Baixado 11 vezes







![Sobre a efemeridade da informação, bem como os problemas
metafísicos que a explosão da rede trouxe a delimitação do
objeto da CI, Costa (2010, p. 16) nos lembra sobre um alerta
“alma, não procure a vida imortal, esgote antes o reino do que
é possível – referenciando a expressão de Pindaro de Beozia
(518 – 438 a. c.) [que] expressa a necessidade de ser e estar na
realidade. Somos habitantes da realidade, nos adaptamos e
transformamos o que está a nossa volta”.
De fato, “vista por outro prisma a aclamada expressão ‘cogito
ergo sum’ de Renè Descartes (1596 – 1650) revela a essência de
nossa marca na realidade” (COSTA, 2010, p. 16). Então, como
deduzir a materialidade do objeto da CI, dada a sua
impossibilidade de ‘enquadramento’ em um único ‘estado’?
Gottschalg-Duque (2005, p. 1) afirma a “parte denominada de
‘Web superficial’ (“surface web”), pois na ‘Web profunda’
(“deep Web”) calcula-se que existam mais de 550 bilhões de
documentos incluindo-se Intranets e Bancos de Dados
corporativos cujo acesso é restrito (BRIGHTPLANET, 2000)”.
Tudo começou com o artigo ‘Certain Factors Affecting
Telegraph Speed’ de Harry Nyquist escrito em 1924, toda a
teoria foi desenvolvida no campo das telecomunicações, nos
laboratórios da Bell, por Shannon &Weaver. Nasceu o maior
problema da CI = a impossibilidade de delimitar a informação.
7](https://image.slidesharecdn.com/ccogebook-170911233406/85/computacao-cognitiva-interface-para-a-ciencia-da-informacao-7-320.jpg)



![Costa (2010, p. 17) “dentre os vários ramos científicos
existentes a Arquitetura da Informação – como disciplina da CI
– surgiu como uma promissora forma de perceber e manipular
a informação em suas variadas manifestações na realidade”.
Gottschalg-Duque (2005, p. 1) traz que “somente o Google,
hoje a mais eficiente máquina de busca em atividade, indexa
mais de três bilhões de páginas Web (GOOGLE, 2005). Essa rica
coleção do saber humano (a Web) está disponibilizada em
mais de 59.100.880 Web sites (WEB SERVER SURVEY,
Fevereiro, 2005) e, teoricamente, acessível a qualquer cidadão
do mundo (INCLUSÃO DIGITAL, 2005)”.
O projeto Eroic (2010, p. 14) contextualiza “a Web, até os
últimos anos do século passado, caracterizava-se por suas
páginas estáticas, comportando textos, imagens e links, que
somente podiam ser alteradas pelo webmaster. No início do
novo século ocorre uma mudança progressiva e irreversível
que torna as páginas dinâmicas e abre aos usuários a
possibilidade de alterar e acrescentar dados. Nasce a Web dos
usuários, e blogs e redes comunitárias se multiplicam e se
expandem”.
“[...] a expressão Web 2.0 surgiu durante uma sessão de
brainstorming entre O‘Reilly e Medialive International. O que é
Medialive International? Produtores de conferências e shows
comerciais sobre tecnologia segundo o site da entidade.
11](https://image.slidesharecdn.com/ccogebook-170911233406/85/computacao-cognitiva-interface-para-a-ciencia-da-informacao-11-320.jpg)
![Assim, pode-se pensar que essa sessão de brainstorming‘ era o
seguinte: O‘Reilly desejava organizar uma conferência sobre a
Web e eles buscavam um nome para ela. […] Havia algo como
um desgaste semântico: sabiam que estavam acontecendo
coisas novas e escolheram 2.0 para se referir a todo o que
poderia vir pela frente. (A tradução é nossa)” (EROIC, 2010).
