Transferir como PDF, PPTX









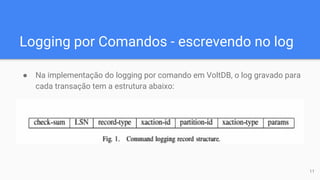








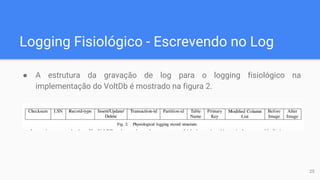




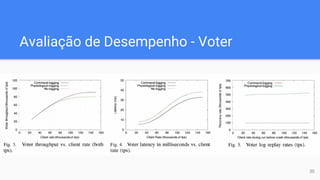
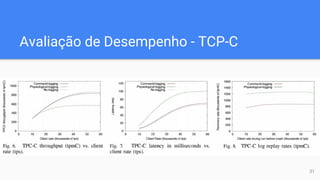



O documento discute técnicas de logging para recuperação em sistemas de banco de dados de alto desempenho (OLTP). Ele propõe o "logging por comandos", que grava apenas os comandos das transações no log, em vez de imagens completas de dados como no estilo ARIES. Os resultados experimentais mostram que o logging por comandos oferece melhor desempenho do que o logging fisiológico para sistemas OLTP, fornecendo até 1,5x mais throughput.


























































