Transferir como PDF, PPTX




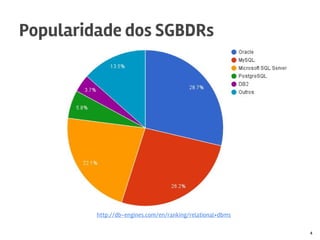
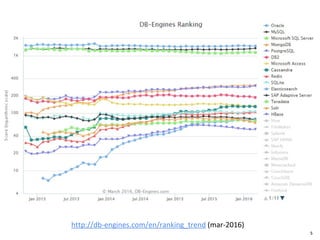
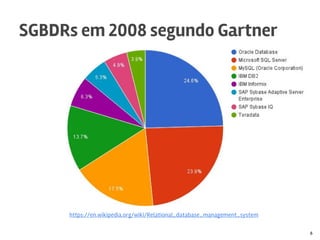


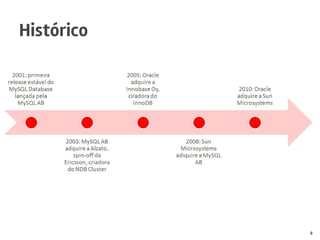
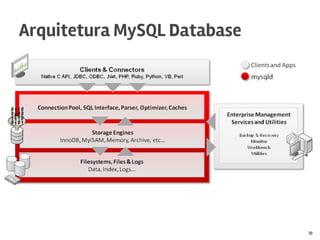
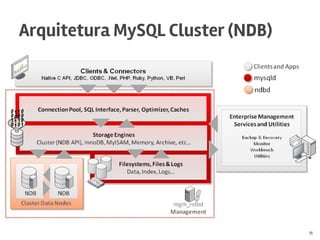




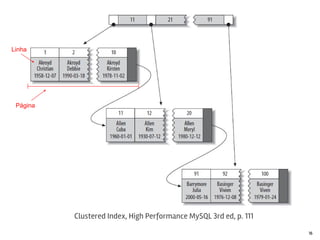








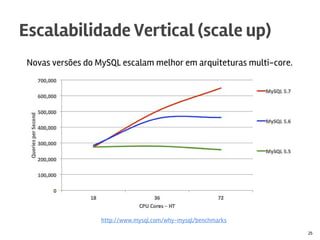






O documento discute o MySQL, incluindo sua popularidade no mercado, características gerais, estruturas de armazenamento como InnoDB, técnicas para grandes volumes de dados como partições, e conclusões sobre seus pontos fortes como desempenho e abertura e fracos como falta de funcionalidades avançadas.





















