Gottschalg-Duque (2005, p. 1) “Esta é a realização da primeira
parte da Revolução da Informação, o acesso instantâneo do
indivíduo à informação (LÉVY, 1995; NEGROPONTE, 1995;
DERTOUZOS, 1997; TAKAHASHI, 2000). Porém, tamanha
coleção gera enormes problemas (WITTEN, MOFFAT & BELL,
1999; LYMAN and VARIAN, 2000). Esta informação que está
acessível a todos está sendo gerada e manipulada em vários
idiomas e estilos e representa a expressão de várias culturas,
ideologias, crenças, etc. Como a informação vem sendo
organizada? Como tratá-la e recuperá-la?”.
A folksonomia é geradora da temática da Websemântica pelo
W3C, no intuito de possibilitar descrição semântica por meio
de metadados XML. Imagine como esse viés ajudou na
concepção do LeXML? Não seria possível sem a Websemântica.
Vapnik (1998) afirma que é necessário, portanto:
1. Construir uma teoria de processos de Learning Machine LM
2. Construir uma teoria de ‘bounds’ ou transmissão na rede
3. Construir uma teoria de desambiguação ontológica
12](https://image.slidesharecdn.com/ccogebook-170911233406/85/computacao-cognitiva-interface-para-a-ciencia-da-informacao-12-320.jpg)


![Monard (2003) afirma que “ainda que LM seja uma ferramenta
poderosa para a aquisição automática de conhecimento, deve
ser observado que não existe um único algoritmo que
apresente o melhor desempenho para todos os problemas.
Portanto, é importante compreender o poder e a limitação dos
diversos algoritmos de AM utilizando alguma metodologia que
permita avaliar os conceitos induzidos por esses algoritmos em
determinados problemas”.
Em se tratando de LM, o ‘sujeito’, máquina, insere-se em uma
fenomenologia que, de acordo com Costa (2010, p. 35), “surge
a ideia de que a relação entre sujeito e objeto [informação] é
um fenômeno e deve ser caracterizado. Nas investigações
lógicas de Husserl (1970) a fenomenologia toma forma para
indicar as manifestações que se apresentam ao sujeito”.
O fenômeno ‘inteligência artificial’ vai ser iniciado, de acordo
com Gottschalg-Duque (2005, p. 3), como um “emprego do
processamento de linguagem natural PLN, objetivando
melhorias de um Sistema de Recuperação de Informação”.
Porém, alerta que “normalmente os SRI’s não utilizam PLN,
mas técnicas diretas, como a extração de sentenças ou de
radicais de palavras combinadas com técnicas estatísticas”.
Witten (2005) desenvolve 558 laudas neste sentido, o data-
mining ou ‘extração de dados’ são as práticas [ou Tools] de
técnicas aplicadas à LM.
15](https://image.slidesharecdn.com/ccogebook-170911233406/85/computacao-cognitiva-interface-para-a-ciencia-da-informacao-15-320.jpg)

![coleção que já foram examinados e que são relevantes para
uma busca específica, e Revogação, que é a fração de
documentos da coleção, dentre os que já foram examinados
para uma busca específica, e que são relevantes (FRAKES &
BAEZA-YATES, 1992; GEY, 1992; FERNEDA, 2003)”.
O fato é que Lancaster (2004) tenta afirmar que as linguagens
documentárias automáticas são opostas a essa proposta de
Gottschalg-Duque (2005), e que são sim, sistemas de
recuperação da informação mais eficazes. Porém, as
ontologias nascem, na computação, como filhas das
folksonomias. Em certa medida, Lancaster (2004) tentou
desarticular a atividade de indexação por humanos e dar
prioridade às linguagens documentárias de máquinas.
Witten (2005, p. 243) afirma que “árvores [ontologias] são
usadas para predição numérica, são como decisão comum, a
exceção de que em cada folha elas armazenam um valor de
classe [valor médio das instâncias], em modelo de regressão
linear que prediz o valor de classe de instâncias que atingem a
folha, caso uma árvore se denomine modelo”.
O potencial preditivo da computação permite trabalhar a
universalidade semântica das ontologias, mesmo que estas
sejam articuladas livremente, como de fato são, é muito
incomum, portanto, encontrar ontologias de linguagens
documentárias artificiais, mas sim, em linguagem natural.
