Baixar para ler offline














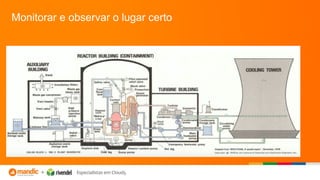






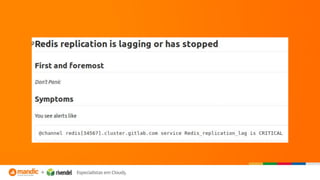









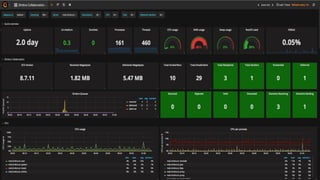
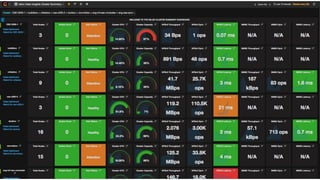






O documento discute a importância do monitoramento e da observabilidade para identificar problemas nos sistemas antes que aconteçam e entender as causas quando acontecem. Também fornece dicas sobre como realizar troubleshooting de forma estruturada utilizando checklists e evitando armadilhas comuns.




















![[White paper] detectando problemas em redes industriais através de monitorame...](https://cdn.slidesharecdn.com/ss_thumbnails/whitepaperdetectandoproblemasemredesindustriaisatravsdemonitoramentocontnuovfinal-130613083901-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)






