Baixado 13 vezes





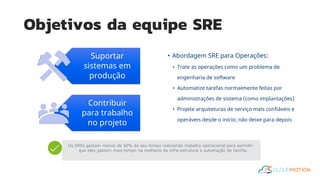

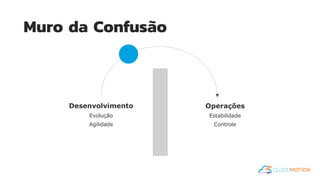

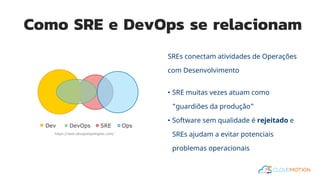


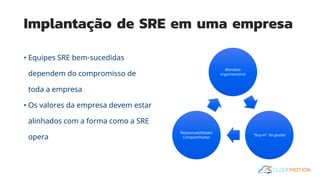
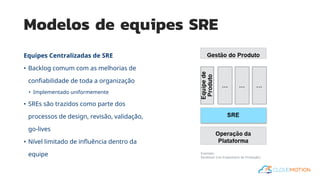
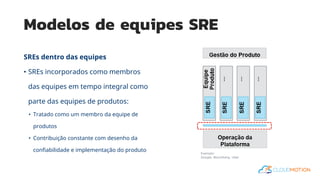
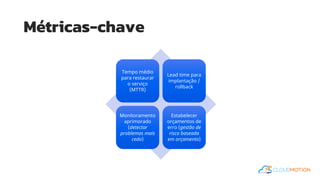


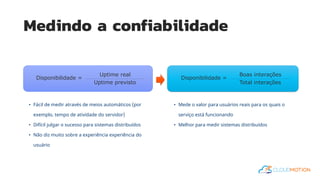


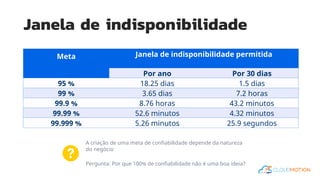

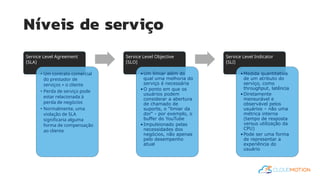
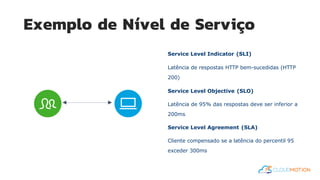








O documento introduz o conceito de Site Reliability Engineering (SRE) e fornece diretrizes para equipes implementarem práticas SRE para melhorar a confiabilidade dos sistemas em produção, como definir orçamentos de erro e níveis de serviço.






















![[IBM 서버] 노후서버는 왜 교체해야 하는가](https://cdn.slidesharecdn.com/ss_thumbnails/1-181101052914-thumbnail.jpg?width=640&height=640&fit=bounds)












