17](https://image.slidesharecdn.com/ccogebook-170911233406/85/computacao-cognitiva-interface-para-a-ciencia-da-informacao-17-320.jpg)

![Porém, Witten (2005, p. 254) vai identificar que a LM não é um
mero clustering de dados. “clustering são escolhas de pontos
para representar centros [NÓS] de clusters iniciais. Todos os
pontos de dados são atribuídos para o mais próximo, o valor
médio dos pontos em cada cluster é calculado para formar seu
novo centro de cluster [RENQUE ou CADEIA], e a interação
continua até que não haja mudanças nos clusters”. Nos
fenômenos naturais, portanto, haverão situações atípicas.
Gottschalg-Duque (2005) traz uma análise interessante:
Lesk (1995), em seu artigo intitulado “The Seven Ages of Information
Retrieval”, inspirando-se em Shakespeare, propõe a seguinte
cronologia para a Recuperação de Informação: Infância (1945-1955);
Idade Escolar (anos 60); Maioridade (anos 70); Maturidade (anos 80);
Crise da Meia-Idade (anos 90); Realização (anos 2000) e
Aposentadoria (2010). O artigo retrata a história da Recuperação de
Informação ao longo dessas sete fases, referenciando-se às previsões
de Bush (1945), estabelecendo um paralelo entre as mesmas com as
diferentes etapas que compõem a vida humana. O quadro 2.1
apresenta as três grandes seções, que compõem a Ciência da
Informação, de acordo com a visão de Summers et al. (1999): Ciência
da Informação propriamente dita, Gerenciamento da Informação e
Tecnologia da Informação.
Seguem décadas de argumento de programação neuro-
linguístico e a heurística computacional, pelo viés ponderado
da estatística após Vannevar Bush (1945).
19](https://image.slidesharecdn.com/ccogebook-170911233406/85/computacao-cognitiva-interface-para-a-ciencia-da-informacao-19-320.jpg)

![Costa (2010, p. 36, adaptado) explica que “a fenomenologia
está fundamentada nos seguintes princípios: 1) em primeiro
lugar a consciência é intencional; a consciência transcende em
direção ao objeto e o ‘sujeito’ [MÁQUINA] pretende apreender
o objeto. 2) Este, por sua vez [NÓ ou ONTOLOGIA] se
apresenta ao sujeito em sua essência”; 3) o segundo princípio
é a evidência intuitiva que o objeto deixa no sujeito [SER
HUMANO]. A prova a partir da qual o sujeito assume a
consciência do objeto; e 4) o terceiro elemento é a
generalização da noção do objeto [TAXONOMIA]. Um objeto
pode ser reconhecido em sua essência e por sua categoria. Por
último surge o princípio da percepção imanente [MÁQUINA ou
SER HUMANO]. O sujeito possui suas próprias experiências”.
O projeto Eroic (2010, p. 26) delimita que “ontologias – como
duas bases podem utilizar diferentes identificadores para o
mesmo conceito, é preciso se servir de um programa que
possa combinar ou comparar informações das duas bases de
dados, ― sabendo que os dois termos significam a mesma
coisa. A solução, para que o programa possa ―descobrir o
significado comum, seriam, teoricamente, as coleções de
informações denominadas ―ontologias, termo cooptado da
Filosofia pelos pesquisadores da Web semântica com um
sentido que nada tem a ver com o estudo do ser”.
Ou seja, ontologia não é possível sem a heurística diferencial.
21](https://image.slidesharecdn.com/ccogebook-170911233406/85/computacao-cognitiva-interface-para-a-ciencia-da-informacao-21-320.jpg)


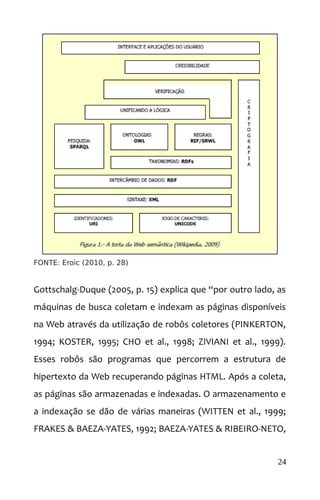
![1999). Normalmente utiliza-se de uma estrutura de arquivo
invertido”. Como tipologias de arquivos invertidos o autor
apresenta: 1) arranjo ordenado ; 2) árvores B ; 3) árvores trie ; e
4) estruturas com Hashing .
