Transferir como PDF, PPTX






























![Python
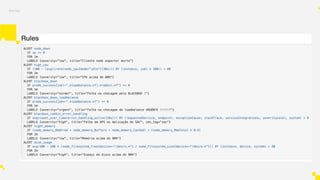
from prometheus_client import start_http_server,
Metric, REGISTRY
import json
import requests
metric = Metric('svc_requests_duration_seconds',
'Requests time taken in seconds', 'summary')
metric.add_sample('svc_requests_duration_seconds_count',
value=response['requests_handled'], labels={})
metric.add_sample('svc_requests_duration_seconds_sum',
value=response['requests_duration_milliseconds'] /
1000.0, labels={})](https://image.slidesharecdn.com/tdc2017prometheus-170721021837/85/TDC-2017-Borg-ate-o-Prometheus-Site-Reliability-Engineering-46-320.jpg)











![WebHook
Alertas
# Whether or not to notify about resolved alerts.
[ send_resolved: <boolean> | default = true ]
# The endpoint to send HTTP POST requests to.
url: <string>](https://image.slidesharecdn.com/tdc2017prometheus-170721021837/85/TDC-2017-Borg-ate-o-Prometheus-Site-Reliability-Engineering-59-320.jpg)


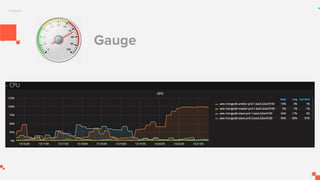
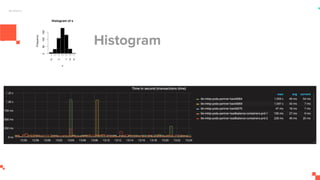
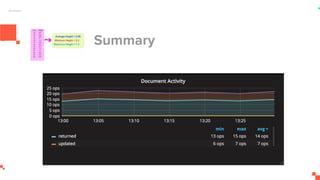
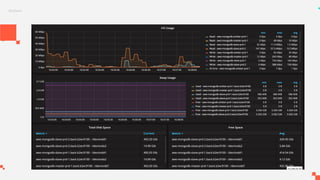
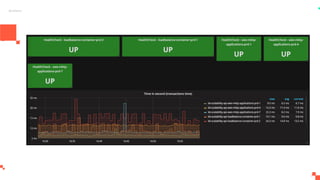
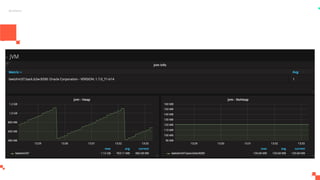
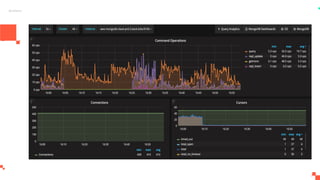
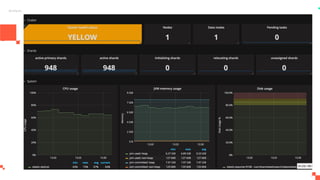

