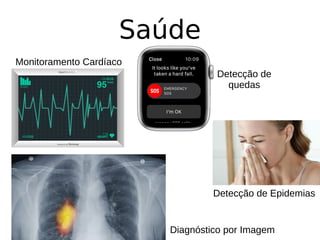
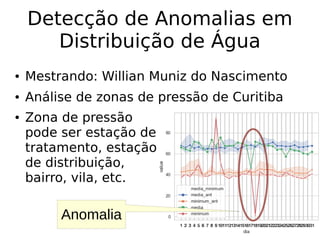
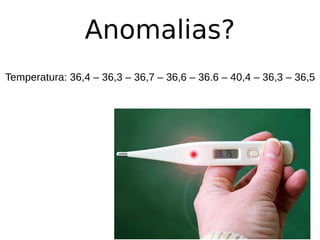
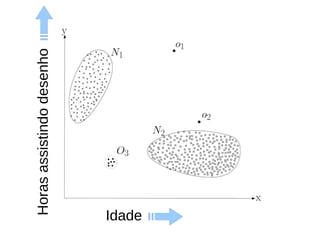
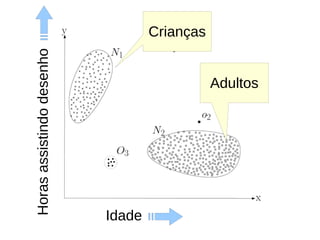
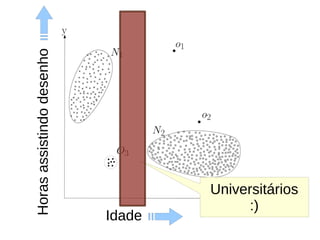
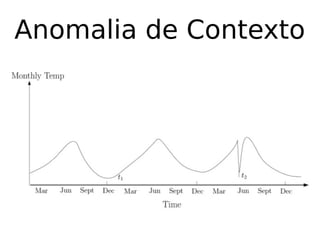
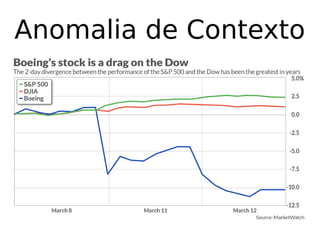
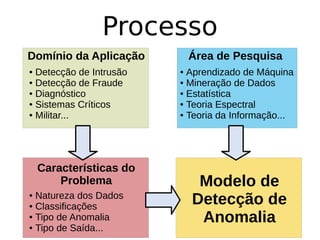
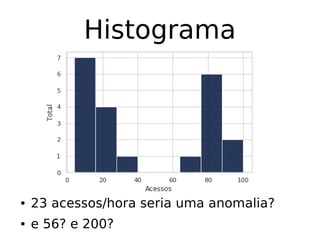
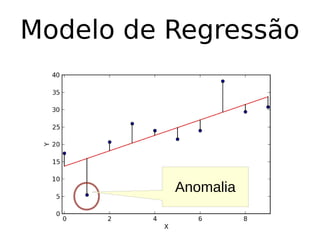
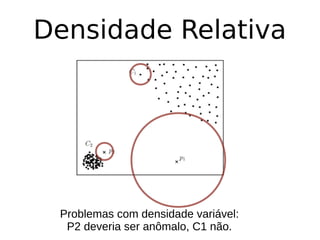
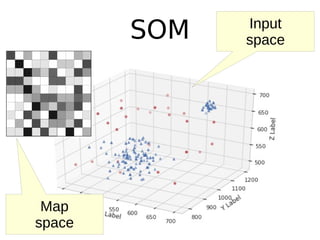
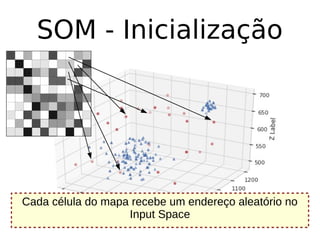
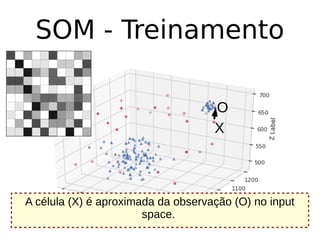
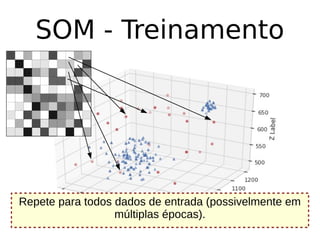
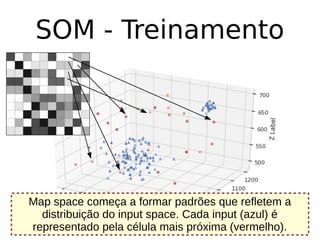
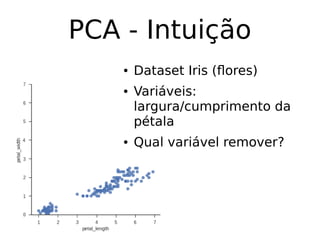
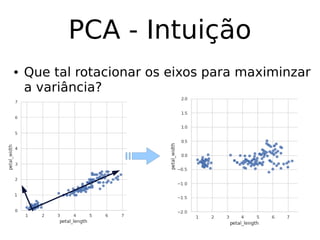
