Este documento apresenta um resumo sobre clustering. Apresenta os principais tipos de clustering como hierárquico e k-means. Descreve algoritmos específicos como CURE e GRGPF. Também discute clustering em streams de dados e em ambientes paralelos.
Overview
1 Introdução
Clustering
2 Clusteringhierárquico
3 Algoritmos K-means
Algoritmo de Bradley, Fayyad e Reina
Algoritmo CURE
Algoritmo GRGPF
4 Stream e Paralelismo
Stream
Algoritmo DBMO
Paralelismo
André Luís Pitombeira (UFC) Clustering 10 de maio de 2013 2 / 45
3.
Introdução
Figura: Era dainformação
André Luís Pitombeira (UFC) Clustering 10 de maio de 2013 3 / 45
4.
Introdução
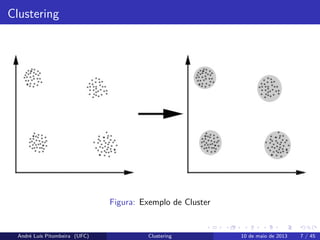
Clustering é oprocesso utilizado para examinar uma coleção de pontos e
agrupá-los em clusters de acordo com alguma medida de distância. Os
pontos que estão no mesmo cluster tem uma pequena distância uns dos
outros, enquanto pontos em diferentes cluster têm uma distância maior.
André Luís Pitombeira (UFC) Clustering 10 de maio de 2013 4 / 45
5.
Clustering
Operação sobre pontosque formam um espaço
Agrupe os elementos mais próximos
Distância é fundamental
André Luís Pitombeira (UFC) Clustering 10 de maio de 2013 5 / 45
Clustering
Espaço euclidiano
Os pontossão vetores de números reais
Distância natural
Muitas distâncias possíveis
Espaço não euclidiano
Distâncias Ad-hoc
Ex. Strings
André Luís Pitombeira (UFC) Clustering 10 de maio de 2013 8 / 45
9.
Clustering
A maldição dadimensionalidade
Espaços N-dimensionais têm propriedades que não são intuitivas.
Quase todos os pares tem a mesma distância
Todos os ângulos entre vetores são próximos a 90 graus
André Luís Pitombeira (UFC) Clustering 10 de maio de 2013 9 / 45
10.
Clustering
A maldição dadimensionalidade
(a) 2 dimensões (b) 3 dimensões
Figura: Representação de um ponto
André Luís Pitombeira (UFC) Clustering 10 de maio de 2013 10 / 45
11.
Clustering
O que podeser "clustered"?
Imagens
Items de um supermercado
Documentos
Aplicações
Data mining
Text mining
Information retrieval
André Luís Pitombeira (UFC) Clustering 10 de maio de 2013 11 / 45
12.
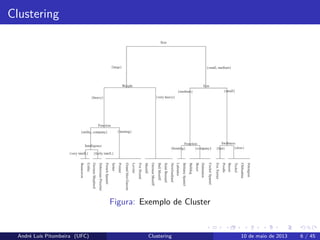
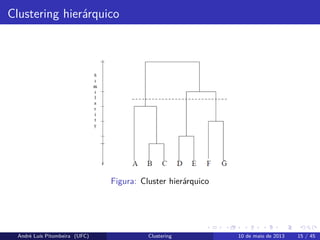
Clustering
Clustering hierárquico
Considera cadaponto como sendo um cluster e estes pontos passam a ser
combinados entre si de acordo com alguma medida de proximidade.
Atribuição de pontos
Considera os pontos em alguma ordem e cada ponto é atribuído ao cluster
que melhor se adequa.
André Luís Pitombeira (UFC) Clustering 10 de maio de 2013 12 / 45
13.
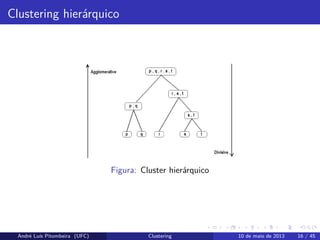
Clustering hierárquico
Aglomerativa
Abordagem "bottomup": cada observação começa em seu próprio cluster
e pares de grupos são mesclados a medida que se sobe na hierarquia.
Divisória
Abordagem "top down": todas as observações começam em um cluster e
são realizadas divisões de forma recursiva a medida que se desce na
hierarquia.
