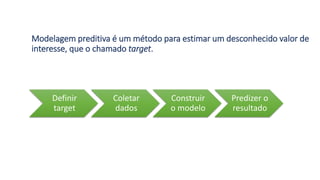
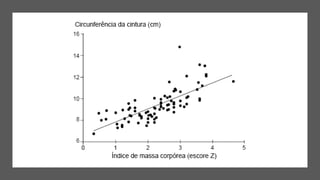
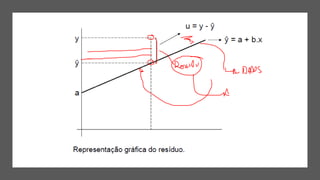
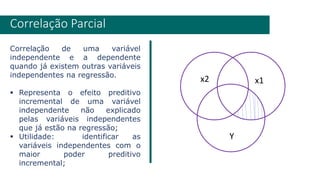
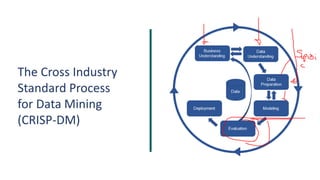
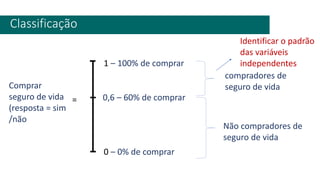
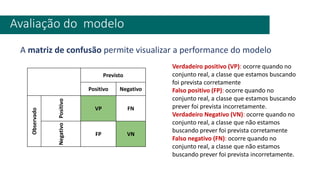
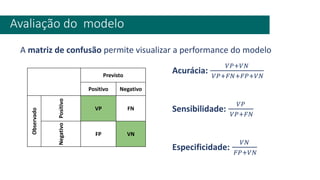
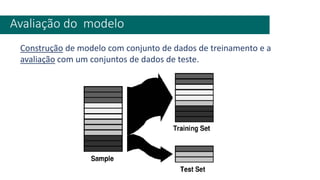
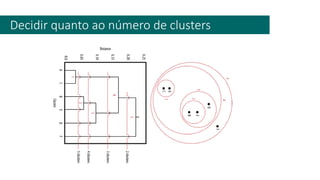
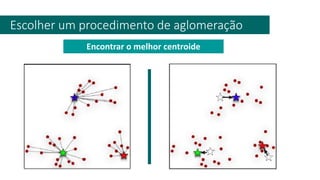
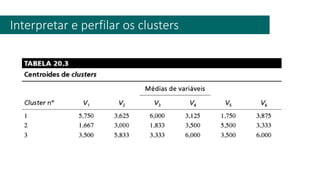
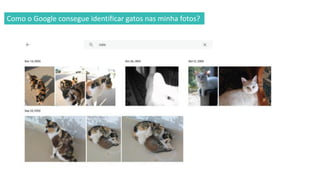
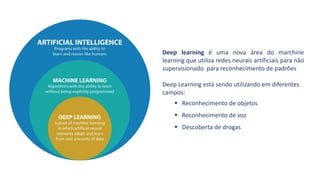
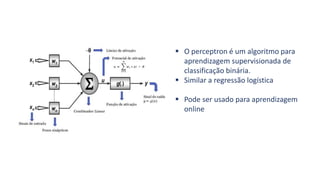
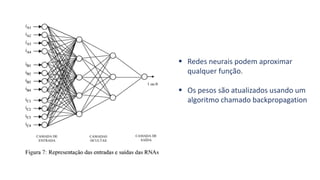
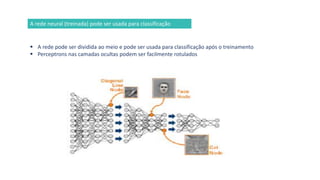
1) O documento apresenta uma introdução ao curso de Business Analytics, definindo o objetivo de capacitar os alunos a entender, modelar e resolver problemas de negócios usando técnicas estatísticas no R.
