Baixado 32 vezes













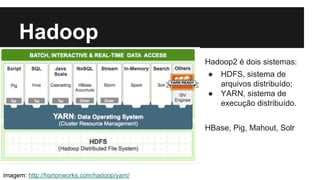
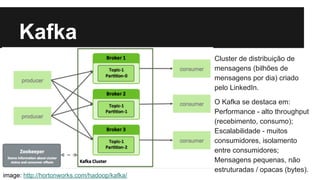
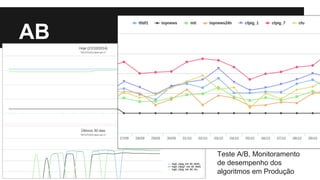
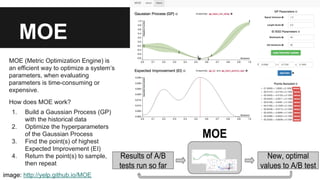






O documento apresenta a abordagem da globo.com em relação à personalização por meio de big data, destacando a importância da recomendação de conteúdo baseado no perfil do usuário. Utilizando tecnologias como Hadoop e Kafka, a globo.com busca aumentar o engajamento e a permanência dos usuários nos seus portais. Além disso, o texto ilustra como a plataforma de dados permite a consulta e o desenvolvimento de novos produtos com base na análise de grandes volumes de dados.















































