Elasticsearch é um mecanismo de busca distribuído baseado no Lucene que fornece pesquisa de texto completo em documentos JSON de forma escalável. Ele indexa documentos sem esquema e fornece uma interface RESTful para pesquisas.
‘’
“Elasticsearch is asearch server based
on Lucene. It provides a distributed,
multitenant-capable full-text search
engine with a RESTful web interface
and schema-free JSON documents.
Elasticsearch is developed in Java and
is released as open source under the
terms of the Apache License.”
Banon. Shay
4
5.
Índice invertido
Term Doc_1Doc_2 Doc_3
Waldemar x x
Bicicleta x x x
Avião x
5
1. Score
1.1. Bicicleta 3
1.2. Waldemar 2
1.3. Avião 1
Como o Lucenevê os documentos
● O Lucene não separa tipos nem objetos.
● O Lucene é apenas chave e valor.
● Como os objetos são salvos
○ produto.nome = "test"
8
O que écache?
Resultados guardados em memória, desta maneira o shard
não precisa calcular as resultados novamente nem fazer o
calculo de relevância.
15
Shard Level cache
Quandouma busca é executada dentro de um index, cada
shard executa sua busca localmente e calcula seu
resultado. Esse resultado é mesclado com o resultado
global no coordinating node.
17
18.
Filter Caching
Filtros nãocalculam relevância e não passam por análise,
dessa maneira eles podem ser cacheados pois na maioria das
vezes eles devolvem o mesmo resultado.
18
19.
Filtros que nãosão cacheados
Alguns filtros não são cacheados por padrão pois são
usados para buscas que mudam a cada chamada como
por exemplo AND, OR e RANGE.
19
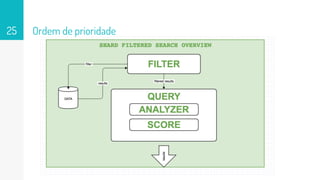
O que sãoQueries?
● Queries determinam como a busca deve se comportar e
garantem que o conteúdo buscado vai ser procurado e
comparado da maneira certa.
● Elas conseguem calcular o quão relevante aquele
resultado é para a busca que foi feita.
21
22.
Quando usar Queries?
●Quando relevância é importante
● Quando é necessário mudar as regras do termo como
linguagens e sinônimos
● Quando o full text search é importante
● Quando analisar os termos é importante
22
Score
Score é relacionadoa relevância do resultado de uma busca
para com o que foi buscado. São usados dois padrões para
determinar relevância em uma Query que são TF e IDF.
27
28.
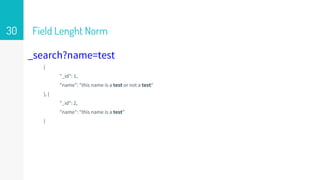
TF - TermFrequency
_search?name=test
{
"_id": 1,
"name": "this name is a test or not a test"
}
2
28
29.
IDF - InverseDocument Frequency
_search?name=test
{
"_id": 1,
"name": "this name is a test or not a test"
}, {
"_id": 2,
"name": "this name is a test"
}
2
1
29
O PROBLEMA DOSIZE/FROM
● Cada shard calcula seu size
● Cada shard gera seus próprios resultados limitados
● Todos os resultados são mesclados no coordinator node
● O shard precisa percorrer os dados
○ Imagine que queremos os resultados de 1010 até
1020
■ Cada shard vai produzir 1020 resultados
○ O cordinator node vai receber 5100 resultados caso
tenha 5 shards
■ Vai remover 5090 resultados para produzir
apenas 10.
33
34.
QUE TAL SCAN/SCROLL?
●A scroll api é usada pelo elastic para buscar grandes números de documentos.
○ Uma busca por scroll permite que façamos uma busca inicial e continuemos
buscando até que não tenha mais resultados.
■ Mais ou menos como um cursor em bancos de dados tradicionais
○ Depois da busca inicial ser feita as próximas não irão pegar atualizações de
documentos caso tenha neste intervalo.
● O scan permite que desativemos o sorting do elastic e apenas retorne os
proximos dados do scroll.
● Para usar basta fazer uma busca colocando o search_type como scan e passando
o parâmetro scroll dizendo quanto tempo esse scroll pode ficar aberto.
34
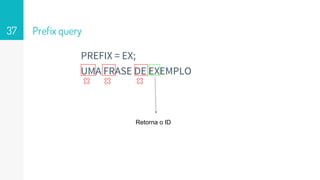
Prefix Query
● Prefixqueries rodam no term level ou seja não passam por analyzers.
● Por padrão não geram relevância, é mais como um filtro do que uma query.
36
WILDCARD e REGEXPquery
● Funcionam da mesma maneira que a Prefix Query
● Aceitam expressões regulares como * [0-9]
38
39.
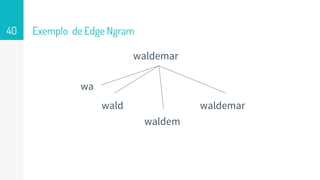
NGRAMS
● Buscas baseadasem digitação são incrementais
○ exemplo: waldemar = w wa wal wald walde waldem waldema
waldemar
● Só podem ser buscadas coisas que estão indexadas
○ Por que não indexar pedaços de terms?
39

































![WILDCARD e REGEXP query
● Funcionam da mesma maneira que a Prefix Query
● Aceitam expressões regulares como * [0-9]
38](https://image.slidesharecdn.com/elasticsearch-tdc-160707135109/85/Elasticsearch-de-dentro-para-fora-38-320.jpg)