Essas tipologias serão estudadas a frente ‘dos tipos de
arquiteturas da informação’. Como modelos de indexação
apresentam-se: “a) o modelo booleano ; b) o modelo booleano
estendido ; c) o modelo probabilístico ; d) o modelo de string
search e e) o modelo vetorial”. (GOTTSCHALG-DUQUE, 2005).
FONTE: Gottschalg-Duque (2010, p. 18)
Monard (2003, p. 40, adaptado) afirma que “indução é a forma
de inferência lógica [MÁQUINA] que permite obter conclusões
genéricas sobre um conjunto particular de exemplos. Ela é
caracterizada como o raciocínio que se origina em um conceito
específico e o generaliza, ou seja, da parte para o todo”.
Ou seja, o principal processo de LM é o indutivo inferencial.
25](https://image.slidesharecdn.com/ccogebook-170911233406/85/computacao-cognitiva-interface-para-a-ciencia-da-informacao-25-320.jpg)

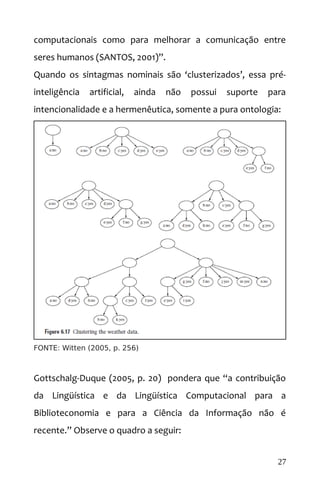
![FONTE: Gottschalg-Duque (2005, p. 20)
São atributos de análise neuro-linguística [HUMANO]:
Morfológica “A análise morfológica (HAGEGÉ, 1997; SANTOS,
2001; PAULO et al. 2002) é aquela em que o
texto é fragmentado para a determinação de
seus componentes, as palavras e os sinais. As
palavras são processadas de acordo com suas
partes (raiz, afixos, prefixos e sufixos), e os
sinais, como a pontuação, são separados da
palavra, podendo ou não ser considerados
relevantes”. (Gottschalg-Duque, 2005, p. 23)
Sintática “A análise sintática (CLARK & CLARK, 1977;
CRAIN & STEEDMAN, 1985; CHOMSKY, 1986;
1995; BICK, 1996; SANTOS, 2001) é aquela em
que cada termo da frase, e consequentemente
do texto, recebe um nome que exprime a sua
função dentro da estrutura oracional, função
28](https://image.slidesharecdn.com/ccogebook-170911233406/85/computacao-cognitiva-interface-para-a-ciencia-da-informacao-28-320.jpg)
![esta que é decorrente do seu relacionamento
com um outro termo. Essa análise sintática
necessita dos resultados da análise morfológica,
para criar uma descrição estrutural da frase”.
(Gottschalg-Duque, 2005, p. 24)
Semântica “A análise semântica (FILLMORE, 1968;
FREDERIKSEN, 1975; 1986; JACKENDOFF, 1990,
1994; GERNSBACHER, 1994) permite a
identificação do significado de cada termo
(palavra) da frase, isolada e conjuntamente com
outros termos. Permite a identificação dos
conceitos primitivos do texto, aqueles que
mantém a essência do texto”. (Gottschalg-
Duque, 2005, p. 29)
Pragmática “A análise pragmática (KINTSCH & van DICK,
1993; DRESNER & DASCAL, 2001) refere-se ao
processamento daquilo que foi dito ou escrito
em contraste com o que realmente se quis dizer
ou escrever. Muitos estudiosos consideram tais
análises como sendo extralingüísticas, que não
pertencem ao domínio da Lingüística e sim da
Psicologia, da Filosofia e da Antropologia”.
(Gottschalg-Duque, 2005, p. 31)
São atributos de análise semiológica de redes neurais
[MÁQUINA]: parametrização particular descendente e
inferência generalizada ou modularização. (VAPNICK, 1998).
