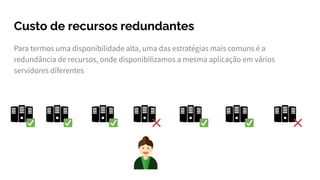
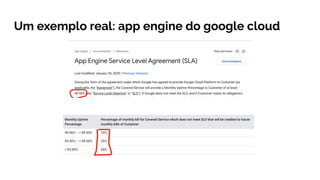
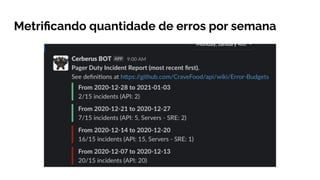
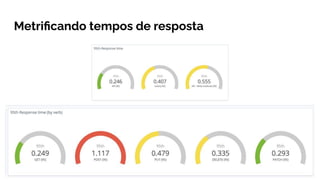
O documento explora a evolução do Site Reliability Engineering (SRE) como uma abordagem moderna que equilibra desenvolvimento e operações, ressaltando a importância da confiabilidade dos sistemas. Discute conceitos de DevOps, práticas de integração e entrega contínuas, além de métricas como SLIs, SLOs e SLAs para avaliar a disponibilidade desejável e gerenciar riscos. Por fim, destaca o papel dos profissionais de SRE em promover a estabilidade e a automação, enfatizando que a confiabilidade é uma responsabilidade compartilhada entre todas as equipes.