Baixado 190 vezes
![Relatório de Utilização da Ferramenta Weka
Francisco Glaubos Nunes Clímaco
2 de junho de 2014
1 Introdução
Este é um relatório de trabalho proposto no qual o objetivo era escolher uma
base de dados, aplicar as tarefas de mineração de dados: classificação, associação
e clusterização e analisar os resultados obtidos por cada método de cada tarefa.
1.1 A base de dados
A base utilizada neste trabalho foi a Breast Cancer, que foi obtida a partir do
Centro Médico da Universidade, Instituto de Oncologia, Ljubljana, Iugoslávia
[2]. Esta base possui informações acerca de pacientes com câncer de mama e
inclui no total 286 instâncias: 201 de uma classe, 85 de outra classe e 277 sem
valores ausentes, estas são descritas por nove atributos (Tabela 1) , alguns são
lineares e outros são nominais:
1. Class: Não-Recorrência ou Recorrência de sintomas do câncer de mama
nos pacientes após o tratamento.
2. age: Idade do paciente no momento do diagnóstico.
3. menopause: Estado de menopausa do paciente no momento do diagnós-
tico.
4. tumor-size: O tamanho do tumor em milímetros.
5. inv-nodes: Faixa de 0 a 39 linfonodos auxiliares, que mostram o câncer de
mama no momento do exame histológico.
6. nodes-cap: A penetração do tumor na cápsula do linfonodo ou não.
7. deg-malign: Faixa de grau 1 a 3, que define o grau histológico do tumor,
o nível de malignidade do tumor.
8. breast:O câncer poder ocorrer em qualquer mama.
9. breast-quad: Se for considerado o mamilo como um ponto central, a mama
pode ser dividida em quatro quadrantes.
10. irradiat: Se o paciente possui ou não histórico de terapia de radiação (raio-
x).
1](https://image.slidesharecdn.com/glaubos-relatorio-weka1-140616090915-phpapp01/85/Relatorio-Utilizacao-da-Ferramenta-Weka-1-320.jpg)
![Relatório de Utilização da Ferramenta Weka
Francisco Glaubos Nunes Clímaco
2 de junho de 2014
1 Introdução
Este é um relatório de trabalho proposto no qual o objetivo era escolher uma
base de dados, aplicar as tarefas de mineração de dados: classificação, associação
e clusterização e analisar os resultados obtidos por cada método de cada tarefa.
1.1 A base de dados
A base utilizada neste trabalho foi a Breast Cancer, que foi obtida a partir do
Centro Médico da Universidade, Instituto de Oncologia, Ljubljana, Iugoslávia
[2]. Esta base possui informações acerca de pacientes com câncer de mama e
inclui no total 286 instâncias: 201 de uma classe, 85 de outra classe e 277 sem
valores ausentes, estas são descritas por nove atributos (Tabela 1) , alguns são
lineares e outros são nominais:
1. Class: Não-Recorrência ou Recorrência de sintomas do câncer de mama
nos pacientes após o tratamento.
2. age: Idade do paciente no momento do diagnóstico.
3. menopause: Estado de menopausa do paciente no momento do diagnós-
tico.
4. tumor-size: O tamanho do tumor em milímetros.
5. inv-nodes: Faixa de 0 a 39 linfonodos auxiliares, que mostram o câncer de
mama no momento do exame histológico.
6. nodes-cap: A penetração do tumor na cápsula do linfonodo ou não.
7. deg-malign: Faixa de grau 1 a 3, que define o grau histológico do tumor,
o nível de malignidade do tumor.
8. breast:O câncer poder ocorrer em qualquer mama.
9. breast-quad: Se for considerado o mamilo como um ponto central, a mama
pode ser dividida em quatro quadrantes.
10. irradiat: Se o paciente possui ou não histórico de terapia de radiação (raio-
x).
1](https://image.slidesharecdn.com/glaubos-relatorio-weka1-140616090915-phpapp01/75/Relatorio-Utilizacao-da-Ferramenta-Weka-1-2048.jpg)
![K-means e DSCAN, variando os parâmetros de entrada e posteriormente reali-
zando uma análise dos resultados com base nos centróides dos clusters.
2 Tarefas de Mineração de Dados
2.1 Classificação
Classificação é o processo que visa encontrar modelos ou funções que descrevam
ou distinguam classes ou conceitos de dados, com o intuito de permitir que o
modelo ou função preveja a classe daqueles objetos que não possuem um label
que indique sua classe [1]. Para os experimentos utilizou-se por default o Cross-
Validation com k=10.
2.1.1 Nayve Bayes
É um classificador probabilístico baseado no Teorema de Bayes.Sua ideia prin-
cipal é calcular a probabilidade de certa instância de entrada pertencer a cada
uma das classes.