29](https://image.slidesharecdn.com/ccogebook-170911233406/85/computacao-cognitiva-interface-para-a-ciencia-da-informacao-29-320.jpg)
![Gottschalg-Duque (2005, p. 31) explica que “ontologia é um
ramo da filosofia que estuda o ser e tudo que se relaciona ao
ser (HEIDEGGER, 1925). Neste estudo ontologia é restrita à
ótica da Inteligência Artificial. É apenas uma especificação
formal de uma conceitualização compartilhada, que é uma
visão abstrata e simplificada do universo que se pretende
representar (GRUBER, 1993)”.
Já sabemos, portanto, que os processos de LM serão baseados
em inferências por modularização em ontologias
[TAXONOMIAS], por meio de cadeias e renques, e que
acontecerá uma parametrização particular descendente nos
diversos níveis de cadeias. Porém, processos de
intencionalidade e hermenêutica, ainda encontram-se
primitivos nas aplicações às máquinas.
Solomonoff (1956, p. 14) afirma que “uma máquina projetada
para aprender a trabalhar problemas de matemática, ao
receber uma série de exemplos categorizados, por associação
e indução, deve ser capaz de envolver um método pelo qual
eles podem ser resolvidos”.
Monard (2003) explica que cada exemplo é descrito por um
vetor de valores de características ou atributos e o rótulo da
classe associada [ONTOLOGIA]. “O objetivo do algoritmo de
indução é construir um classificador que possa determinar
corretamente a classe de novos exemplos” [INFERENCIAIS].
30](https://image.slidesharecdn.com/ccogebook-170911233406/85/computacao-cognitiva-interface-para-a-ciencia-da-informacao-30-320.jpg)
![A noção de momento é definida por Costa (2010, p. 41) aos
sistemas de inteligências artificiais por associação ao grande
problema da Websemântica, que é a continuidade as
associações em cadeias de renques. “O termo é oriundo do
latim momentum. Trata-se de uma expressão que é
empregada na atualidade de quatro modos distintos”.
Quando Gottschalg-Duque (2005, p. 32) define “uma ontologia
(strictu sensu) é composta de classes, relações, regras e
instâncias (CORAZZON, 2003). Uma Ontologia é um “catálogo
de tipos de coisas”, às quais assume-se existir em um domínio
de interesse (SOWA, 1999). Para BORST (1997), uma Ontologia
é uma especificação formal e explicita de uma conceitualização
compartilhada. As diferenças encontradas entre as abordagens
distintas residem principalmente na estrutura, função e
aplicação. Entretanto, as ontologias existentes nas pesquisas
desenvolvidas pela I.A” ; por associação, temos que lembrar de
Koch (1984) quando define os sintagmas intencionais (verbais)
alinhados ao momentum [KRHONUS].
Esse é um dos grandes problemas da linguística e, por
consequencia, da Websemântica. A LM fica comprometida
com as múltiplas ambiguidades semânticas dos diversos
idiomas, quando se trata de ‘momentum’ [intencionalidade].
Costa (2010, p. 41) continua “o momento mecânico linear é
quantidade de movimento e o vetor de posição de partícula”.
31](https://image.slidesharecdn.com/ccogebook-170911233406/85/computacao-cognitiva-interface-para-a-ciencia-da-informacao-31-320.jpg)
![Por sua vez, momento angular é a resultante do produto entre
o vetor de quantidade de movimento e o vetor de posição de
uma partícula [INFORMAÇÃO QUÂNTICA] posta em
movimento. (COSTA, 2010, p. 41).
Ontologias sem a noção de intencionalidade e/ou momentum,
podemos destacar as do tipo ‘ontologias leves’ por Gottschalg-
Duque (2005, p. 33) “atualmente as ontologias são utilizadas
de maneiras variadas e para vários fins (GUARINO, 1997; DING
& FOO, 2001). Para a aplicação na Recuperação Automática de
Informação a utilização de “Ontologias Leves” parece ser uma
opção mais prática, pois, a princípio, elas podem ser
automatizadas de modo mais simples”.
