Baixar para ler offline



![Ementa da disciplina
Temas abordados
Introdução à econometria: uma abordagem moderna – Tradução da 6ª
edição norte-americana
Jeffrey M. Wooldridge
▶ Cap 13: agrupamento de cortes transversais ao longo do tempo: métodos
simples de dados em painel.
▶ Cap 14: métodos avançados de dados em painel.
▶ Cap 15: estimação de variáveis instrumentais e mínimos quadrados em dois
estágios.
▶ Cap 16: modelos de equações simultâneas.
▶ Cap 17: modelos com variáveis dependentes limitadas e correções da seleção
amostral
Avaliação econômica de projetos sociais / Betânia Menezes Filho]. – São
Paulo : Fundação Itaú Social, 2016.
▶ Avaliação de Impacto de Programas Sociais.Por que, para que e quando fazer?
▶ Modelo de Resultados Potenciais.
▶ Método de Aleatorização.
▶ Diferenças em Diferenças.
▶ Variáveis Instrumentais.
▶ Regressão Descontínua.
Renan Oliveira Regis Econometria 2 4 / 150](https://image.slidesharecdn.com/cadeiraeconometria2-221110121854-7201117f/85/Cadeira_Econometria_2-pdf-4-320.jpg)









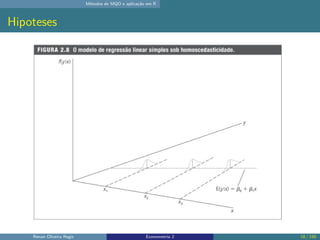
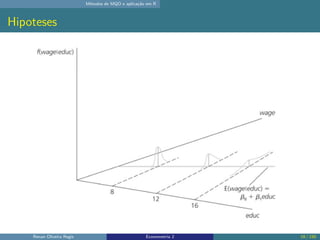
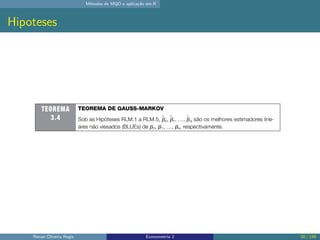
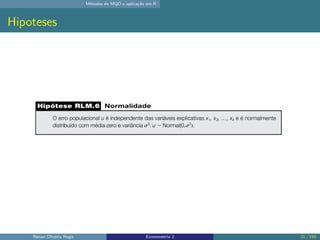
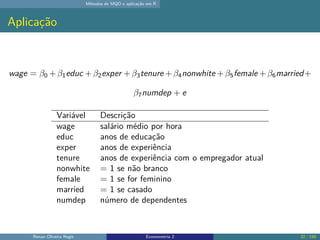

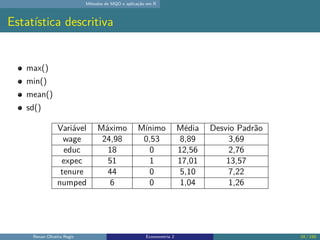


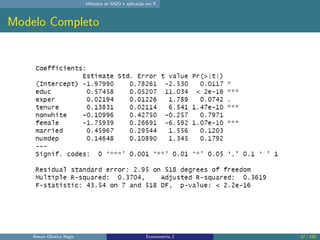




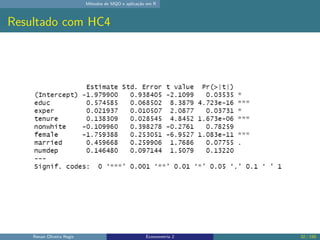
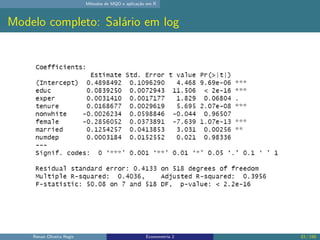


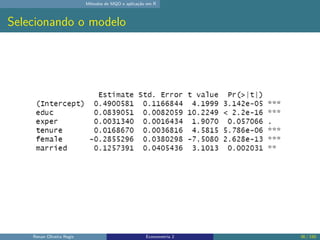
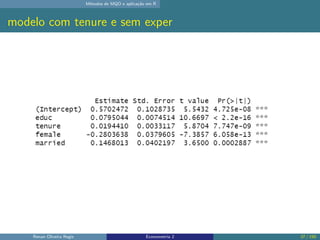












































































































O documento discute os seguintes tópicos: (1) ementa da disciplina de econometria, abordando métodos como mínimos quadrados ordinários, dados em painel e variáveis instrumentais; (2) aplicação dos métodos de mínimos quadrados ordinários em R, incluindo derivação das estimativas, hipóteses e exemplo; (3) seleção de modelo usando variáveis como educação, experiência e outros.




















![[Grupo 7] Conceitualização do Modelo.pptx.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/grupo7conceitualizaodomodelo-250829005610-621143ec-thumbnail.jpg?width=640&height=640&fit=bounds)






