
















![Apresentação Introdução Classificação Regressão Dúvidas
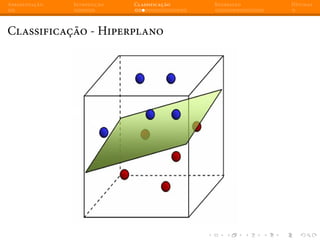
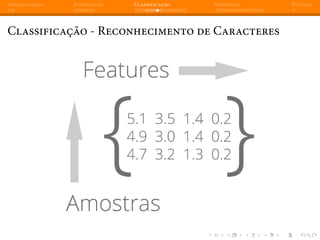
Classificação - Reconhecimento de Caracteres
>> digitos.data[0]
array([ 0., 0., 5., 13., 9., 1., 0., 0., 0.,
15., 10., 15., 5., 0., 0., 3., 15., 2.,
8., 0., 0., 4., 12., 0., 0., 8., 8.,
5., 8., 0., 0., 9., 8., 0., 0., 4.,
1., 12., 7., 0., 0., 2., 14., 5., 10.,
0., 0., 0., 6., 13., 10., 0., 0., 0.])
>>> digitos.target[0]
0](https://image.slidesharecdn.com/intromlslides20min-140607182854-phpapp02/85/Machine-Learning-com-Python-e-Scikit-learn-33-320.jpg)


![Apresentação Introdução Classificação Regressão Dúvidas
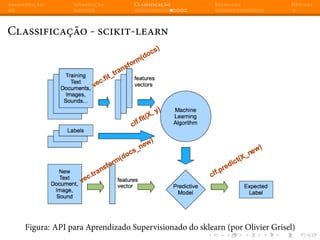
Classificação - scikit-learn + SVM
from sklearn import svm, datasets
digitos = datasets.load_digits()
modelo = svm.SVC(gamma=0.001)
num_amostras = len(digitos.data)
modelo.fit(digitos.data[:num_amostras / 2],
digitos.target[:num_amostras / 2])](https://image.slidesharecdn.com/intromlslides20min-140607182854-phpapp02/85/Machine-Learning-com-Python-e-Scikit-learn-38-320.jpg)
![Apresentação Introdução Classificação Regressão Dúvidas
Classificação - scikit-learn + SVM
from sklearn import svm, datasets
digitos = datasets.load_digits()
modelo = svm.SVC(gamma=0.001)
num_amostras = len(digitos.data)
modelo.fit(digitos.data[:num_amostras / 2],
digitos.target[:num_amostras / 2])
classe_esperada = digitos.target[num_amostras / 2:]
classe_descoberta =
modelo.predict(digitos.data[num_amostras / 2:])](https://image.slidesharecdn.com/intromlslides20min-140607182854-phpapp02/85/Machine-Learning-com-Python-e-Scikit-learn-39-320.jpg)
![Apresentação Introdução Classificação Regressão Dúvidas
Classificação - scikit-learn + SVM
>>> classe_esperada[25:35]
array([8, 9, 0, 1, 2, 3, 4, 9, 6, 7])
>>> classe_descoberta[25:35]
array([8, 9, 0, 1, 2, 3, 4, 5, 6, 7])](https://image.slidesharecdn.com/intromlslides20min-140607182854-phpapp02/85/Machine-Learning-com-Python-e-Scikit-learn-40-320.jpg)
![Apresentação Introdução Classificação Regressão Dúvidas
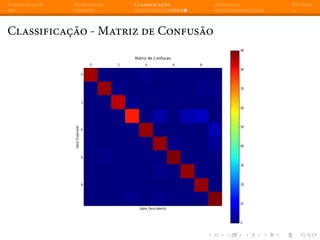
Classificação - Matriz de Confusão
Uma das maneiras avaliar o quão bem um modelo se comporta, é
utilizando uma Matriz de Confusão:
>>> from sklearn import metrics
>>> metrics.confusion_matrix(classe_esperada,
... classe_descoberta)
[[87 0 0 0 1 0 0 0 0 0]
[ 0 88 1 0 0 0 0 0 1 1]
[ 0 0 85 1 0 0 0 0 0 0]
[ 0 0 0 79 0 3 0 4 5 0]
[ 0 0 0 0 88 0 0 0 0 4]
[ 0 0 0 0 0 88 1 0 0 2]
[ 0 1 0 0 0 0 90 0 0 0]
[ 0 0 0 0 0 1 0 88 0 0]
[ 0 0 0 0 0 0 0 0 88 0]
[ 0 0 0 1 0 1 0 0 0 90]]](https://image.slidesharecdn.com/intromlslides20min-140607182854-phpapp02/85/Machine-Learning-com-Python-e-Scikit-learn-41-320.jpg)










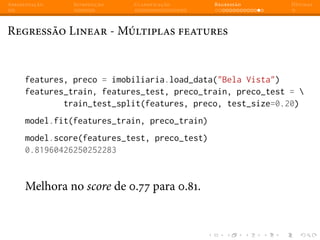

![Apresentação Introdução Classificação Regressão Dúvidas
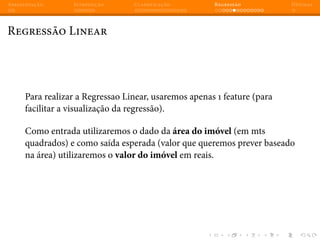
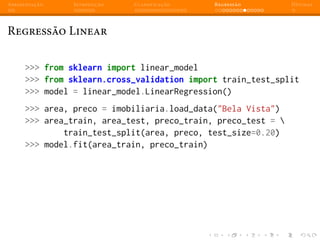
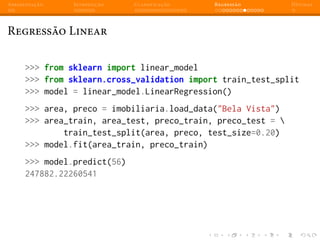
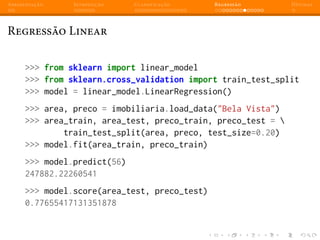
Regressão Linear - Múltiplas features
Utilizando o modelo de regressão que treinamos, podemos fazer
perguntas como por exemplo, qual seria a estimativa de preço para um
imóvel de 56 m2
com apenas 1 dormitório localizado no bairro Bela
Vista ?
linear_model.predict([56, 1])
array([ 216157.98252844])
Ou seja: um imóvel de 1 dormitório com 56 m2
no bairro Bela Vista
em Porto Alegre custaria aproximadamente R$216.157,00.](https://image.slidesharecdn.com/intromlslides20min-140607182854-phpapp02/85/Machine-Learning-com-Python-e-Scikit-learn-67-320.jpg)



Este documento apresenta um tutorial sobre machine learning com Python e scikit-learn. Ele discute introdução ao machine learning, classificação, regressão e o framework scikit-learn. Apresenta exemplos de classificação usando reconhecimento de dígitos escritos à mão e regressão linear para prever preços de imóveis.











































![[DTC21] Raphael Castilho - Começando com Inteligência Artificial e Machine Le...](https://cdn.slidesharecdn.com/ss_thumbnails/iaemachine-210317154040-thumbnail.jpg?width=640&height=640&fit=bounds)