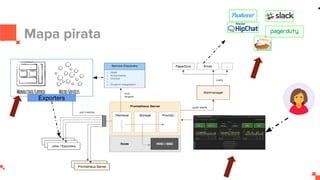





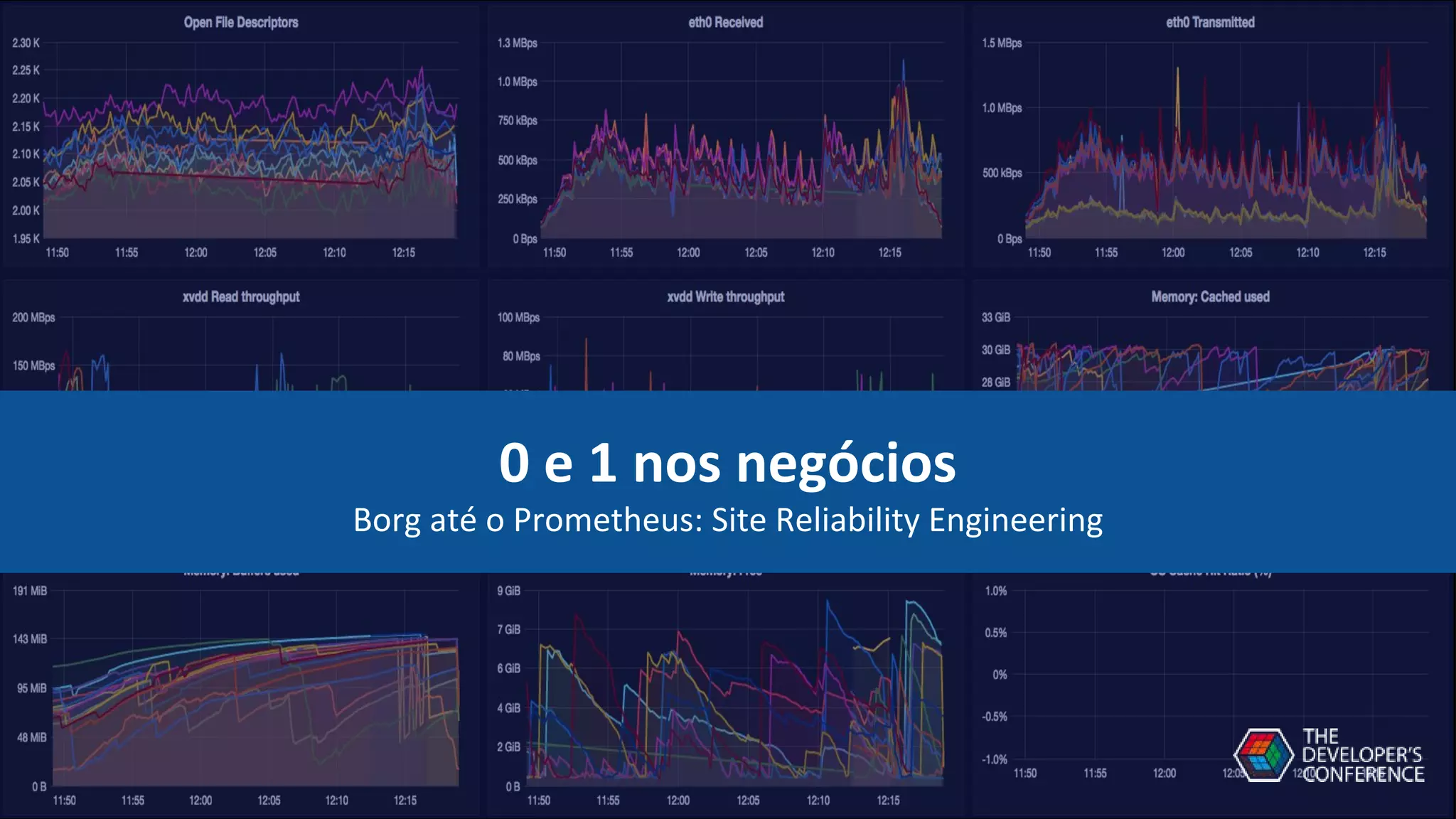
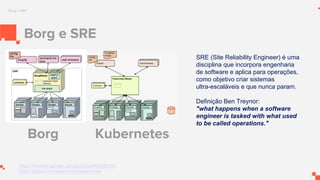
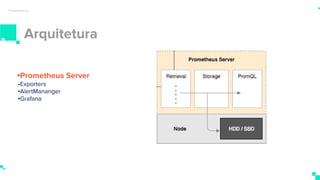
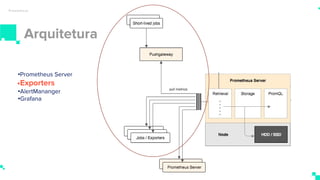
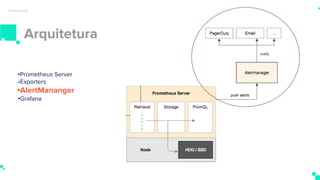
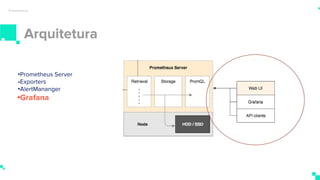
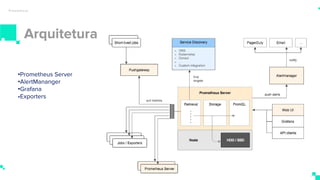
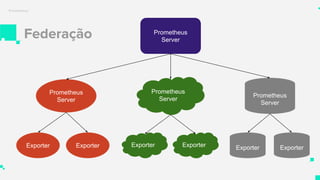
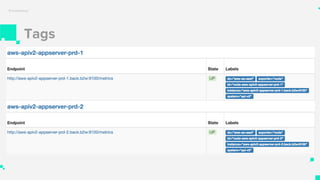
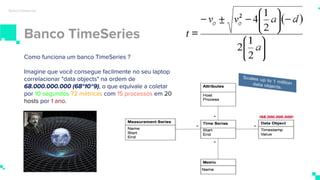
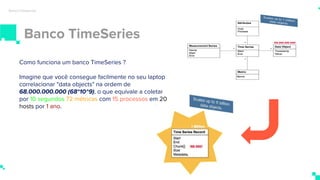
O documento apresenta um sistema de monitoramento chamado Prometheus. Ele discute a arquitetura do Prometheus, incluindo o servidor Prometheus, exportadores, AlertManager e Grafana. Também aborda conceitos como métricas, bancos de dados timeseries, instrumentação de código, push gateway e alertas.





































![[DTC21] Thiago Lima - Do Zero ao 100 no Mundo de Microservices](https://cdn.slidesharecdn.com/ss_thumbnails/0a100microservies-210317154040-thumbnail.jpg?width=640&height=640&fit=bounds)









