Transferir como PDF, PPTX














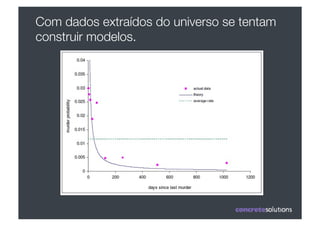





















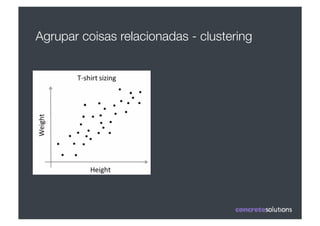
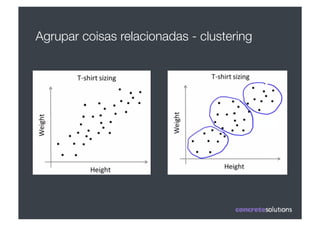

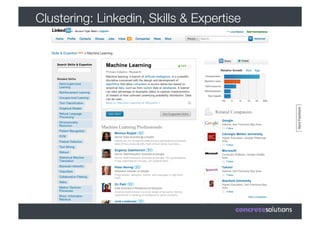

























































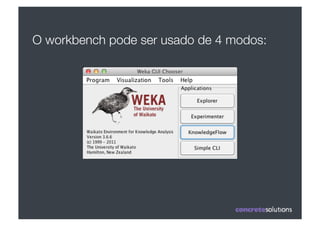



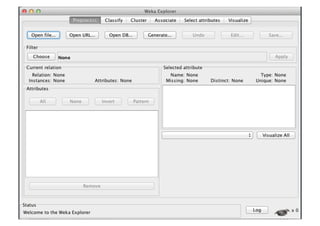

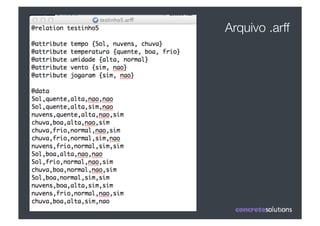
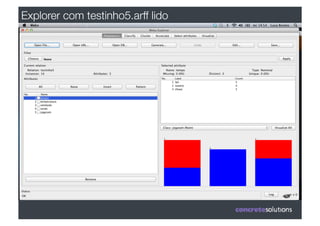
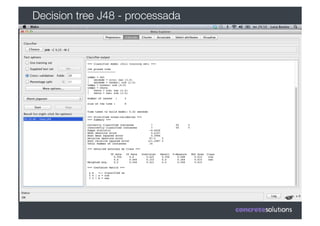



















1) O documento discute machine learning e apresenta o Weka, uma ferramenta de código aberto para aprendizado de máquina. 2) O Weka contém algoritmos de aprendizado supervisionado e não supervisionado, pré-processamento de dados e interfaces gráficas. 3) O documento explica como usar o Weka para classificação, clustering, seleção de atributos e experimentação com diferentes algoritmos.

















































