Transferir como PDF, PPTX













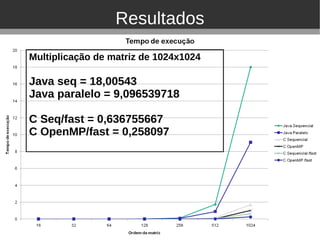
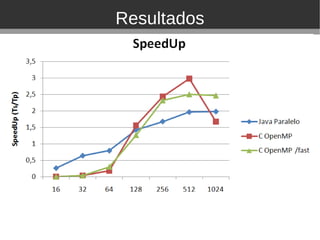
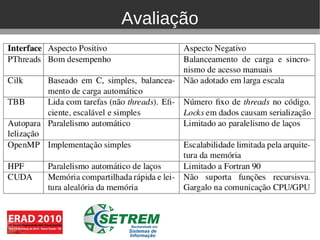



O documento discute ferramentas de programação paralela para arquiteturas multicore, incluindo Pthreads, Cilk, TBB, OpenMP, HPF e CUDA. Ele apresenta exemplos de aplicações paralelas em áreas como medicina, meteorologia e astronomia. Resultados experimentais mostram que OpenMP e C paralelo podem acelerar multiplicação de matrizes em relação a sequencial.



![[XP Forward 66]](https://cdn.slidesharecdn.com/ss_thumbnails/myxp1-200217134711-thumbnail.jpg?width=640&height=640&fit=bounds)












![[Pereira ic'2011] explorando o paralelismo no nível de threads](https://cdn.slidesharecdn.com/ss_thumbnails/pereiraic2011explorandooparalelismononveldethreads-111008083559-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)










![[Ottoni micro05] resume](https://cdn.slidesharecdn.com/ss_thumbnails/ottonimicro05resume-111220195110-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)










