Baixado 16 vezes

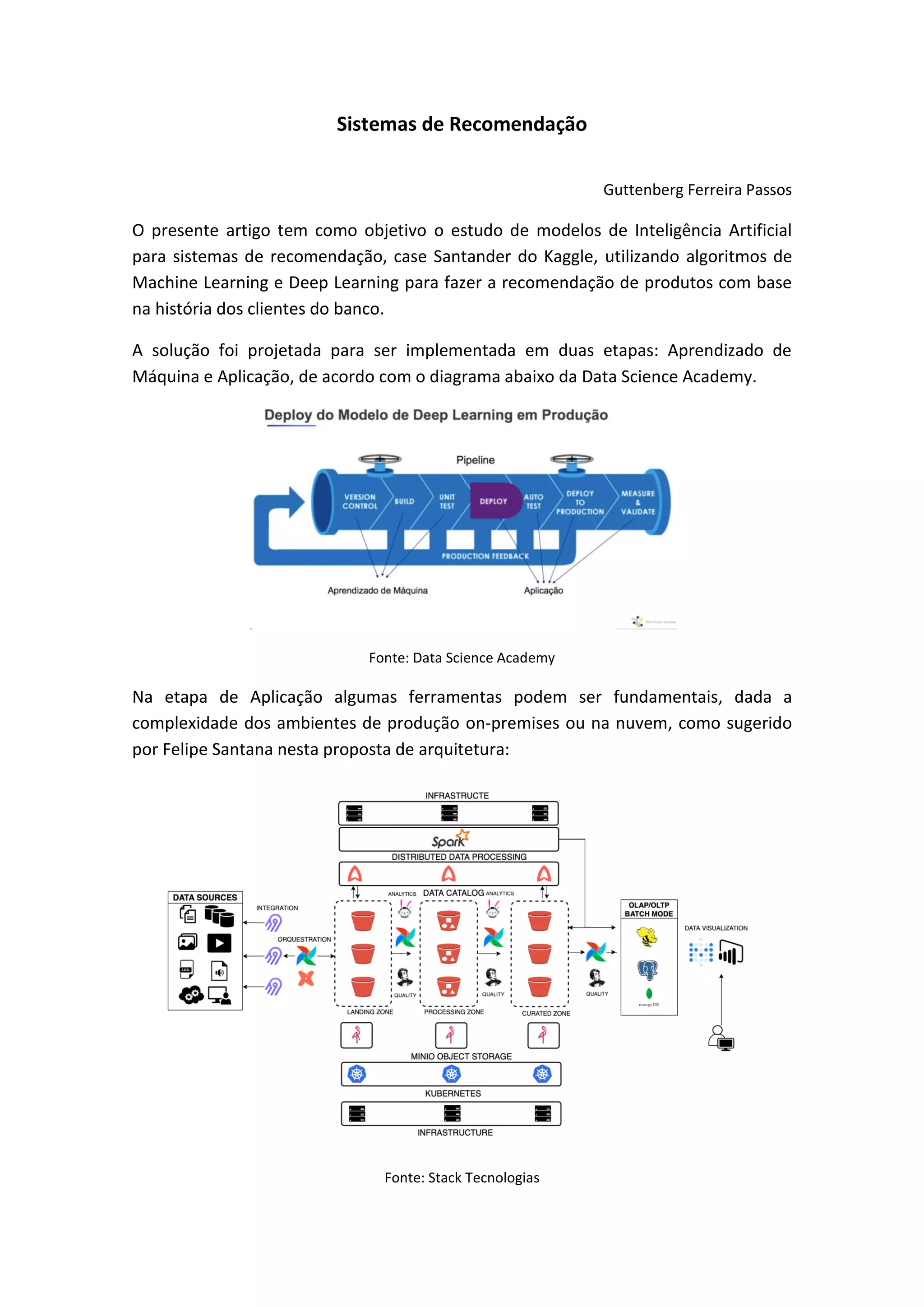




![3) Elaboração de modelo de Deep Learning.
Utilizou-se a modelagem do Autoencoder para Filtragem Colaborativa, no modelo de
Deep Learning, baseado na arquitetura da solução Deep RecSys com Autoencoders
(AE), de Marlesson Santana.
O princípio da Filtragem Colaborativa é utilizar a informação das interações que
ocorrem entre os usuários e os conteúdos para que, de forma coletiva, essa
informação seja útil para inferir as preferências dos indivíduos. Dessa forma é possível
gerar recomendações como: “usuários que gostaram do Jogo B também gostaram de
Jogo D”.
Matriz de Interação, cada registro é o valor associado a interação do usuário com o
conteúdo.
Algoritmo de Deep Learning:
# Input
input_layer = Input(shape=(X.shape[1],), name='UserScore')
# Encoder
enc = Dense(512, activation='selu', name='EncLayer1')(input_layer)
# Latent Space
lat_space = Dense(256, activation='selu', name='LatentSpace')(enc)
lat_space = Dropout(0.8, name='Dropout')(lat_space) # Dropout
# Decoder
dec = Dense(512, activation='selu', name='DecLayer1')(lat_space)
# Output
output_layer = Dense(X.shape[1], activation='linear', name='UserScorePred')(dec)
# this model maps an input to its reconstruction
model = Model(input_layer, output_layer)
model = autoEncoder(X)
model.compile(optimizer = Adam(lr=0.0001), loss='mse')
model.summary()](https://image.slidesharecdn.com/sistemasderecomendao-220714133117-95f8eb26/85/Sistemas-de-Recomendacao-6-320.jpg)
![Model: "model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
UserScore (InputLayer) [(None, 24)] 0
_________________________________________________________________
EncLayer1 (Dense) (None, 512) 12800
_________________________________________________________________
LatentSpace (Dense) (None, 256) 131328
_________________________________________________________________
Dropout (Dropout) (None, 256) 0
_________________________________________________________________
DecLayer1 (Dense) (None, 512) 131584
_________________________________________________________________
UserScorePred (Dense) (None, 24) 12312
=================================================================
Total params: 288,024
Trainable params: 288,024
Non-trainable params: 0
Treinamento:
hist = model.fit(x=X, y=y, epochs=10, batch_size=64, shuffle=True, validation_split=0.1)
