Transferir como PDF, PPTX








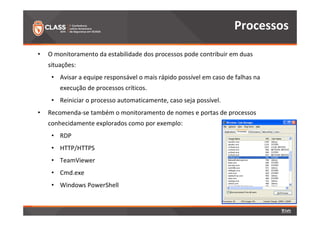




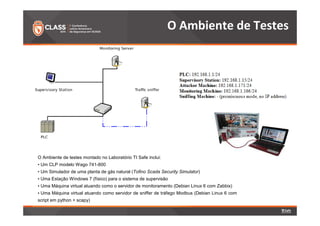
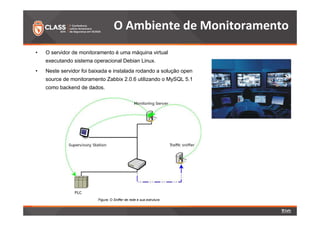




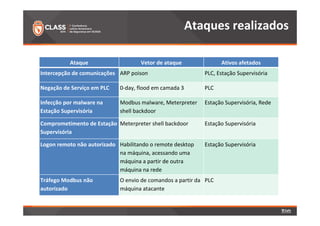

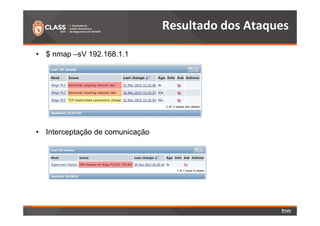
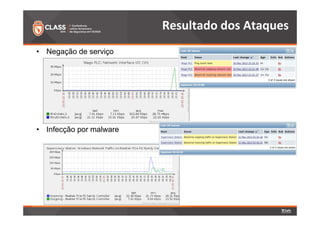
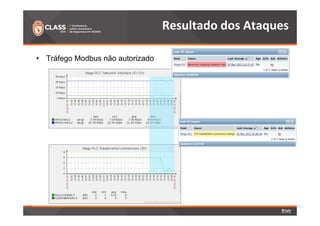



O documento discute a detecção de problemas em redes industriais através de monitoramento contínuo. Os principais pontos abordados são: 1) o que deve ser monitorado em redes de automação, como processos, controladoras e tráfego de dados; 2) a preparação do ambiente de monitoramento usando o software Zabbix; e 3) os resultados do monitoramento de ataques realizados, como negação de serviço e tráfego Modbus não autorizado.



![[White paper] detectando problemas em redes industriais através de monitorame...](https://cdn.slidesharecdn.com/ss_thumbnails/whitepaperdetectandoproblemasemredesindustriaisatravsdemonitoramentocontnuovfinal-130613083901-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)












































![[CLASS 2014] Palestra Técnica - Leonardo Cardoso](https://cdn.slidesharecdn.com/ss_thumbnails/ptclass03-leonardocardoso-141113064607-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)







![[CLASS 2014] Palestra Técnica - Silvio Rocha](https://cdn.slidesharecdn.com/ss_thumbnails/ptclass16-silviorocha-141113070309-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)
