André Luís Pitombeira (UFC) Clustering 10 de maio de 2013 13 / 45
14.
Clustering hierárquico
Decida comantecedência:
Como os clusters serão representados?
Como escolheremos dois clusters para o merge?
Quando pararemos de combinar clusters?
André Luís Pitombeira (UFC) Clustering 10 de maio de 2013 14 / 45
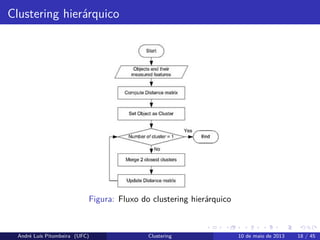
Clustering hierárquico
while isnot time to stop do
pick the best two clusters to merge;
combine those two clusters into one cluster;
end
Algorithm 1: Clustering hierárquico
André Luís Pitombeira (UFC) Clustering 10 de maio de 2013 19 / 45
20.
Clustering hierárquico
Para calculara distância entre nós do cluster utiliza-se centróides,
mas existem alternativas
Ex. distância mínima entre quaisquer dois pontos, sendo um de cada
cluster
André Luís Pitombeira (UFC) Clustering 10 de maio de 2013 20 / 45
21.
Clustering hierárquico
Espaços nãoeuclidiano
Não é possivel utilizar o centroid, pois não há o conceito de "ponto
médio"
Solução: clustroids
André Luís Pitombeira (UFC) Clustering 10 de maio de 2013 21 / 45
22.
Clustering hierárquico
String ecdababecb aecdb
abcd 5 3 3
aecdb 2 2
abecb 4
Point Sum Max Sum-sq
abcd 11 5 43
aecdb 7 3 17
abecb 9 4 29
ecdab 11 5 45
André Luís Pitombeira (UFC) Clustering 10 de maio de 2013 22 / 45
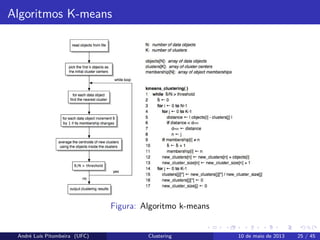
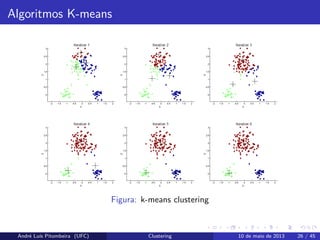
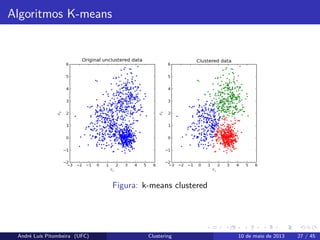
Algoritmos K-means
A famíliade algoritmos k-means é do tipo atribuição de pontos. O
algortimo assume um espaço euclidiano e um número k de clusters
conhecidos antecipadamente.
André Luís Pitombeira (UFC) Clustering 10 de maio de 2013 24 / 45
Algoritmo de Bradley,Fayyad e Reina
O algoritmo de Bradley, Fayyad e Reina (BFR) é uma variação do k-means
projetado para espaços euclidianos de alta dimensionalidade. O BRF
assume que o possui alguma restrições sobre o formato do cluster que deve
ser distribuido sobre um centroid.
André Luís Pitombeira (UFC) Clustering 10 de maio de 2013 28 / 45
29.
Algoritmo de Bradley,Fayyad e Reina
Inicialmente seleciona k pontos
Processa pedaços de dados na memória principal
Três conjuntos na memória principal
Descartados: Conjunto dos clusters
Comprimidos: Conjunto dos pontos
Retidos: Conjunto dos pontos isolados
André Luís Pitombeira (UFC) Clustering 10 de maio de 2013 29 / 45
30.
Algoritmo de Bradley,Fayyad e Reina
Processamento dos chunks dados
Pontos próximos ao centroid são adicionados ao cluster
Os outros pontos são aglomerados com o conjunto dos retidos.
