Baixado 22 vezes







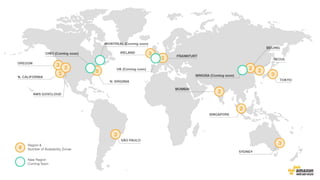
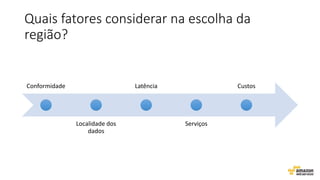


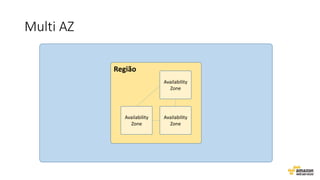
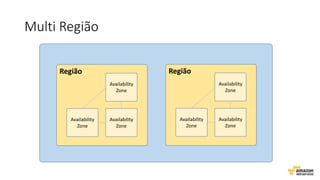




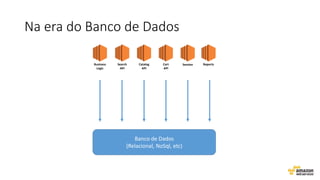

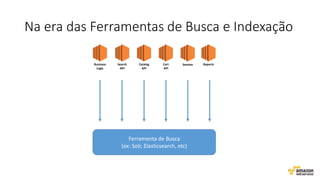


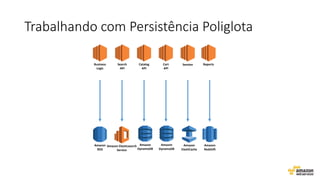





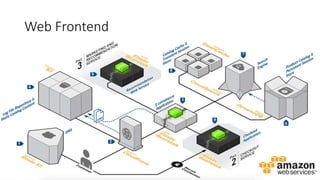
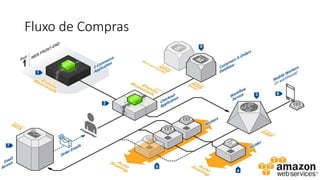
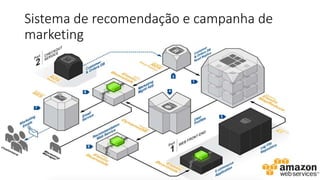








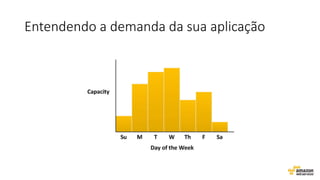
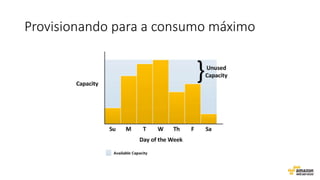
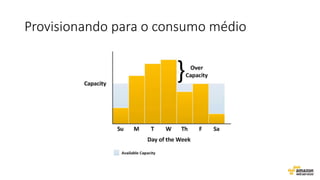
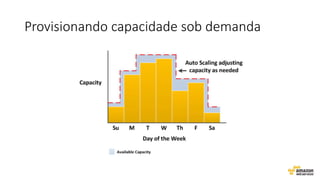
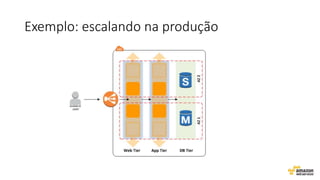







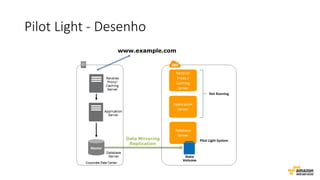
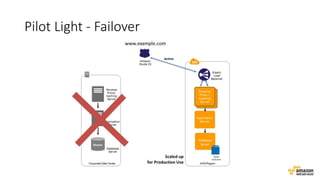
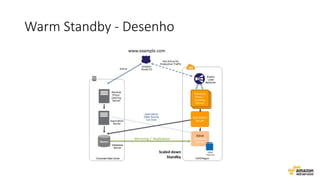
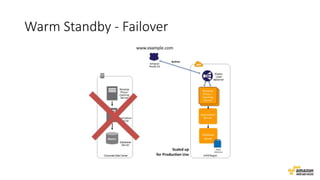
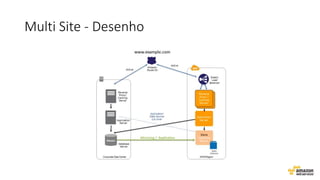
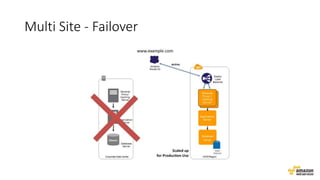


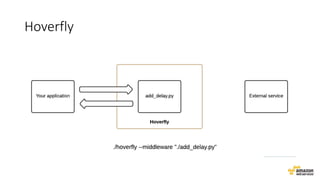
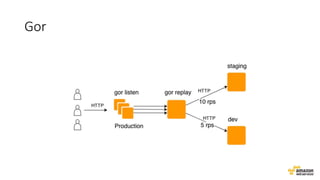














O documento aborda estratégias para gerenciar e escalar um ecommerce durante a Black Friday na nuvem, enfatizando a importância de escolher a região correta, usar serviços gerenciados e aplicar boas práticas de segurança e escalabilidade. Apresenta o Well Architected Framework como uma ferramenta fundamental para garantir segurança, confiabilidade, desempenho e otimização de custos. Também discute a necessidade de um plano de continuidade, monitoramento eficiente e suporte adequado para o sucesso operacional.














































































