Baixar para ler offline












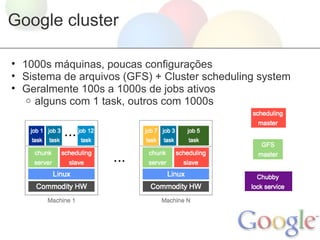






O documento discute como a engenharia de site reliability (SRE) do Google garante a confiabilidade dos serviços da empresa. A SRE envolve engenheiros de software trabalhando junto com administradores de sistemas para garantir redundância, dimensionamento adequado, monitoramento e processos de lançamento de software que permitam os serviços sobreviverem a falhas. A confiabilidade é fundamental no design, desenvolvimento e implantação de serviços do Google.

























































































