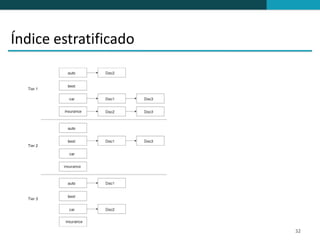

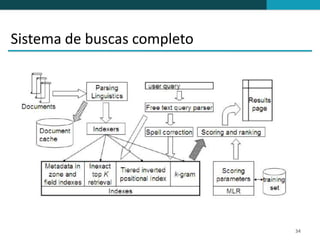



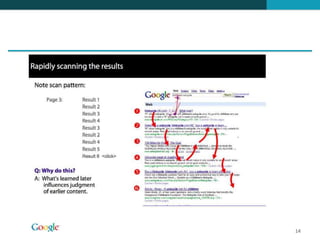
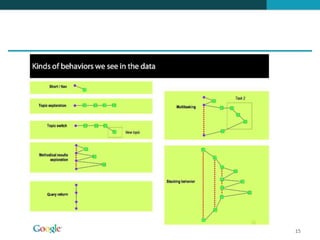
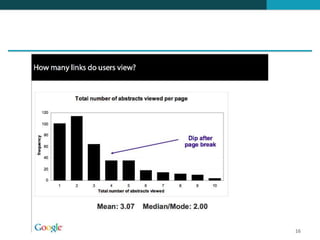
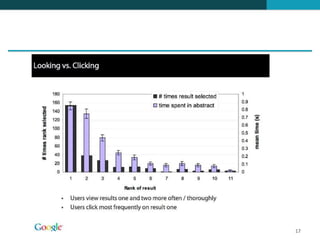
❶ O documento discute técnicas de ranqueamento e classificação de resultados de busca, incluindo cálculo de escores usando pesos tf, idf e tf-idf. ❷ É mostrado que classificação é importante porque reduz um grande conjunto de resultados para um menor mais relevante, e que usuários tipicamente só examinam os primeiros 1-3 resultados. ❸ São apresentadas técnicas como uso de heap binário para selecionar os top k documentos e ordenação independente do id para permitir terminação precoce da busca.













































































