




















![Startup / Shutdown
23
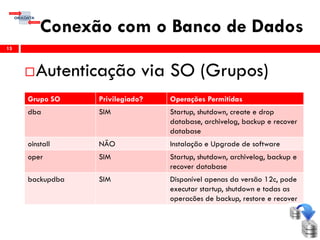
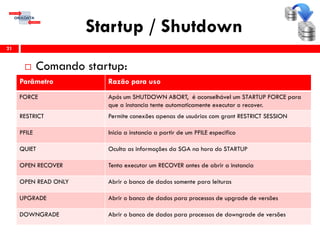
Comando shutdown:
Para que um banco de dados seja desligado de
maneira correta (sem corromper dados), é preciso
executar um shutdown “limpo”, onde se garanta que
todas as informações da memória sejam persistidas em
disco, então pode se usar alguma destas opções
IMMEDIATE, TRANSACTIONAL [LOCAL] ou NORMAL.
A opção ABORT não é recomendada! O uso desta
opção é o mesmo que desligar o cabo de energia de
seu servidor. Cuidado!!!](https://image.slidesharecdn.com/rmanworkshop12c-150723193100-lva1-app6892/85/Treinamento-RMAN-Workshop-12c-23-320.jpg)




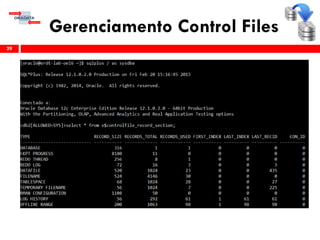


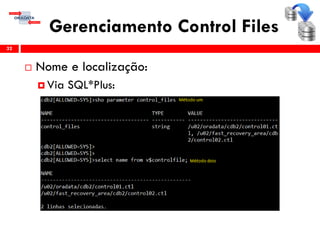




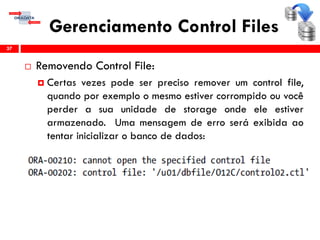


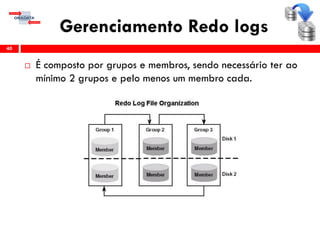
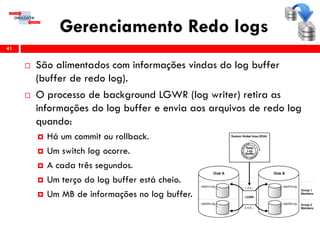
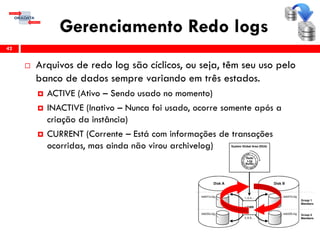










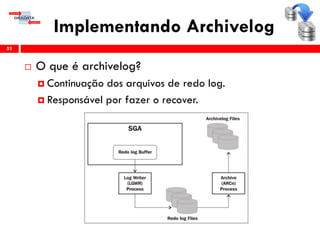







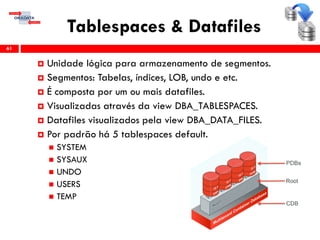



























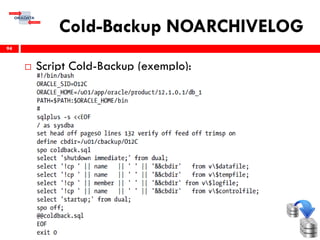










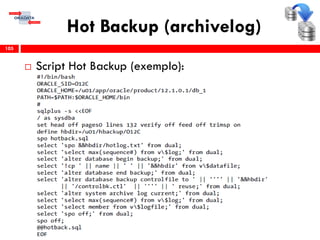
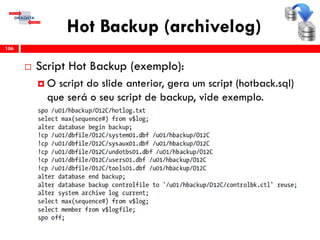



































