Baixado 21 vezes

















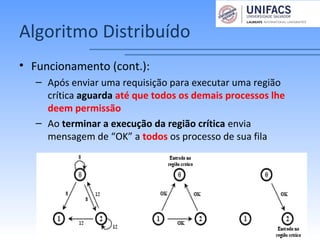





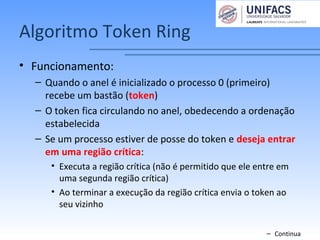
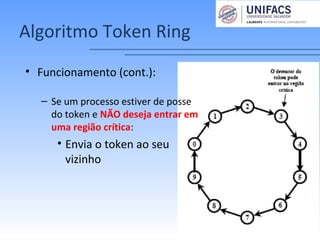





O documento discute soluções para o problema de exclusão mútua em sistemas distribuídos. Apresenta três algoritmos: centralizado, distribuído e em anel. O algoritmo centralizado usa um processo coordenador para controlar o acesso à região crítica. O algoritmo distribuído ordena eventos globalmente através de troca de mensagens. O algoritmo em anel passa um token circularmente entre os processos.



































