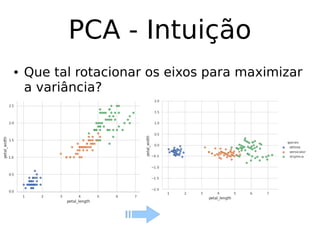
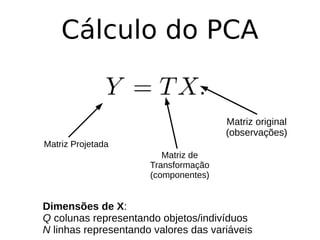
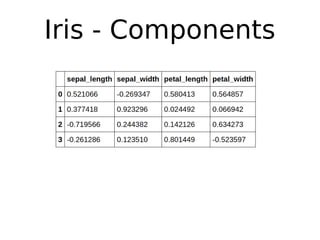
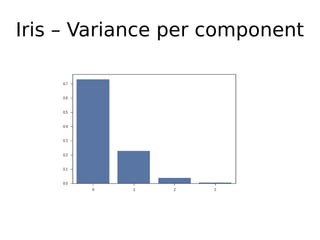
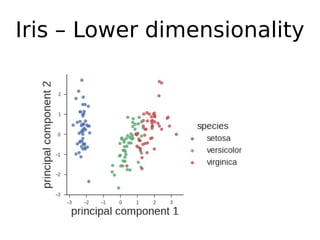
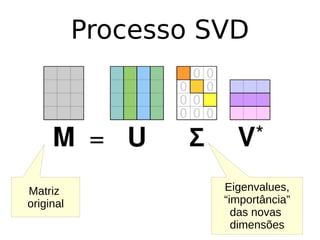
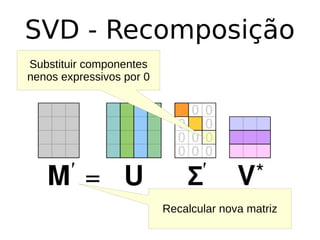
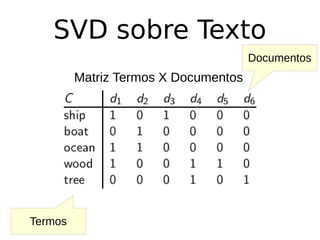
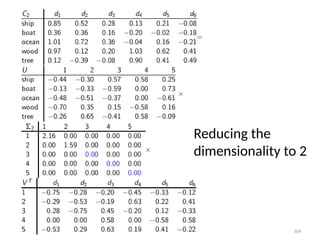
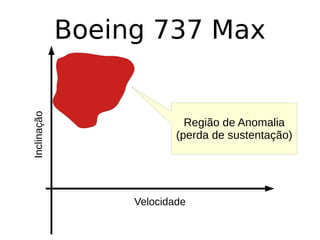
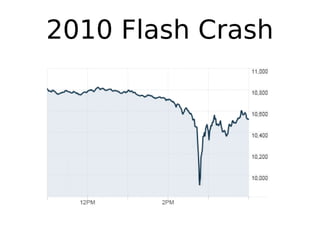
O documento discute técnicas de detecção de anomalias em dados. Aborda definições, aplicações, tipos de anomalias, técnicas estatísticas e de aprendizado de máquina como classificação, vizinhos próximos e agrupamento para identificar padrões que desviam do comportamento esperado. Também discute desafios e pesquisas relacionadas à detecção de anomalias.