Transferir como PDF, PPTX










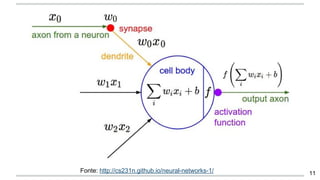
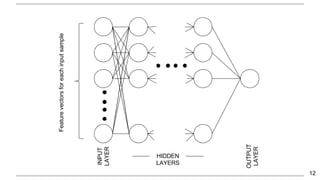


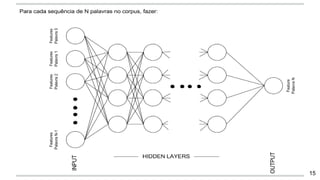
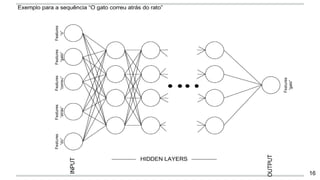



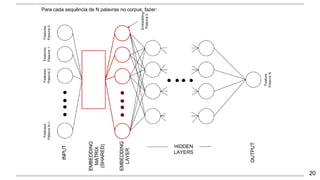




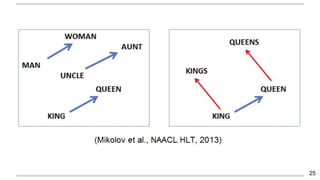
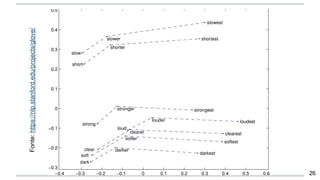

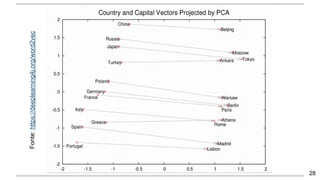




















O documento apresenta uma introdução aos word embeddings, motivando sua utilização para representar palavras de forma distribuída e de baixa dimensionalidade. Explica como os modelos de linguagem neurais treinam embeddings de forma não supervisionada e como o Word2Vec tornou esse treinamento mais eficiente através de otimizações. Finalmente, discute aplicações e trabalhos futuros com embeddings.

































![[Jose Ahirton lopes] Do Big ao Better Data](https://cdn.slidesharecdn.com/ss_thumbnails/ahirtonlopesdobigaobetterdata-190410143141-thumbnail.jpg?width=640&height=640&fit=bounds)


