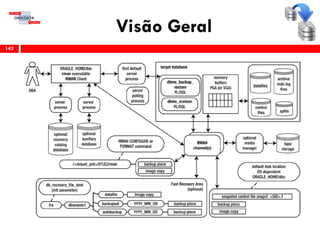















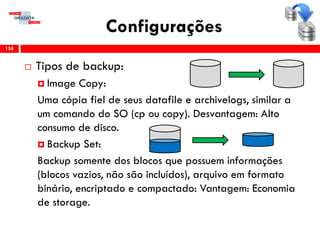












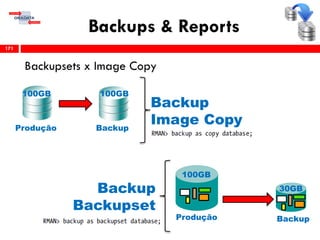
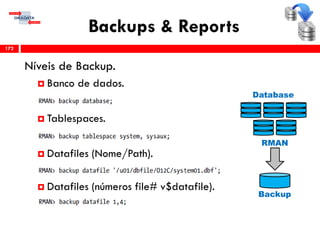














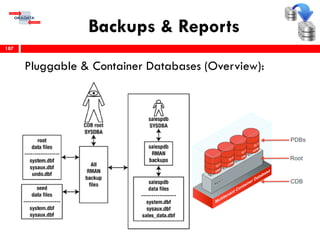


























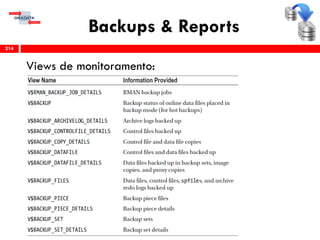










































































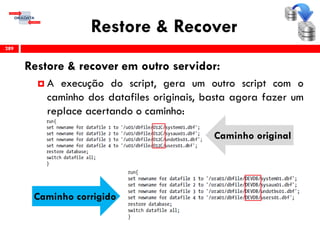












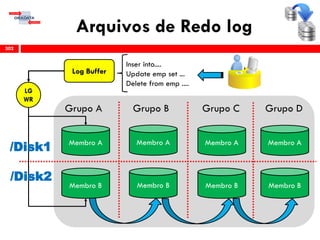



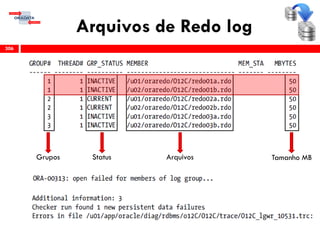




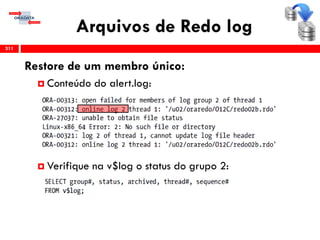

















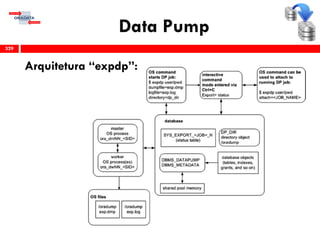
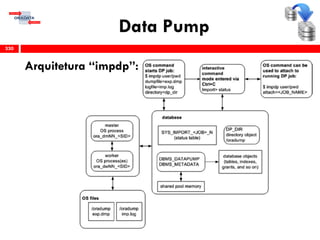




























































O workshop RMAN 12c é voltado para profissionais que desejam aprimorar seu conhecimento em gerenciamento de recuperação de banco de dados Oracle, abordando tópicos como configuração, backups, e recuperação. O conteúdo inclui variáveis de ambiente, métodos de conexão, gerenciamento de control files e redo logs, e implementação de archivelog. O instrutor é Douglas Paiva de Sousa, um especialista em Oracle.


































