Costa (2010, p. 41) explica que “o sentido dialético do
momento refere-se a uma fase de uma dialética. (…) A
necessidade é composta pelos momentos da condição, da
coisa em si, e da atividade”.
Por Koch (1984) deduzimos Gottschalg-Duque (2005) e Costa
(2010), nos problemas da arquitetura da informação, a
linguista explica “dentre as relações que se estabelecem entre
o texto e o evento que constitui a sua enunciação, podem
destacar as seguintes: a) carregados de pressupostos ; b)
contém intenções explícitas e implícitas ; c) são modalizadores
de atitudes ou ações ; d) possuem operadores
argumentativos ; e e) podem transmitir imagens recíprocas”.
32](https://image.slidesharecdn.com/ccogebook-170911233406/85/computacao-cognitiva-interface-para-a-ciencia-da-informacao-32-320.jpg)

![Portanto, ainda estamos na primeira instância das ontologias,
não chegamos no ©Watson e nas análises preditivas e de
reconhecimento [HERMENEUTICAS].
Gottschalg-Duque (2005, p. 71) pondera que análises preditivas
da marcação semântica de sintagmas verbais [MOMENTUM]
“para a área de Lingüística Computacional é possível
desenvolver pesquisas que otimizem os analisadores sintáticos
e semânticos, através do desenvolvimento de Chunk Parsers,
por exemplo, que são analisadores sintáticos que processam
apenas partes específicas do texto, visando principalmente à
diminuição do ruído inerente ao sistema”.
E, é claro, que essas partes específicas do texto são os
sintagmas de argumentos de Koch (1984), que eram o grande
problema da interpretação dos textos por humanos e o
raciocínio hipotético dedutivo por Costa (2010), quando o
autor começa a iniciar os ‘elementos’ da arquitetura da
informação: teoria, observação, método, modelo, forma,
informação e linguagem, que é aplicado à heurística de
máquinas.
Os analisadores sintáticos recomendados por Gottschalg-
Duque (2005) aplica-se à interface homem-máquina, no
sentido que proporcionam um grau de compreensibilidade no
retorno das análises preditivas das máquinas aos humanos.
Monard (2003) apresenta 5 (cinco) paradigmas de LM.
34](https://image.slidesharecdn.com/ccogebook-170911233406/85/computacao-cognitiva-interface-para-a-ciencia-da-informacao-34-320.jpg)
![3. ARQUITETURA DA INFORMAÇÃO 1
Arquitetura da informação (AI) é um campo consolidado pelo
consenso de que oferece interface para o desenvolvimento de
ambientes digitais. Cammargo (2011) afirma que a AI permite
elaborar uma estrutura que visa à organização das
informações para que os usuários possam acessá-la mais
facilmente e encontrar seus caminhos de conhecimentos.
Costa (2010) apresenta uma série de abordagens de
epistemologia dos humanos, porém é através de Popper que o
raciocínio hipotético dedutivo partilha o conhecimento em
unidades [ONTOLOGIAS] ou metadados, em bases de dados
ou sistemas de recuperação da informação SRI, e que permite
combinações entre os nós da rede ao conhecimento.
Gottschalg-Duque (2005) apresenta uma estruturação de
arquiteturas da informação do tipo 1 quando traz as tipologias
de arquivos invertidos o autor apresenta: 1) arranjo ordenado ;
2) árvores B ; 3) árvores trie ; e 4) estruturas com Hashing .
Essas tipologias serão estudadas a frente ‘dos tipos de
arquiteturas da informação’. Como modelos de indexação
apresentam-se: “a) o modelo booleano ; b) o modelo booleano
estendido ; c) o modelo probabilístico ; d) o modelo de string
search e e) o modelo vetorial”.
Aos bibliotecários, recomendo a leitura complementar de
noções de bancos de dados, registros e do Dublin Core.
