Baixado 99 vezes











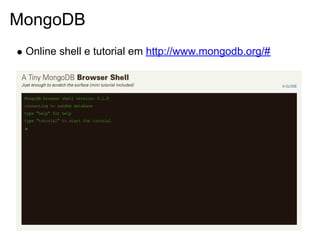
![MongoDB
Instalacao: binarios ou via compilacao de fontes
Servidor: ./mongod
Cliente(teste): ./mongo
Salvando dados: db.foo.save( { a : 1 } )
Lendo dados: db.foo.find()
Consultas: db.foo.find( { $or : [ { a : 1 } , { b : 2 } ] } )](https://image.slidesharecdn.com/nosqllivre-100722190811-phpapp01/85/NoSQL-Livre-12-320.jpg)













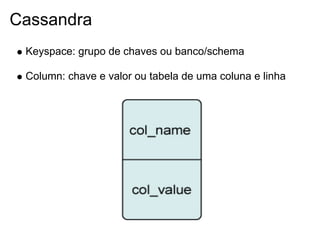
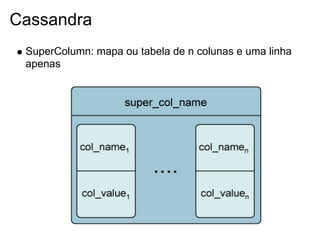
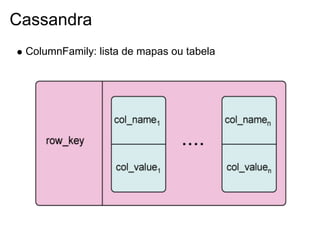
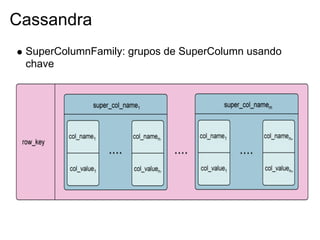








Julio Viegas é um engenheiro de software e instrutor com 15 anos de experiência na área de tecnologia. Ele apresenta sobre várias tecnologias NoSQL como Redis, MongoDB, CouchDB, Memcached e Cassandra, discutindo suas características, arquitetura, instalação e uso.





















