Merge os "miniclusters"com o conjunto dos comprimidos
Faça alguma coisa com os pontos restantes e "miniclusters"
André Luís Pitombeira (UFC) Clustering 10 de maio de 2013 30 / 45
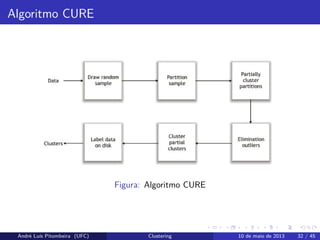
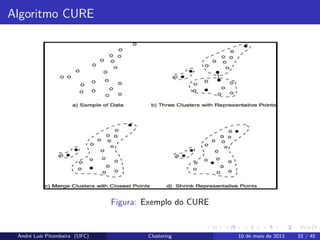
31.
Algoritmo CURE
O algoritmoCURE (Clustering Using REpresentatives) assume um espaço
euclidiano. Não assume nada a respeito do formato do cluster. Utiliza
uma coleção de pontos representativos para representar o cluster, ao invés
de utilizar o centroid.
André Luís Pitombeira (UFC) Clustering 10 de maio de 2013 31 / 45
Algoritmo CURE
Após ainicialização deve ser feito o merge dos clusters com a mínima
distância entre os pontos
Atribuir os pontos aos clusters baseado nos pontos representativos
André Luís Pitombeira (UFC) Clustering 10 de maio de 2013 34 / 45
35.
Algoritmo GRGPF
O algortimoGRGPF lida com dados que não estão na memória principal e
não assume um espaço euclidiano. A abordagem usada pelo algoritmo
utiliza ideias de ambas as abordagens hierárquica e atribuição de pontos.
Os clusters são representados por uma amostra dos pontos na memória
principal.
André Luís Pitombeira (UFC) Clustering 10 de maio de 2013 35 / 45
36.
Algoritmo GRGPF
Clusters sãorepresentados com features:
N, o número de pontos no cluster
O clustroid do cluster
Os k pontos mais próximos do clustroid
Os k pontos mais distantes do clustroid
Os clusters são organizados em uma árvore
André Luís Pitombeira (UFC) Clustering 10 de maio de 2013 36 / 45
37.
Algoritmo GRGPF
Inicialize aárvore com um algoritmo de memória principal
Nós internos mantêm umas amostra dos clustroids dos clusters
representados por sua sub árvore
Para cada ponto, atribua-o para um cluster passando-o para baixo na
árvore
Em cada nó interno procure na amostra e escolha uma sub árvore
Em uma folha, escolher o cluster com o clustroid mais próximo e
atualizar as features
André Luís Pitombeira (UFC) Clustering 10 de maio de 2013 37 / 45
38.
Algoritmo GRGPF
Conjunto dospontos mais próximos são usados para mover os
clustroids
Conjunto dos pontos mais distantes são usados para fazer o merge
dos clusters
Eventualmente, quando os clusters crescem muito deve-se fazer o split
André Luís Pitombeira (UFC) Clustering 10 de maio de 2013 38 / 45
39.
Stream
A computação domodelo de stream assume que cada elemento é um
ponto em algum espaço. Realiza-se um precluster para selecionar um
subconjunto de pontos no stream, para que consultas do tipo "quais são
os clusters dos últimos m pontos?"possam ser rapidamente respondidas.
André Luís Pitombeira (UFC) Clustering 10 de maio de 2013 39 / 45
40.
Stream
Sliding Window deN pontos
Consulta nos últimos m <= N pontos
Não assume o espaço
Clusters mudam com o passar do tempo
André Luís Pitombeira (UFC) Clustering 10 de maio de 2013 40 / 45
41.
Algoritmo DBMO
Generalização doalgoritmo DGIM
O bucket guarda o seu tamanho, o timestamp e uma coleção de
registros
Responde as consultas por fazer o merge dos buckets que cobrem os
últimos m pontos
André Luís Pitombeira (UFC) Clustering 10 de maio de 2013 41 / 45
42.
Clustering em ambientesparalelos
Map-Reduce
Na maioria dos casos apenas uma tarefa de Reduce
Map tasks
Cluster pontos
O resultado é um conjunto de pares chave-valor com uma chave
fixada em 1 e um valor que é a descrição de algum cluster.
Reduce task faz o merge dos clusters
André Luís Pitombeira (UFC) Clustering 10 de maio de 2013 42 / 45
43.
(a) Netflix (b)Google News
Figura: Empresas que desenvolveram soluções de clustering
André Luís Pitombeira (UFC) Clustering 10 de maio de 2013 43 / 45