Transferir como PDF, PPTX






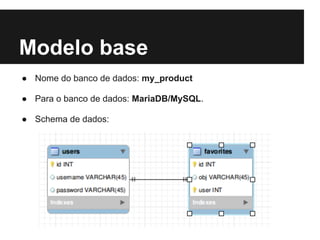














![Cassandra - Inserir
● set users[1][username] = Fernando;
● set users[1][password] = 123;
● set favorites[1][obj] = Meritt;
● set favorites[1][user] = 1;](https://image.slidesharecdn.com/nosql-eofuturodosbancosdedadosnaweb-130728175908-phpapp01/85/2-Meritt-CC-NoSQL-E-o-Futuro-dos-Bancos-de-Dados-na-Web-24-320.jpg)
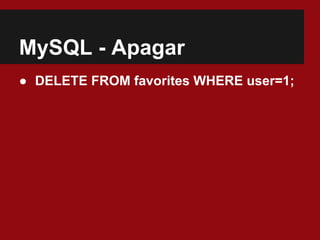
![Cassandra - Editar
● set favorites[1][obj] = 'Meritt e Python';](https://image.slidesharecdn.com/nosql-eofuturodosbancosdedadosnaweb-130728175908-phpapp01/85/2-Meritt-CC-NoSQL-E-o-Futuro-dos-Bancos-de-Dados-na-Web-25-320.jpg)
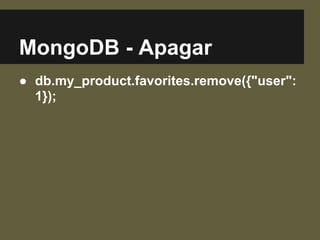
![Cassandra - Apagar
● del favorites[1];](https://image.slidesharecdn.com/nosql-eofuturodosbancosdedadosnaweb-130728175908-phpapp01/85/2-Meritt-CC-NoSQL-E-o-Futuro-dos-Bancos-de-Dados-na-Web-26-320.jpg)
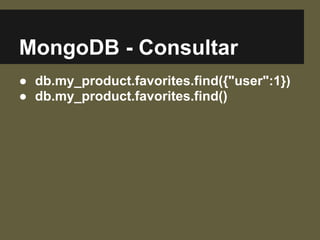
![Cassandra - Consultar
● get favorites[1];
● list favorites;](https://image.slidesharecdn.com/nosql-eofuturodosbancosdedadosnaweb-130728175908-phpapp01/85/2-Meritt-CC-NoSQL-E-o-Futuro-dos-Bancos-de-Dados-na-Web-27-320.jpg)










O documento discute bancos de dados NoSQL, comparando MongoDB, Cassandra e HBase. MongoDB é adequado para alta velocidade e suporte a clusters, enquanto Cassandra é bom para alta velocidade de escrita. HBase pode armazenar grandes quantidades de dados, mas requer configuração difícil. No geral, NoSQL é útil para escalabilidade e desempenho em aplicações de grande volume.















