Epoch 1/10
87843/87843 [==============================] - 468s 5ms/step - loss: 0.0050 - val_loss: 2.5569e-04
Epoch 2/10
87843/87843 [==============================] - 463s 5ms/step - loss: 0.0016 - val_loss: 2.1522e-04
Epoch 3/10
87843/87843 [==============================] - 466s 5ms/step - loss: 0.0014 - val_loss: 1.7110e-04
Epoch 4/10
87843/87843 [==============================] - 466s 5ms/step - loss: 0.0012 - val_loss: 1.3251e-04
Epoch 5/10
87843/87843 [==============================] - 467s 5ms/step - loss: 0.0010 - val_loss: 1.1520e-04
Epoch 6/10
87843/87843 [==============================] - 468s 5ms/step - loss: 9.3472e-04 - val_loss: 8.4248e-05
Epoch 7/10
87843/87843 [==============================] - 468s 5ms/step - loss: 8.7468e-04 - val_loss: 7.6334e-05
Epoch 8/10
87843/87843 [==============================] - 470s 5ms/step - loss: 8.3305e-04 - val_loss: 6.8077e-05
Epoch 9/10
87843/87843 [==============================] - 466s 5ms/step - loss: 8.0756e-04 - val_loss: 7.1352e-05
Epoch 10/10
87843/87843 [==============================] - 466s 5ms/step - loss: 7.8332e-04 - val_loss: 6.1677e-05
A quantidade de épocas, tamanho do batch, entre outros parâmetros vai depender do
problema também. O ideal é treinar até que a curva de loss se estabilize e o erro pare
de reduzir:
Recomendação
Produtos adquiridos anteriormente pelo cliente
recommender_for_user(
user_id = 918221,
interact_matrix = users_items_matrix_df,](https://image.slidesharecdn.com/sistemasderecomendao-220714133117-95f8eb26/85/Sistemas-de-Recomendacao-7-320.jpg)


O documento discute sistemas de recomendação utilizando machine learning e deep learning. Ele descreve o pré-processamento de dados, a aplicação de vários algoritmos de machine learning como kNN, XGBoost e random forest, e o desenvolvimento de um modelo de autoencoder para filtragem colaborativa usando deep learning. O documento conclui que o naive bayes teve o melhor desempenho entre os algoritmos de machine learning, mas que deep learning é uma boa solução para lidar com grandes volumes de dados.


![[DTC21] Raphael Castilho - Começando com Inteligência Artificial e Machine Le...](https://cdn.slidesharecdn.com/ss_thumbnails/iaemachine-210317154040-thumbnail.jpg?width=640&height=640&fit=bounds)












