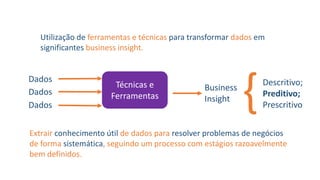
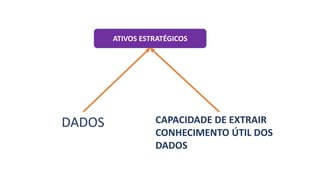
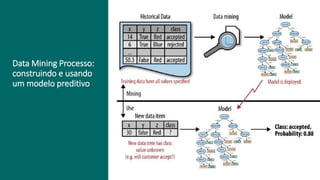
2) Business Analytics envolve transformar dados em insights valiosos para os negócios através de ferramentas e técnicas estatísticas. Inclui domínios como marketing, clientes, processos e cadeia de suprimentos.
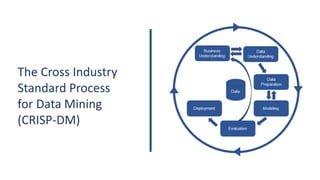
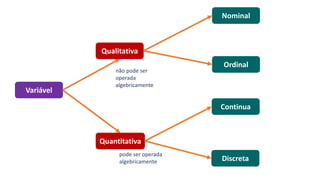
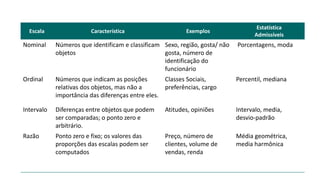
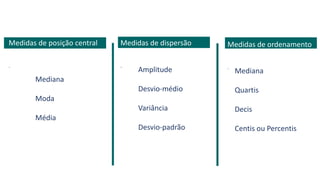
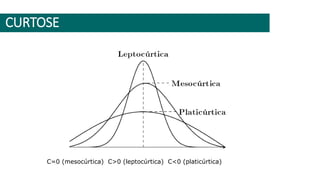
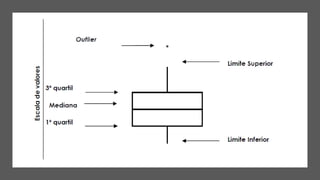
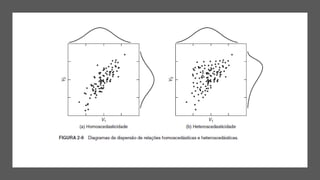
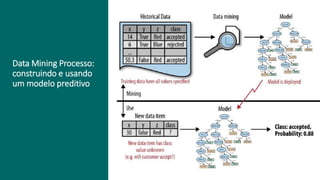
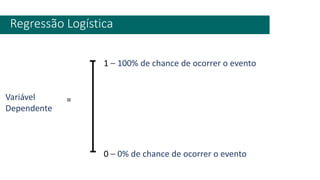
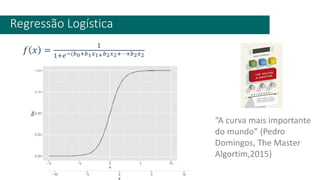
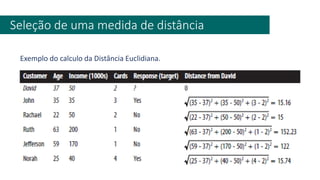
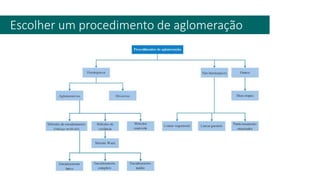
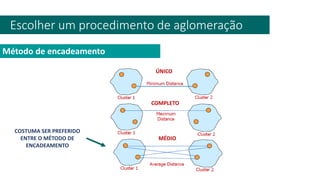
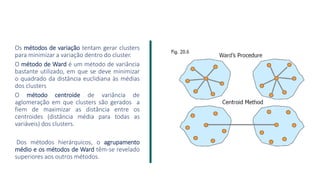
3) A análise de dados requer entendimento de conceitos como ciência de dados, estr