Este método foi executado pela ferramenta Weka e os resultados estão na
Figura 2. O resumo dos resultados dessa execução pode ser apresentado da
seguinte forma: o algoritmo Nayve Bayes classificou corretamente 205 e incor-
retamente 81 instâncias, e a partir da matriz de confusão ainda pode-se con-
cluir que 33 instâncias foram classificadas como reccurence-events, quando de
fato pertencem a classe no-reccurence-events, e que 48 foram da mesma forma
incorretamente classificadas como no-reccurence-events quando na verdade per-
tencem a classe reccurence-events.
Figura 2: Resultados da execução do método Nayve Bayes.
3](https://image.slidesharecdn.com/glaubos-relatorio-weka1-140616090915-phpapp01/85/Relatorio-Utilizacao-da-Ferramenta-Weka-3-320.jpg)





![Figura 9: Desempenho local dos classificadores em relação a classe no-
recurrence-events
2.2 Associação
Pode ser definida como a tarefa de extrair regras de associação que representam
padrões entre itens de uma aplicação, com certa frequência [1].
2.2.1 Apriori
É uma estratégia que parte da seguinte ideia: se um padrão de tamanho k não
é frequente, então seu super-padrão de tamanho k+1 também não será.
Primeiramente buscou-se utilizar o Modelo Suporte/Confiança, com suporte
mínimo igual a 0.5 e confiança igual a 0.9. As três melhores regras geradas por
esse método foram:
• R1: inv−nodes = 0−2, irradiat = no, Class = no−recurrence−events
⇒ node − caps = no confiança:(0.99)
• R2: inv − nodes = 0 − 2, irradiat = no ⇒ node − caps = no confi-
ança:(0.97)
• R3: node−caps = no, irradiat = no, Class = no−recurrence−events ⇒
inv − nodes = 0 − 2 confiança:(0.96)
O Modelo Suporte/Confiança gera um número grande de regras de associa-
ção, e que muitas vezes são redundantes, óbvias e até contraditórias, não sendo
interessante ao usuário. Para resolver esse problema, outras medidas de inte-
resse são utilizadas para se definir quais regras são de fato relevantes ao usuário
[3].
Por meio da medida Lift é possível verificar o quanto mais frequente é o con-
sequente quando seu antecedente ocorre, se para uma regra tem-se Lift=1, então
o antecedente e o consequente desta regra são independentes, e para minMetric
9](https://image.slidesharecdn.com/glaubos-relatorio-weka1-140616090915-phpapp01/85/Relatorio-Utilizacao-da-Ferramenta-Weka-9-320.jpg)
![Lift > 1, quanto maior o Lift, mais relevante será a regra. Para o experimento,
foi definido minMetric do Lift=1.1 e a seguir as três melhores regras extraídas:
• R4: inv − nodes = 0 − 2 ⇒ node − caps = no, irradiat = no conf:(0.83)
lift:(1.26)
• R5: node − caps = no, irradiat = no ⇒ inv − nodes = 0 − 2 conf:(0.94)
lift:(1.26)
• R6: node − caps = no ⇒ inv − nodes = 0 − 2, irradiat = no conf:(0.8)
lift:(1.25)
Da regra R4, concluiu-se que os itens inv−nodes = 0−2 e node−caps = no,
irradiat = no possuem dependência positiva (o suporte real da regra é 1.26 vezes
maior que o suporte esperado). O mesmo raciocínio serve para as regras R5 e
R6.
Uma outra medida explorada foi a Rule Interest (RI) ou leverage, que indica
a diferença entre o suporte real e o suporte esperado de uma regra de asso-
ciação. Esta medida varia entre -0.25 e 0.25, quanto maior este valor, mais
interessante será a regra. Assim como a medida Lift, o RI verifica a dependên-
cia do consequente em relação ao seu antecedente, portanto, uma outra medida
(Conviction) será utilizada para verificar se de fato a regra obtida utilizando
essas duas medidas é relevante. Os resultados da utilização do RI e verificação
com minMetric do Conviction igual a 0.9 são detalhados abaixo:
• R7: inv − nodes = 0 − 2 ⇒ node − caps = no, irradiat = no conf:(0.83)
lift:(1.26) < lev:(0.13)> conv:(1.97)
• R8: node − caps = no, irradiat = no ⇒ inv − nodes = 0 − 2 conf:(0.94)
lift:(1.26) < lev:(0.13)> conv:(4)
• R9: inv − nodes = 0 − 2 ⇒ node − caps = no conf:(0.94) lift:(1.22)
<lev:(0.12)> conv:(3.67)
A partir dessas novas três melhores regras geradas observou-se que após a
utilização do RI e a verificação de convicção, R7=R4, R8=R5 e a regra R9
tomou a posição que era de R6, ou seja, R4 e R5 encontradas na extração
anterior de fato eram regras relevantes, enquanto que R6 nem tanto, por esse
motivo R6 sai do conjunto das melhores três regras e dá lugar a R9 que possui
uma convicção melhor.
