Transferir como PDF, PPTX










































![WILDCARD e REGEXP query
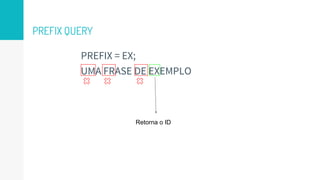
● Funcionam da mesma maneira que a Prefix Query
● Aceitam expressões regulares como * [0-9]](https://image.slidesharecdn.com/ltg-elasticsearchtips-160625203048/85/Elasticsearch-shards-index-filters-and-queries-57-320.jpg)




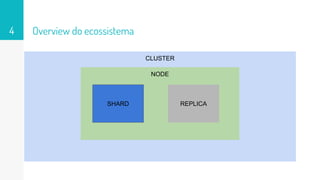
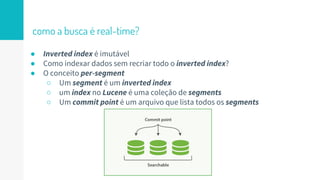
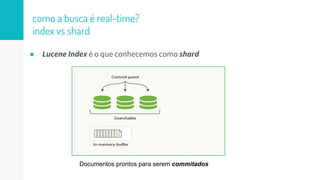
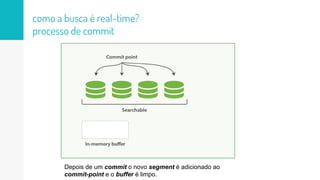
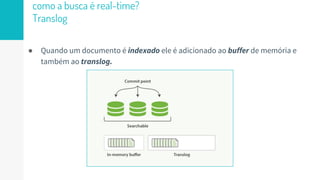
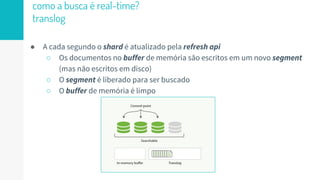
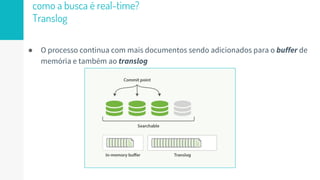
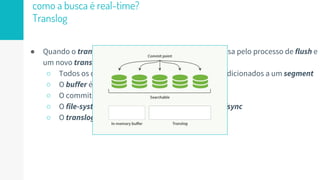
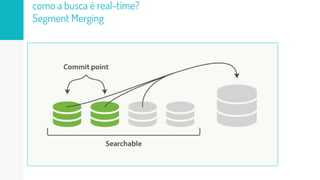
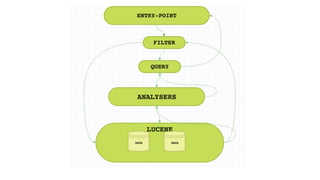
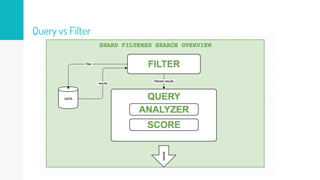
O documento discute como o Elasticsearch funciona internamente de forma concisa em 3 pontos: 1. O Elasticsearch usa o Lucene para indexar e buscar documentos de forma distribuída em shards e réplicas. 2. O índice é atualizado em tempo real à medida que os documentos são adicionados ou atualizados usando um buffer e translog para garantir consistência. 3. Diferentes tipos de consultas como filtros e queries são discutidos em termos de quando usá-los e como funcionam para fornecer resultados relevantes de forma eficiente.


























































