Transferir como PDF, PPTX





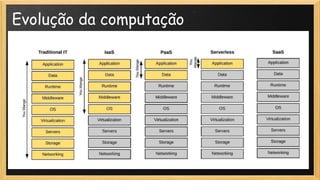



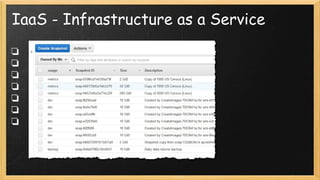


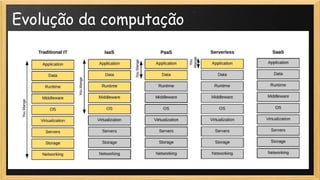
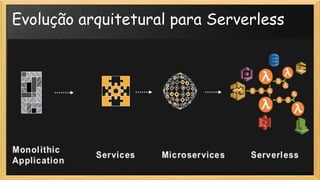





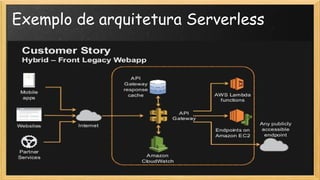











O documento discute a evolução da computação, destacando a transição de TI tradicional para modelos modernos como serverless e site reliability engineering (SRE). Apresenta conceitos de arquitetura serverless, incluindo IaaS, PaaS e FaaS, e os benefícios de uma operação mais ágil e gerenciada na nuvem. Também aborda o papel do SRE na manutenção da disponibilidade e performance dos serviços, enfatizando a importância de métricas e gestão de mudanças.











![[DevOps Summit Brasil] Procura-se: DevOps!](https://cdn.slidesharecdn.com/ss_thumbnails/devopssummitbrasilprocura-sedevopsv1-160516050715-thumbnail.jpg?width=640&height=640&fit=bounds)



