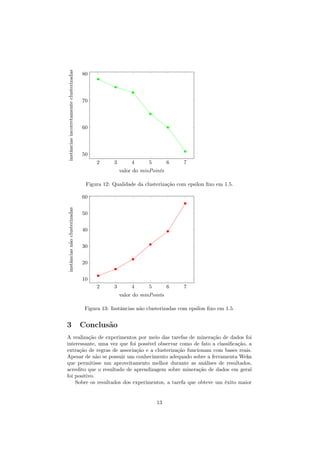
2.3 Clusterização
É o processo de agrupamento de um conjunto de objetos dentro de classes de
objetos similares [1]. Para a execução deste experimento, o atributo classe foi
desconsiderado, porém utilizado posteriormente para verificar a qualidade da
clusterização obtida.
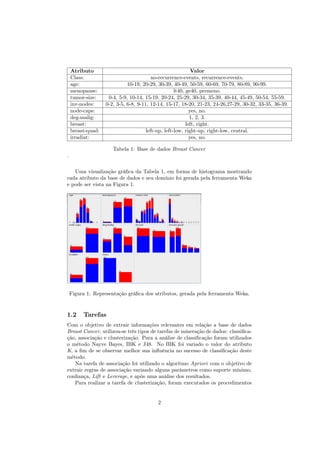
2.3.1 SimpleKmeans
É um algoritmo baseado na ideia do K-means, onde se tem como entrada o
parâmetro k, que diz respeito ao número de clusters que o método irá gerar. Para
a primeira execução deste algoritmo foi-se utilizado k=2 e Distância Euclidiana
como parâmetros, os resultados pode ser vistos na Figura 10.
10](https://image.slidesharecdn.com/glaubos-relatorio-weka1-140616090915-phpapp01/85/Relatorio-Utilizacao-da-Ferramenta-Weka-10-320.jpg)


![em relação a base breast cancer foi a tarefa de classificação, além de classificar
bem as instâncias, observou-se uma flexibilidade interessante em relação à clas-
sificação global e local de tal maneira que o usuário pode obter resultados bons
referentes a apenas uma classe ou as duas, ou seja, em função da perspectiva do
usuário sobre a base de dados.
Após todos os experimentos, concluiu-se principalmente que os parâmetros
de entrada utilizados nas estratégias é um fator determinante para o sucesso
destas. Durante os experimentos, foi observado que se faz necessário um traba-
lho exaustivo na calibragem dos parâmetros até que se obtenha um resultado de
qualidade, nesse sentido, uma ideia para automatizar esse processo seria a im-
plementação de uma meta-heurísitca que recebesse como entrada, um problema:
a base de dados, o algoritmo e seu parâmetros, e retornasse uma solução: um
conjunto de parâmetros que melhor atendesse às necessidades do algoritmo em
função da base.
4 Referências Bibliográficas
-
[1] Jiawei Han. 2005. Data Mining: Concepts and Techniques. Morgan Kauf-
mann Publishers Inc., San Francisco, CA, USA.
[2] Website: http://archive.ics.uci.edu/ml/datasets/Breast+Cancer. Acessado
em 30/04/2014.
[3] GONÇALVES, E. C. - “Regras de Associação e suas Medidas de Interesse
Objetivas e Subjetivas”
14](https://image.slidesharecdn.com/glaubos-relatorio-weka1-140616090915-phpapp01/85/Relatorio-Utilizacao-da-Ferramenta-Weka-14-320.jpg)

1. O relatório descreve os resultados de tarefas de mineração de dados aplicadas à base de dados Breast Cancer usando a ferramenta Weka, incluindo classificação, associação e clusterização. 2. Os métodos J48, Naive Bayes e IBK foram usados para classificação, com J48 tendo o melhor desempenho. 3. Apriori foi usado para associação, gerando regras com medidas como suporte, confiança, lift e leverage.
























































![[José Ahirton Lopes] Treinamento - Árvores de Decisão, SVM e Naive Bayes](https://cdn.slidesharecdn.com/ss_thumbnails/treinamentodeveloperssp-180611021639-thumbnail.jpg?width=640&height=640&fit=bounds)