35](https://image.slidesharecdn.com/ccogebook-170911233406/85/computacao-cognitiva-interface-para-a-ciencia-da-informacao-35-320.jpg)

![5. ARQUITETURA DA INFORMAÇÃO n+1
Quando Gottschalg-Duque (2005, p. 71) pondera análises
preditivas da marcação semântica de sintagmas verbais
[MOMENTUM] para os analisadores sintáticos ; e Costa (2010)
faz uma ampla revisão da teoria da ciência e da fenomenologia
[que pode se utilizada tanto para entender a metafísica da
informação quanto o entendimento das máquinas], podemos
admitir uma infinidade de arquiteturas da informação.
Vamos assumir a Websemântica como uma marcação
sintagmática da WEB com a finalidade conexionista. Monard
(2003) ensina que as redes neurais [conexionistas] são
construções matemáticas simplificadas inspiradas no modelo
biológico do sistema nervoso. A representação de uma rede
neural envolve unidades altamente interconectadas e, por esse
motivo, o nome conexionismo é utilizado para descrever a
área de estudo. Observe que o Google apresenta LM:
37](https://image.slidesharecdn.com/ccogebook-170911233406/85/computacao-cognitiva-interface-para-a-ciencia-da-informacao-37-320.jpg)




![BIBLIOGRAFIA
CAMARGO, L. S. de A. ; VIDOTTI, S. A. B. G. Arquitetura da
informação: uma abordagem prática para o tratamento de
conteúdo e interface em ambientes informacionais digitais. Rio
de Janeiro: LTC, 2011.
COSTA, Ismael de Moura. [DISSERTAÇÃO DE MESTRADO] Um
método para Arquitetura da Informação: Fenomenologia
como base para o desenvolvimento de arquiteturas da
informação aplicadas. Universidade de Brasília, 2010.
HASTIE, Trevor; FRIEDMAN, Jerome; TIBSHIRANI, Robert. The
elements of statistical learning. 2nd ed. New York: Springer
series in statistics, 2008.
GOTTSCHALG-DUQUE, Cláudio. [TESE DE DOUTORADO]
Sirilico: uma proposta para um sistema de recuperação de
informação baseado em teorias da linguística computacional e
ontologia. 2005. 118 f. Escola de Ciência da Informação,
Universidade Federal de Minas Gerais, Belo Horizonte.
KOCH, Ingedore Grunfeld Villaça. Argumentação e linguagem.
Cortez Editora, 1984.
44](https://image.slidesharecdn.com/ccogebook-170911233406/85/computacao-cognitiva-interface-para-a-ciencia-da-informacao-44-320.jpg)
![MONARD, Maria Carolina; BARANAUSKAS, José Augusto.
Conceitos sobre aprendizado de máquina. Sistemas
Inteligentes-Fundamentos e Aplicações, v. 1, n. 1, 2003.
MORAES, E. F. de ; SOARES, M. B. Websemântica para
máquina de buscas [Search Engine]. UFMG, 2001. pág. 1-6.
ROWLEY, J. Informática para bibliotecas. Tradução por Agenor
Briquet de Lemos. Brasília: Briquet de Lemos, 1994.
---------------. A biblioteca eletrônica. Tradução por Agenor
Briquet de Lemos. Brasília: Briquet de Lemos, 2002.
SOLOMONOFF, Raymond J. An inductive inference machine.
In: IRE Convention Record, Section on Information Theory.
1957. p. 56-62.
TAMMARO, A. M. ; SALARELLI, A. A biblioteca digital.
Tradução por Agenor Briquet de Lemos. Brasília: Briquet de
Lemos, 2008.
WITTEN, Ian H. ; FRANK, E. Data Mining: practical machine
learning tools and techniques. 2nd ed. Morgan Kaufmann,
2005.
45](https://image.slidesharecdn.com/ccogebook-170911233406/85/computacao-cognitiva-interface-para-a-ciencia-da-informacao-45-320.jpg)

A apresentação discute a interface entre computação cognitiva e ciência da informação, como a lei da informação de Shannon & Weaver influenciou o desenvolvimento da computação cognitiva. Também aborda como a explosão da web criou desafios para a organização da informação e como projetos como o LexML tentaram responder a esses desafios por meio de ontologias.




































