Transferir como PDF, PPTX




















































![Referências Bibliográficas
1. MapReduce: Simplified Data Processing
on Large Clusters [Jeffrey Dean and
Sanjay Ghemawat].
2. Simulação e Estudo da Plataforma
Hadoop MapReduce em Ambientes
Heterogêneos [Wagner Kolberg].](https://image.slidesharecdn.com/mapreduce1-0-120616105845-phpapp01/85/MapReduce-61-320.jpg)

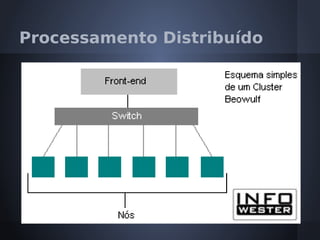
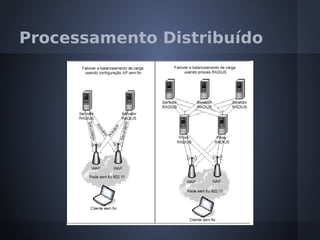
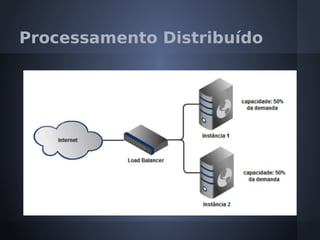
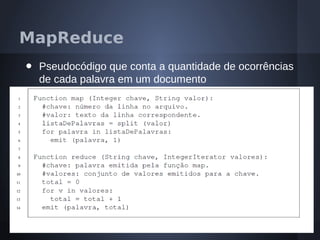
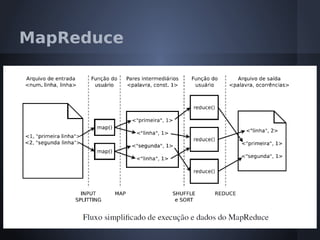
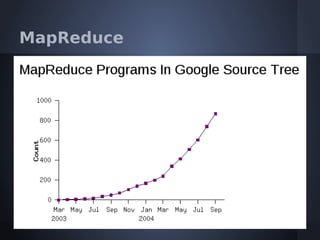
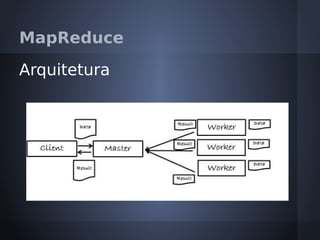
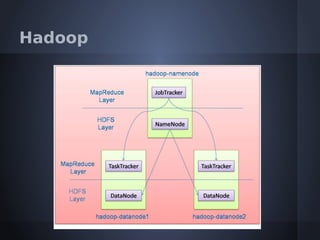
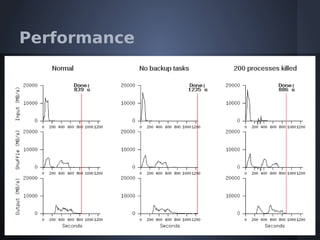
O documento aborda o modelo de programação MapReduce desenvolvido pelo Google para processamento distribuído de grandes volumes de dados, destacando sua arquitetura e relação com o Hadoop. Apresenta a importância do processamento distribuído em ambientes de dados em crescimento acelerado e discute a tolerância a falhas e a performance do sistema. Conclui que o MapReduce simplifica computações em larga escala, permitindo que programadores foquem nos problemas em vez dos detalhes da implementação.



























