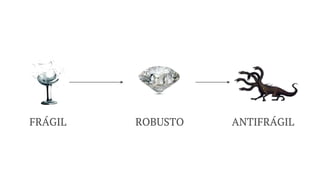
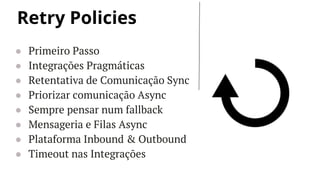
O documento trata da Engenharia de Confiabilidade (SRE), explorando conceitos como métricas de desempenho (SLA, SLO, SLI) e a importância de abraçar incertezas e riscos em sistemas de software. Discute estratégias para garantir resiliência, como simuladores de desastres e políticas de fallback, e enfatiza a necessidade de um aprendizado contínuo e uma abordagem prática na implementação de melhorias. Por fim, aborda ferramentas e práticas recomendadas que podem ser adotadas para fortalecer a confiabilidade e a resiliência organizacional.